Solutions supporting NVIDIA CUDA
All graphics cards supporting CUDA can help accelerate most difficult tasks, starting from audio and video processing to medicine and scientific research. The only real limitation is that many CUDA programs require at least 256 MB of video memory, and it's one of the most important technical characteristics for CUDA applications.
You can read the latest list of products with CUDA support on NVIDIA's web site. At the time this article was written, CUDA was supported by all GeForce 200, GeForce 9, and GeForce 8 products, including mobile products, starting from GeForce 8400M, as well as chipsets -- GeForce 8100, 8200, and 8300. CUDA is also supported by modern Quadro products and all Tesla ones: S1070, C1060, C870, D870, and S870.
The new GeForce GTX 260 and 280 graphics cards were announced together with corresponding solutions for high performance computing: Tesla C1060 and S1070 (on the photo above), which will appear in stores in Autumn. They use the same GPU -- GT200, one in the C1060, four in the S1070. Unlike gaming solutions, they use four gigabytes of memory per GPU. What concerns drawbacks, we can mention only lower memory frequency and bandwidth than in gaming cards, 102 GB/s per chip.
NVIDIA CUDA
CUDA includes two APIs: high-level (CUDA Runtime API) and low-level (CUDA Driver API), although one program cannot use both of them simultaneously, either one or another. The high-level API works on top of the low-level one, all runtime calls are translated into simple instructions processed by the low-level Driver API. But even the high-level API requires knowledge about NVIDIA GPUs, it lacks a high abstraction level.
There is another, even higher level -- two libraries:
CUBLAS -- CUDA version of BLAS (Basic Linear Algebra Subprograms) for linear algebra tasks, which uses direct access to GPU resources.
CUFFT -- CUDA version of Fast Fourier Transform library, which is widely used for signal processing. The following transform types are supported: complex-complex (C2C), real-complex (R2C), and complex-real (C2R).
Let's take a closer look at these libraries. CUBLAS -- standard linear algebra algorithms, translated to CUDA, only a certain bundle of main CUBLAS functions is supported now. This library is very easy to use: just create a matrix and vector objects in video memory, fill them with data, call necessary CUBLAS functions, and load results from video memory back into system memory. CUBLAS contains special functions to create and destroy objects in GPU memory as well as to read and write data into video memory. Supported BLAS functions: Level 1, 2, and 3 for real numbers, Level 1 CGEMM for complex numbers. Level 1 is vector-vector operations, Level 2 -- vector-matrix operations, Level 3 -- matrix-matrix operations.
CUFFT is a CUDA version of fast Fourier transformation, widely used and very important for signal analysis, filtering, etc. CUFFT offers a simple interface for efficient FFT computing on NVIDIA GPUs without the need to develop your own FFT version for GPU. CUDA FFT supports 1D, 2D, and 3D transforms of complex and real data, batch execution of several 1D transforms in parallel, the size of 2D and 3D transforms may be within [2, 16384], up to eight million elements are supported for 1D.
CUDA development basics
In order to understand the text below, you should know basic architectural peculiarities of NVIDIA GPUs. GPU consists of several Texture Processing Clusters. Each cluster consists of a large block of texture fetch units and 2-3 streaming multiprocessors, each of them comprising eight computing units and two superfunctional units. All instructions are executed by the SIMD principle, when one instruction is applied to all threads in warp (it's a term from textile industry, in CUDA it means a group of 32 threads -- minimum data volume processed by multiprocessors). This execution method is called SIMT (single instruction multiple threads).
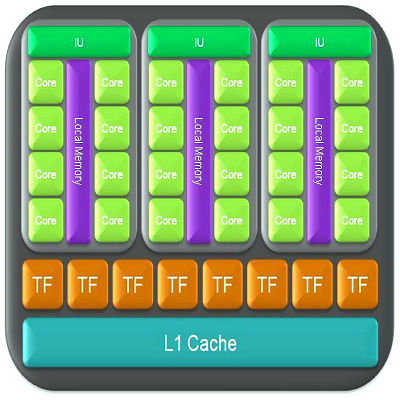
Each multiprocessor has certain resources. For example, special shared memory (16 KB) is available to each multiprocessor. But it's not cache, as programmers may use it for any needs, like Local Store in SPU of Cell processors. This shared memory allows to exchange data between threads of a single block. What's important, all threads of a single block are always executed by the same multiprocessor. Threads from different blocks cannot exchange data between each other, you must keep this limitation in mind. Shared memory is often useful, except those cases when several threads access the same memory bank. Multiprocessors can access video memory as well, but it involves high latencies and worse throughput. To accelerate memory access and reduce the frequency of video memory calls, each multiprocessor has 8 KB of cache for constants and texture data.
A multiprocessor uses 8192-16384 (for G8x/G9x and GT2xx correspondingly) registers, common for all threads of all blocks, executed by this multiprocessor. The maximum number of blocks per multiprocessor for G8x/G9x equals eight, 24 warps (768 threads per multiprocessor). All in all, top graphics cards from GeForce 8 and 9 series can process up to 12288 threads simultaneously. GeForce GTX 280 based on GT200 offers up to 1024 threads per multiprocessor. It has ten clusters, three multiprocessors each, processing up to 30720 threads. If you know these limitations, it will help you optimize algorithms for available resources.
The first step to migrate an existing application to CUDA is its profiling and determining bottlenecks in code. If such bottlenecks can be executed in parallel, these functions are translated to the C extensions of CUDA to be executed on GPU. A program is compiled with NVIDIA compiler, which generates code both for CPU and GPU. When a program is executed by a CPU, it executes its parts of code, and GPU executes CUDA code with the heaviest parallel computations. The GPU part is called a kernel. The kernel determines operations to be performed over data.
A graphics chip gets the kernel and creates copies for each data element. These copies are called threads. A thread contains a counter, registers, and a state. Million threads are generated for large volumes of data, such as image processing. Threads are executed in groups of 32, called warps. Warps are assigned to certain streaming multiprocessors. Each multiprocessor consists of eight cores -- streaming processors that execute one MAD instruction per cycle. A single 32-thread warp requires four cycles of a multiprocessor (we speak of shader domain frequency, 1.5 GHz and higher).
A multiprocessor is not a traditional multi-core processor, it's designed for multi-threaded operation supporting up to 32 warps simultaneously. Hardware chooses which warp to execute each cycle, and it switches between them without penalties. If we compare with CPUs, it's similar to simultaneous execution of 32 programs and switching between them each cycle without penalties. CPU cores can actually execute only one program at a time, and switching to other programs costs hundreds of cycles.
Write a comment below. No registration needed!


















