
CONTENTS
- General information on the P10 and its positioning
- Line of products
- P10's specification
- P10's architecture
- Peculiarities of the 3Dlabs Wildcat VP870 128MB video card
- Test system configurations and driver settings
- Test results: briefly on 2D and extreme tests from DirectX 8.1 SDK
- Test results: 3DMark2001 SE synthetic tests
- Test results: 3DMark2001 SE game tests
- 3D quality in games
- Test results: Professional tests: SPECviewperf 7.0
- Test results: Professional tests: Discreet 3DS MAX 4.26
- Conclusion
The Đ10 can be considered a starting point of the strengthening family of flexibly programmable GPUs. This chip takes a special position. It is nothing else but a hardware incarnation of a project of the API OpenGL 2.0 standard, as 3Dlabs sees this API. We wrote about the OpenGL 2.0 product in detail and touched upon peculiarities of the DirectX 9 (in analytical materials on Matrox Parhelia-512 and ATI RADEON 9700). As you might notice, although ideas concerning flexible programming of operation of a graphics accelerator are common, it's easy to find difference in realization of such ideas, even on the API's level. Now, when we have a 3Dlabs P10 based card in our lab, we can trace differences on the hardware level.
Positioning
You shouldn't compare directly this card (as far as specs, frequencies or speeds in game tests or applications are concerned) with the latest gaming solutions because the chip was developed as a professional accelerator of OpenGL applications. It is known that most game applications still need a higher fillrate and texturing speed while professional ones need higher transform and lighting speeds. Besides, game applications (excluding future games related with shaders, for example, Next Doom) do not require extraordinary additional capabilities. Moreover, edge anti-aliasing or exotic methods of quality multisampling and AA are not even spoken about. As a rule, average users do not enable maximum settings of anisotropic filtering.This chip is positioned by the developers as a professional accelerator. It is obvious that Creative that swallowed up 3Dlabs pays more attention to the mass, i.e. game, market (just remember what happened to the developer of professional sound solutions EMU also absorbed by Creative). Undoubtedly the Đ10 will also appear on the scene a bit later with some hardware modifications (from an architectural standpoint this GPU is easily scalable in any direction including a fillrate). It's also possible that Creative will just adjust the drivers for games in the beginning. In our opinion such scenario is possible only provided that the prices of game solutions on the P10 are not high - due to some reasons (we will turn to them later) it will be quite complicated to compete against top models of NVIDIA and ATI, irrespective of an optimization degree of the drivers.
And now let's see how the P10 based cards are positioned inside the family of the 3Dlabs professional accelerators:
Line of products
- Wildcat VP970: 128 MB of 256-bit DDR SDRAM; 225M Vertices/Sec; 42G AA Samples/Sec; meant for tough rendering processes in CAD/DCC applications of all kinds.
- Wildcat VP870: 128 MB of 256-bit DDR SDRAM; 188M Vertices/Sec; 35G AA Samples/Sec; also meant for CAD/DCC applications (easier).
- Wildcat VP760: 64 MB of 256-bit DDR SDRAM; 165M Vertices/Sec; 23G AA Samples/Sec; also meant for CAD applications and provides a good price/power ratio.


Specification
Here are traditional performance characteristics of the accelerator and the card based on it - VP870:- Technology: 0.15-micron;
- Transistors: over 76 million;
- Core clock frequency: unknown (presumably 200-250 MHz);
- Memory bus: 256bit DDR;
- Local memory: up to 256 MB;
- Local memory on the tested card: 128 MB;
- Memory clock speed: unknown (presumably 250-300 DDR MHz), 17-20 GB/s;
- Interface bus: AGP 4x, 1 GB/s;
- Full support of all capabilities of the project of the OpenGL 2.0 standard from 3Dlabs;
- Drivers optimized for professional applications;
- 16 scalar floating-point (F32) flexibly configurable vertex processors (a more flexible analog of 4 vector 4D processors of R300 or NV30);
- 64 floating-point (F32) processors for generation of texture coordinates;
- 64 non-programmable units for sampling and filtering texture values
- Trilinear and anisotropic filtering supported;
- 64 integer (fixed point) processors for pixel shaders;
- Possible to program arbitrarily (!) last stages of a pipeline, which controls reading and recording of values into a frame buffer, anti-aliasing and multisampling;
- The frame buffer can house (without taking multisampling into account) not more than 4 completely calculated pixels at a clock.
