 |
||
|
||
| ||
|
||
|
||
| ||
IntroductionDevices to turn PCs into small supercomputers have been known for a long times already. Back in the 1980s the market offered so-called transputers to be installed into ISA expansion slots. At first their performance was impressive in certain applications. But then performance of general-purpose processors started to grow faster, they became stronger in parallel computing, so there was no point in using transputers anymore. However, such devices exist even now -- they are specialized accelerators. But their field of application is very narrow, and such accelerators are not widely spread. However, parallel computing has already entered the mass market and 3D games. Universal devices with multi-core processors for parallel vector computing in 3D graphics reach high peak performance, CPUs cannot keep up with it. Of course, maximum performance is reached only in a number of convenient tasks and has some limits. But such devices are already widely used in the new fields they were not initially designed for. An excellent example of such parallel processors is Cell, designed by Sony-Toshiba-IBM for Sony PlayStation 3, as well as all modern graphics cards from market leaders -- NVIDIA and AMD. We'll not touch upon Cell today, even though it had been launched earlier, and it's a general-purpose processor with additional vector features. The first GPGPU technologies (General-Purpose computation on GPUs) for 3D graphics cards appeared several years ago. Modern GPUs contain hundreds of arithmetic units, and their power can be used to accelerate a lot of compute-intensive applications. The existing generation of GPUs possesses a flexible architecture. Together with high-level programming languages and firmware architectures, such as the ones described in this article, it reveals these features and makes them much more accessible. GPCPU was inspired by the appearance of relatively fast and flexible shader programs that can be executed by modern GPUs. Developers decided to employ GPUs not only for rendering in 3D applications, but also for other parallel computations. GPGPU used graphics APIs for this purpose: OpenGL and Direct3D. Data were fed to a GPU in the form of textures, and computing programs were loaded as shaders. This method had its shortcomings -- relatively high programming complexity, low data exchange rate between a CPU and a GPU, and other limitations to be described below. GPU-assisted computing has been developing rapidly. At a later stage, both main GPU manufacturers, NVIDIA and AMD, announced their platforms -- CUDA (Compute Unified Device Architecture) and CTM (Close To Metal or AMD Stream Computing) correspondingly. Unlike previous GPU programming models, they were implemented to take into account direct access to hardware functions of graphics cards. These platforms are not compatible with each other -- CUDA is an extension of programming language C, while CTM is a virtual machine that executes assembler code. However, both platforms eliminated some of important limitations of previous GPGPU models that use the traditional graphics pipeline and corresponding interfaces Direct3D or OpenGL. Open standards that use OpenGL certainly seem to be more portable and universal. They allow to use the same code for GPUs from different manufacturers. But such methods have lots of shortcomings, they are significantly less flexible and not so convenient to use. Besides, they do not allow to use specific features of certain graphics cards, such as fast shared memory, available in modern processors. That's why NVIDIA launched CUDA -- C-like programming language with its own compiler and libraries to use GPU for computing. Writing optical code for GPUs is not easy, of course. This task needs thorough manual labour. But CUDA reveals all functions and gives programmers better control over hardware functions of GPUs. What's important, NVIDIA CUDA is supported by G8x, G9x, and GT2xx, which are used in widely popular GeForce 8, 9, and 200 Series. The latest version released these days is CUDA 2.0, which has some new features, for example, support for double precision. CUDA is available for 32-bit and 64-bit operating systems -- Linux, Windows, and MacOS X. Difference between CPU and GPU in parallel computingCPU frequency growth is now limited by physical matters and high power consumption. Their performance is often raised by increasing the number of cores. Present day processors may contain up to four cores (further growth will not be fast), and they are designed for common applications, they use MIMD (multiple instructions / multiple data). Each core works independently of the others, executing various instructions for various processes. Special vector features (SSE2 and SSE3) for four-component (single floating-point precision) and two-component (double precision) vectors appeared in general-purpose processors because of increased requirements of graphics applications in the first place. That's why it's more expedient to use GPUs for certain tasks, as they are initially designed for them. For example, NVIDIA chips are based on a multiprocessor with 8-10 cores and hundreds of ALUs, several thousand registers and some shared memory. Besides, a graphics card contains fast global memory, which can be accessed by all multiprocessors, local memory in each multiprocessor, and special memory for constants. Most importantly, these several multiprocessor cores in a GPU are SIMD (single instruction, multiple data) cores. And these cores execute the same instructions simultaneously. This programming style is common for graphics algorithms and many scientific tasks, but it requires specific programming. In return, this approach allows to increase the number of execution units by simplifying them. So, let's enumerate the main differences between CPU and GPU architectures. CPU cores are designed to execute a single thread of sequential instructions with