Programming environment
CUDA includes runtime libraries:
- Common part with built-in vector types and RTL subsets, supported by CPU and GPU
- CPU-component to control one or several GPUs
- GPU-component with specific GPU functions.
The main CUDA process works on a general-purpose processor (host), it starts several copies of kernel processes on a graphics card. CPU code does the following: it initializes a GPU, distributes video and system memory, copies constants into video memory, starts several copies of kernel processes on a graphics card, copies results from video memory, frees memory, and shuts down.
Here is an example of CUDA code for CPU that adds vectors:
Functions executed by a GPU have the following limitations: no recursion, no static variables inside functions or variable number of arguments. Two memory management types are supported: linear memory with access by 32-bit pointers, and CUDA-arrays with access only through texture fetch functions.
CUDA-enabled programs can interact with graphics APIs: to render data generated in a program, to read rendering results and to process them with CUDA functions (for example, post processing filters). Resources of graphics API can be displayed (obtaining resource addresses) in global CUDA memory. The following resource types of graphics APIs are supported: Buffer Objects (PBO / VBO) in OpenGL, vertex buffers and textures (2D, 3D, and cubic maps) in Direct3D9.
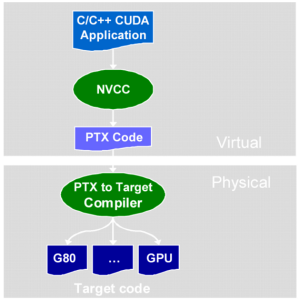
Compile stages of a CUDA application:
Files of the source CUDA C code are compiled with NVCC, which is just a shell to other tools: cudacc, g++, cl, etc. NVCC generates: CPU code, which is compiled together with other parts of the application, written in pure C, and PTX object code for GPU. Executable files with CUDA code require CUDA runtime library (cudart) and CUDA core library (cuda).
Optimizing CUDA applications
A single article certainly cannot cover serious issues of CUDA programming optimizations. So we'll just touch upon basic things. In order to use CUDA effectively, you should forget about usual programming methods for CPU programs. Use algorithms that can run in thousands of threads. It's also important to find an optimal place to store data (registers, shared memory, etc), minimize data exchange between CPU and GPU, use buffering.
In outline, when you optimize a CUDA application, you should try to achieve an optimal balance between the size and number of blocks. More threads in a block reduce the effect of memory latencies, but it will also reduce the number of available registers. Besides, a block of 512 threads is inefficient. NVIDIA recommends using blocks of 128 or 256 threads as a compromise value to reach optimal latencies and number of registers.
Key optimizations for CUDA applications: use shared memory as much as possible,because it's much faster than global video memory; operations of reading and writing from global memory must be coalesced, if possible. For this purpose you should use special data types to read and write 32/64/128 bits in a single operation. If it's difficult to coalesce read operations, you may try to use texture lookups.
Conclusions
NVIDIA CUDA architecture for GPU computing is a good solution for a wide circle of parallel tasks. CUDA works with many NVIDIA processors. It improves the GPU programming model, making it much simpler and adding a lot of features, such as shared memory, thread syncing, double precision, and integer operations.
CUDA technology is available to every software developer, any C programmer. They just have to get used to a different paradigm of programming for parallel computing. If an algorithm runs well in parallel, your efforts to apply CUDA will be rewarded.
Development of parallel GPU computing may have a strong effect on high-performance computing industry, as graphics cards are widely spread all over the world. These features have already aroused much interest in scientific circles, and not only there. There are not so many chances to accelerate parallel algorithms (with the existing hardware, which is also very important) by dozens of times.
CPUs are developing rather slowly, they are not capable of such performance leaps. In fact, everybody in need of fast processors can now get an inexpensive personal supercomputer, sometimes even without investing extra money, as graphics cards from NVIDIA are widely spread. To say nothing of higher efficiency in terms of GFLOPS/$ and GFLOPS/W, treasured so much by GPU makers.
The future of many computations apparently belongs to parallel algorithms, almost all new solutions and initiatives go that way. As for now, development of new paradigms is only at the initial stage. Programmers have to create threads manually and plan memory access, which complicates the task in comparison with usual programming. But CUDA technology has made a step in the right direction. It will apparently become a successful solution, especially if NVIDIA manages to attract as many developers as possible.
But GPUs cannot replace CPUs, of course. They are not designed for this task in their present form. Graphics processors are currently moving towards CPUs, becoming more general in their design (floating-point computing, single and double precision, integer computing). And CPUs are also getting more "parallel", obtaining more cores, multiprocessing technologies, to say nothing of SIMD units and projects of heterogeneous processors. GPUs and CPUs may merge in future. We know that many companies, including Intel and AMD, are working on such projects. It does not matter whether GPUs will merge into CPUs or vice versa.
This article mostly touched upon CUDA advantages. But there is a fly in the ointment. One of few shortcomings of CUDA is its weak portability. This architecture works only with some GPUs from this company -- starting from GeForce 8 and 9, and Quadro/Tesla. OK, there are a lot of such solutions all over the world -- it's about 90 million CUDA-compatible GPUs according to NVIDIA. That's great, but there are also competing products incompatible with CUDA. For example, AMD offers Stream Computing, Intel will have Ct.
Only time will tell which technology will prevail. But CUDA has good chances. Unlike Stream Computing, it offers a more developed and convenient programming environment -- the usual C language. Perhaps, the third party will offer a common solution. For example, Microsoft DirectX 11 promises computing shaders, which may become an aggregate solution to please all sides, or almost all.
Judging by preliminary data, this new type of shaders borrows much from CUDA. Programming in this environment now allows to get an immediate advantage and necessary skills for the future. DirectX has an apparent shortcoming from the point of view of high-performance computing. It's weak portability, as this API is limited to Windows only. However, another standard is being developed now -- open multiplatform initiative OpenCL, which is supported by most companies, such as NVIDIA, AMD, Intel, IBM, and many others.
Don't forget that the next article about CUDA will analyze practical applications of scientific and other non-graphics computations, developed all over the world with NVIDIA CUDA.
Write a comment below. No registration needed!