CUDA advantages and limitations
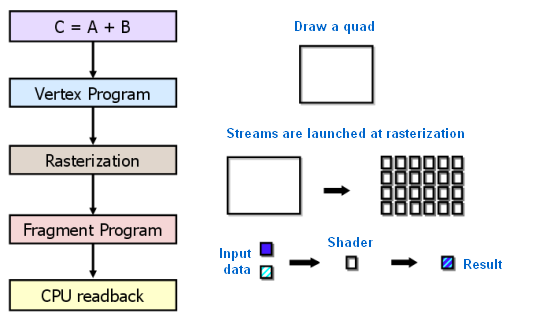
From the point of view of a programmer, a graphics pipeline is a set of processing stages. Geometry unit generates triangles, and a raster unit generates pixels displayed on your monitor. The traditional GPGPU programming model looks like this:
A special approach is required to move computations to a GPU according to this model. Even elementwise addition of two vectors will require drawing a figure on screen or to an off-screen buffer. A figure is rasterized, the color of each pixel is calculated by a given program (pixel shader). The program reads input data from textures for each pixel, adds them, and records them to an output buffer. And all these multiple operations do what a single operator can do in a usual programming language!
So GPGPU usage for general-purpose computations is limited due to its steep learning curve. There are also other limitations -- a pixel shader is just a formula describing how a resulting pixel color depends on its coordinates. And the language of pixel shaders just records these formulas with C-like syntax. Early GPGPU methods are a cunning trick to use the power of GPU, but they are not convenient. Data are represented by images (textures), and an algorithm is a raster process. We should also note a specific model of memory and execution.
Firmware architecture for GPU computing from NVIDIA differs from previous GPGPU models -- it allows to write programs for GPU on the C language with the standard syntax, markers, and minimum extensions to access computing resources of GPUs. CUDA does not depend on graphics APIs and possesses some peculiarities for general-purpose computing.
Advantages of CUDA over the traditional approach to GPGPU computing:
- Programming interface of CUDA applications is based on the standard C language with extensions, which facilitates the learning curve of CUDA
- CUDA provides access to 16 KB of memory (per multiprocessor) shared between threads, which can be used to setup cache with higher bandwidth than texture lookups
- More efficient data transfers between system and video memory
- No need in graphics APIs with their redundancy and overheads
- Linear memory addressing, gather and scatter, writing to arbitrary addresses
- Hardware support for integer and bit operations
Main limitations of CUDA:
- No recursive functions
- Minimum unit block of 32 threads
- Closed CUDA architecture, it belongs to NVIDIA.
What concerns weaknesses of old GPGPU methods, they did not use vertex shader units in previous non-unified architectures. Data were stored in textures and output to an off-screen buffer, and multi-pass algorithms used pixel shader units. GPGPU limitations include: insufficiently effective utilization of hardware features, memory bandwidth limitations, no scatter (only gather), mandatory graphics API.
The key advantages of CUDA versus older GPGPU methods result from the fact that the architecture is designed for efficient usage of non-graphics GPU computations and uses the C programming language. It does not require converting algorithms into a pipe-like format. CUDA offers a new way of GPU computing that does not use graphics APIs, it provides random memory access (scatter or gather). This architecture does not suffer from GPGPU problems and uses all execution units. It also expands functionality owing to integer arithmetics and bitshift operations.
Besides, CUDA opens some hardware features, which were not available from graphics APIs, such as shared memory. It's a small volume of memory (16 KB per multiprocessor), which can be accessed by thread blocks. It allows to cache the most frequently used data and can provide higher performance for this task than texture lookups. In its turn, it reduces sensitivity to throughput of parallel algorithms in many applications. For example, it's useful for linear algebra, fast Fourier transformation, and image processing filters.
CUDA also offers more convenient access to memory. Program code in graphics APIs outputs data in the form of 32-bit floating-point values of single precision (RGBA values into eight render targets simultaneously) into predefined areas. And CUDA supports scatter -- unlimited number of values written to any addresses. Such advantages allow GPUs to execute some algorithms, which cannot be effectively implemented with GPGPU methods based on graphics APIs.
Besides, graphics APIs must store data in textures, which requires preliminary packing of large arrays into textures. This will complicate the algorithm and force programmers to use special addressing. CUDA allows to read data at any address. Another advantage of CUDA is optimized data exchange between CPU and GPU. If developers want to get access to low level programming (for example, a different programming language), CUDA offers assembler.
CUDA history
CUDA project was announced together with G80 in November, 2006. Public beta version of CUDA SDK was released in February, 2007. Version 1.0 was timed to the rollout of Tesla solutions in June, 2007, based on G80 and designed for the market of high performance computing. Later on, at the end of the year came CUDA 1.1 beta, which added new features even though it was a minor release.
CUDA 1.1 introduced CUDA functions to usual NVIDIA drivers. That is any CUDA program required only a graphics card from GeForce 8 series or newer and Version 169.xx of the drivers or higher. It's very important for developers. These conditions allow to run CUDA programs on any computer. Besides, there appeared asynchronous execution with data copying (only for G84, G86, G92 and higher), asynchronous data transfer to video memory, atomic operations of memory access, support for 64-bit Windows versions, and multi-GPU CUDA operation in SLI mode.
The latest version is developed for GT200 -- CUDA 2.0 was released together with GeForce GTX 200. Its beta version appeared back in spring, 2008. The second version added the following: support for double precision (hardware support only in GT200), finally support for Windows Vista (32- and 64-bit versions) and Mac OS X, debuggers and profilers, 3D texture support, optimized data transfers.
What concerns double precision, its performance is several times as slow as single precision with the latest hardware generation. We touched upon the reasons in our baseline GeForce GTX 280 review. This support in GT200 consists in not using FP32 units to obtain results four times as slowly. NVIDIA decided to add dedicated units to support FP64. There are ten times as few of them as FP32 units in GT200 (one double-precision unit per each multiprocessor).
Their actual performance may be even lower, because the architecture is optimized for 32-bit reading from memory and registers. Besides, double precision is not necessary in graphics applications, GT200 has this support just for the sake of appearance. Moreover, performance of modern quad-core processors is not much lower. Even being ten times as slow as single precision, this support is useful for projects with mixed precision. One of popular techniques is to obtain results, initially close to single precision, and then redefine them for double precision. Now it can be done right in a graphics card without sending intermediate results to a CPU.
Oddly to say, another useful feature of CUDA 2.0 has nothing to do with GPUs. Now it's just possible to compile CUDA code into highly efficient multi-threaded SSE code for fast execution on a CPU. That is now this feature works not only for debugging, but also for real usage on computers without a graphics card from NVIDIA. CUDA usage in usual code is limited by NVIDIA cards, which are not installed in all computers. In such cases developers would have to generate two code versions prior to Release 2.0: for CUDA and for CPU. And now it's possible to execute any CUDA program on a CPU with high efficiency, even if at lower speed than on GPUs.
Write a comment below. No registration needed!