CUDA programming model
I repeat, CUDA uses parallel computing model, when each of SIMD processors executes the same instruction over different data elements in parallel. GPU is a computing device, co-processor (device) for a CPU (host), possessing its own memory and processing a lot of threads in parallel. A kernel is a GPU function executed by threads (it's like a shader in 3D graphics terms).
As we have already mentioned above, a GPU differs from a CPU in its ability to process dozens of thousands of threads simultaneously -- nothing extraordinary for graphics, which can be easily processed in parallel. Each thread is scalar, it does not require packing data into 4-component vectors, which is more convenient for most tasks. The number of logical threads and thread blocks surpasses the number of physical execution units, which gives good scalability for the entire model range.
CUDA programming model implies grouping threads. Threads unite into thread blocks -- one- or two-dimensional grids of threads that interact with each other via shared memory and synchpoints. A program (kernel) is executed over a grid of thread blocks, see the picture below. One grid is executed at a time. Each block can be one-, two-, or three-dimensional in form, and it may consist of 512 threads with the current hardware.
Thread blocks are executed in the form of small groups called warps (32 threads each). It's minimum volume of data, which can be processed by multiprocessors. As it's not always convenient, CUDA allows to work with blocks containing 64-512 threads.
Grouping blocks into grids helps avoid the limitations and apply the kernel to more threads per call. It also helps in scaling. If a GPU does not have enough resources, it will execute blocks one by one. Otherwise, blocks can be executed in parallel, which is important for optimal distribution of the load on GPUs of different levels, starting from mobile and integrated solutions.
CUDA memory model
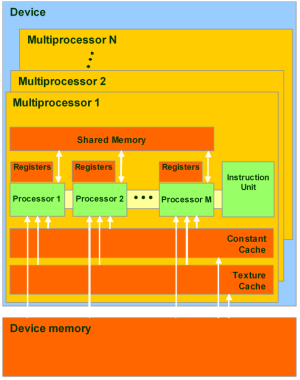
CUDA memory model allows bytewise addressing, support for gather and scatter. There are quite a lot of registers per each streaming processor, up to 1024. Access to these registers is very fast, they can store 32-bit integer or floating-point numbers.
Each thread has access to the following memory types:
Global memory -- the largest volume of memory available to all multiprocessors in a GPU, from 256 MB to 1.5 GB in modern solutions (and up to 4 GB in Tesla). It offers high bandwidth, over 100 GB/s for top solutions from NVIDIA, but it suffers from very high latencies (several hundred cycles). Non-cacheable, supports general load and store instructions, and usual pointers to memory.
Local memory -- small volume of memory, which can be accessed only by one streaming processor. It's relatively slow, just like global memory.
Shared memory -- 16-KB memory (in graphics processors of the state-of-the-art architecture) shared between all streaming processors in a multiprocessor. It's fast memory, just like registers. This memory provides interaction between threads, it's controlled by developers directly and features low latencies. Advantages of shared memory: it can be used as a controllable L1 Cache, reduced latencies when ALUs access data, fewer calls to global memory.
Constant storage -- memory area of 64 KB (the same concerns modern GPUs), read only for all multiprocessors. It's cached by 8 KB for each multiprocessor. This memory is rather slow -- latencies of several hundred cycles, if there are no required data in cache.
Texture memory is available for reading to all multiprocessors. Data are fetched by texture units in a GPU, so the data can be interpolated linearly without extra overheads. Cached by 8 KB for each multiprocessor. Slow as global memory -- latencies of several hundred cycles, if there are no required data in cache.
It goes without saying that global, local, texture, and constant memory is physically the same memory aka local video memory of a graphics card. They differ only in caching algorithms and access models. CPU can refresh and access only external memory: global, constant, and texture memory.
All of the above shows that CUDA implies a special approach to development, slightly different from CPU programming. You must be mindful of different memory types, of the fact that local and global memory is not cached and that their access latencies are much higher than in register memory, as it's physically located in separate chips.
Typical, but not mandatory template:
- Split a task into subtasks
- Divide input data into chunks that fit shared memory
- Each data chunk is processed by a thread block
- Load a data chunk from global memory into shared memory
- Process data in shared memory
- Copy results from shared memory back to global memory
Write a comment below. No registration needed!