maximum speed, and GPUs are designed for fast execution of many parallel instruction threads. General-purpose processors are optimized for high performance of a single command thread processing integer and floating-point numbers. Random memory access. CPU engineers try to have their products execute as many instructions in parallel as possible to increase performance. So Intel Pentium introduced superscalar execution of two instructions per cycle, and Pentium Pro added out-of-sequence execution of instructions. However, parallel execution of a sequential instruction thread has some basic limitations, and increasing the number of execution units does not yield proportional performance gains. GPUs can execute instructions in parallel from the very beginning. A GPU receives a group of polygons, performs all necessary operations, and then outputs pixels. Polygons and pixels are processed independently. They can be processed in parallel, separately from each other. Because of the initial parallel organization of GPUs, they use a lot of execution units, which can be easily loaded, unlike sequential instruction thread for CPU. Besides, modern GPUs can also execute more than a single instruction per cycle (dual issue). For example, in some conditions Tesla architecture executes MAD+MUL or MAD+SFU simultaneously. GPUs also differ from CPUs in memory access principles. It's easily predictable in GPUs -- if a texture texel is read from memory, time will come for the neighbouring texels as well. The same concerns writing data -- a pixel is written into a frame buffer, and several cycles afterwards the neighbouring pixel will be written as well. So this memory organization is different from what is used in CPUs. Unlike general-purpose processors, GPUs just don't need a large cache, textures require just several kilobytes (up to 128-256 KB in modern GPU). Memory operations are different in GPUs and CPUs. For example, not all CPUs have built-in memory controllers, and all GPUs usually have several controllers, up to eight 64-bit channels in NVIDIA GT200. Besides, graphics cards use faster memory, so GPUs enjoy much higher memory bandwidth, which is relevant for parallel computations with huge data streams. General-purpose processors spend their transistors and die surface on command buffers, hardware branching prediction, and huge volumes of on-chip caches. All these units are necessary to accelerate execution of just a few command streams. GPUs spend transistors on arrays of execution units, dispatchers, small volumes of shared memory, and memory controllers for several channels. All of the above does not accelerate execution of separate streams, but it allows a GPU to process several thousand threads, executed by the chip simultaneously, requiring high memory bandwidth. Let's analyze caching differences. CPUs use caches to increase their performance owing to reduced memory access latencies, and GPUs use caches or shared memory to increase memory bandwidth. CPUs reduce memory access latencies using large caches as well as branching prediction. These hardware parts take up most of the die surface and consume much power. GPUs solve the problem of memory access latencies using simultaneous execution of thousands threads -- when one thread is waiting for data from memory, a GPU can execute another thread without latencies. There exist a lot of differences in multi-threaded operations as well. CPUs can execute 1-2 threads per core, while GPUs can maintain up to 1024 threads per each multiprocessor (there are several of them in a GPU). Switching from one thread to another costs hundreds of cycles to CPUs, but GPUs switch several threads per cycle. Besides, CPUs use SIMD (single instruction is performed over multiple data) vector units, and GPUs use SIMT (single instruction, multiple threads) for scalar thread processing. SIMT does not require developers to convert data to vectors and allows arbitrary branching in threads. In brief, unlike modern CPUs, graphics chips are designed for parallel computations with lots of arithmetic operations. Much more transistors in GPUs work as they should -- they process data arrays instead of flow control of several sequential computing threads. This diagram shows how much room is occupied by various circuits in CPUs and GPUs: 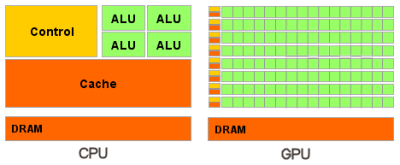 So, multisequencing algorithms for hundreds of execution units is the backbone of effective GPU usage for scientific and other non-graphics computations. For example, lots of molecular modeling applications are adapted perfectly for GPU computing, they require high processing power, and they are convenient for parallel computing. And using several GPUs gives even more computing power for such tasks. Using GPUs for computing demonstrates excellent results in algorithms that use parallel data processing. That is, when the same sequence of mathematical operations is applied to a large volume of data. The best results are achieved, if the number of arithmetic instructions significantly exceeds the number of memory access calls. It has lower requirements to flow control. Besides, high density of arithmetics and high data volume cancel the need in large caches, as in CPUs. As a result of all differences described above, theoretical performance of graphics processors is much higher than CPU performance. NVIDIA publishes the following graph of CPU/GPU performance growth for the last years: 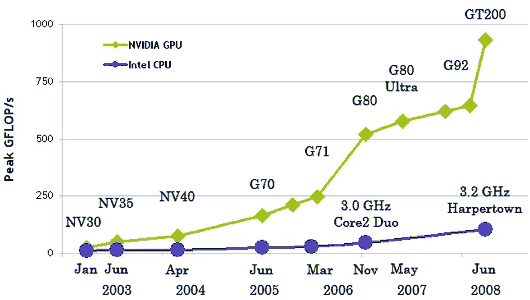 These data are not without a touch of guile, of course. In practice, CPUs reach theoretical results much easier. Besides, these numbers are published for single precision in case of GPUs and for double precision for CPUs. Anyway, single precision is sufficient for a number of parallel tasks, and performance difference between general-purpose and graphics processors is great. So the game is worth the candle. Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. |














