First attempts to use GPUs for computing
Developers tried to use GPUs for parallel computing long ago. The very first attempts of such usage were primitive. They were limited to using some hardware functions, such as rasterizing and Z-buffering. But with the appearance of shaders, they started to accelerate matrix calculations. Back in 2003 a separate section was set up at SIGGRAPH dedicated to GPU computing. It was named GPGPU (General-Purpose computation on GPU).
The most known title here is BrookGPU -- compiler of streaming programming language Brook, created for non-graphics computing with GPUs. Before this compiler was released, developers had to choose between two popular APIs: Direct3D or OpenGL. It seriously limited GPU applications, because 3D graphics use shaders and textures, which parallel programmers shouldn't know about, they just use threads and cores. Brook facilitated that task. These streaming extensions to language C, developed in Stanford University, concealed the 3D API from programmers and represented a GPU as a parallel co-processor. The compiler processed a .br file with C++ code and extensions, generating code linked to a library supporting DirectX, OpenGL, or x86.
Brook had lots of shortcomings, of course. We mentioned them before, and we'll touch upon them below. But its appearance attracted much attention of NVIDIA and ATI to the GPU computing initiative, because development of these features seriously changed market future by opening a new segment -- GPU-assisted parallel computing.
Later on, some Brook developers joined NVIDIA to present firmware strategy of parallel computing in a new market segment. And the main advantage of this initiative from NVIDIA is that developers know well all ins and outs of their GPUs, and there is no need to use graphics API. They can work with hardware directly with the help of a driver. This team came up with NVIDIA CUDA (Compute Unified Device Architecture) -- a new firmware architecture for parallel computing with NVIDIA GPUs. This article will be devoted to this product.
Applications of parallel GPU computing
In order to understand advantages of GPU-assisted computing, we publish average numbers obtained by researchers all over the world. The average performance gain from using GPU computing in many tasks reaches 5-30 times versus fast CPUs. The biggest numbers (about 100-fold performance gains or higher!) are obtained with code, which does not compute well with SSE, but suites GPUs.
These are just a few examples of GPU-accelerated synthetic code versus SSE-vectorized code on CPUs (according to NVIDIA):
- Fluorescence microscopy: 12x
- Molecular dynamics (non-bonded force calc): 8-16x
- Electrostatics (direct and multi-level Coulomb summation): 40-120x and 7x.
NVIDIA just loves the following table. The company demonstrates it at all presentations. We'll analyze it in the second part of the article devoted to some CUDA applications:
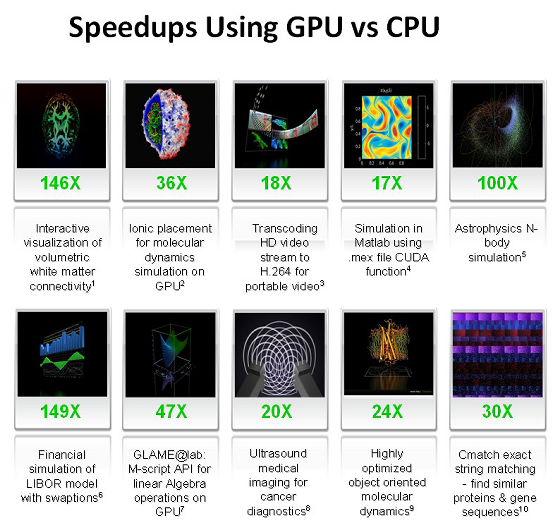
As you can see, these are quite attractive numbers, especially 100-150-fold gains. We'll thoroughly analyze some of these numbers in the next article about CUDA. And now we'll list the key applications that use GPU computing now: image and signal analysis and processing, physics simulation, computing mathematics, computing biology, financial calculations, databases, gas and fluid dynamics, cryptography, adaptive X-ray therapy, astronomy, sound processing, bio-informatics, biological simulations, computer vision, data mining, digital cinema and television, electromagnetic simulations, geoinfo systems, military applications, mountain planning, molecular dynamics, magnetic resonance imaging (MRI), neuron networks, oceanographic research, particle physics, protein agglutination simulation, quantum chemistry, ray tracing, visualization, radars, reservoir simulation, artificial intelligence, satellite data analysis, seismic prospecting, surgery, ultrasound, video conferencing.
You can read about many applications at NVIDIA's web site, on the page about CUDA technology. As you can see, the list is rather long, but it's not complete! A lot can be added to this list. We assume that other applications for parallel GPU computing will be found.
NVIDIA CUDA features
CUDA technology is a software-hardware computing architecture from NVIDIA, based on the extension of the C programming language, which provides access to GPU instructions and video memory control for parallel computations. CUDA allows to implement algorithms that can be executed by GPUs installed in GeForce 8 cards or newer (GeForce 8, GeForce 9, GeForce 200), as well as Quadro and Tesla.
Programming GPUs with CUDA is quite toilful, it's still easier than with early GPGPU solutions. Such programs must be distributed between several multiprocessors like in MPI programming, but without dividing data stored in shared video memory. As CUDA programming is similar to OpenMP programming for each multiprocessor, it requires good understanding of memory organization. But complexity of development and migration to CUDA depends much on a given application.
Well-documented development kit contains a lot of code samples. The learning curve requires about two-four weeks for those who are already familiar with OpenMP and MPI. This API is based on extended C language. CUDA SDK includes a command line compiler nvcc, based on the open compiler Open64.
Here are the key characteristics of CUDA:
- Unified firmware solution for parallel computing with NVIDIA GPUs
- Lots of supported solutions, from mobile to multi-chip ones
- Standard C programming language
- Standard libraries of FFT (fast Fourier transformation) and BLAS (linear algebra)
- Optimized data exchange between CPUs and GPUs
- Interaction with graphics APIs -- OpenGL and DirectX
- Support for 32- and 64-bit operating systems: Windows XP, Windows Vista, Linux, and MacOS X
- Low-level development.
What concerns support for operating systems, we should add about official support for all main Linux packages (Red Hat Enterprise Linux 3.x/4.x/5.x, SUSE Linux 10.x). But according to enthusiasts, CUDA works fine in other Linux versions: Fedora Core, Ubuntu, Gentoo, etc.
CUDA Toolkit includes:
- nvcc compiler
- FFT and BLAS libraries
- profiler
- gdb debugger for GPU
- CUDA runtime driver is included into the standard NVIDIA driver
- Programming Guide
- CUDA Developer SDK (source code, utilities, and documentation).
Source code samples: bitonic sort, matrix transposing, parallel prefix summation of large arrays, image convolution, discrete wavelet transform, example of interaction with OpenGL and Direct3D, CUBLAS and CUFFT library usage, option price calculation (Black- Scholes formula, binomial model, Monte-Carlo method), parallel random-number generator Mersenne Twister, computing histograms of large arrays, noise reduction, Sobel filter (edge detection).
Write a comment below. No registration needed!