- Partial (!) support of the DX9 features (pixel pipelines work only with integer values at the shader stage):
- Pixel Shader 1.4;
- Vertex Shader 2.0 (?);
- Multisampling up to 8x inclusive;
- Hardware tessellation of N-Patches with Displacement Mapping and, optional, adaptive detailing level;
- Multithread command processing - simultaneous rendering of images for several applications and windows with hardware management of command streams;
- Memory optimization technology based on the block triangle shading (8x8 blocks);
- HSR - early removal of hidden surfaces of 8x8 and Early Z Test on the pixel level;
- Two independent CRTC;
- Two integrated 10bit 400 MHz RAMDACs with hardware gamma correction;
- One (two?) integrated DVI (TDMS transmitter) interface.
- Integrated general-purpose digital interface video port.
| Accelerator | R200(128 MB) | NV25(Ti 4600) | R300 | NV30 (1) | Parhelia 512 | P10(VP870) |
|---|---|---|---|---|---|---|
| Technology; transistors, M | 0.15; 62 | 0.15; 68 | 0.15; 107 | 0.13; 120 | 0.15; 96 | 0.15; 72 |
| AGP | 4x | 4x | 8x | 8x | 4x | 4x |
| Memory bus, bits | 128 DDR | 128 DDR | 256 DDR (II) (2) | 256 DDR II | 256 DDR | 256 DDR |
| Memory frequency, MHz | 275 | 325 | >300 | >400 | 275 | 250...300 (?) |
| Core frequency, MHz | 275 | 300 | 300 | 400 | 220 | 200...250 (?) |
| Pixel pipelines | 4 | 4 | 8 | 8 | 4 | 64 (9) |
| Texture modules | 4x2 | 4x2 | 8x1 (3) | 8x2 | 4x4 | 64 (10) |
| Textures/pass | 6 | 4 | 16 (4) | 16 (4) | 4 | 8 (5) |
| Vertex pipelines | 2 | 2 | 4 | 4 | 4 | 16 (7) |
| Fixed T&L unit | Yes | No | No | No | No | No |
| N-Patches | DX8 | No | DM (DX9) | DM (DX9) | DM (DX9) | DM (DX9) |
| Vertex shaders | 1.1 | 1.1 | 2.0 | 2.0 (6) | 2.0 (?) | 2.0 (?) |
| Pixel shaders | 1.4 | 1.3 | 2.0 | 2.0 (6) | 1.3 | 1.2 (?) |
| Memory controller | 2x64 | 4x32 | 4x64 | 4x64 | 1x256 | ? |
| RAMDAC, MHz | 400 | 400 | 2*400 | 2*400 (?) | 2*400 | 2*400 |
| Optimization technologies | Yes (HyperZ II) | Yes (LightSpeed II) | Yes (HyperZ III) | Yes (LightSpeed 3 ?) | Only early Z test | 8x8 units (8) |
Note:
- (1) Compilation is based on the official data and rumors
- (2) Most likely, DDR II will be supported together with the DDR.
- (3) Each texture unit can fulfill trilinear sampling itself.
- (4) According to the DX9 requirements, up to 16 different textures with 8 precalculated (interpolated over a triangle) 4D texture coordinates can be used in a pass. In a pixel shader it's possible to sample up to 32 values from these textures.
- (5) Up to 8 textures with precalculated or interpolated full texture coordinates can be used. In a pixel shader it's possible to sample up to 16 values from these textures.
- (6) To all appearances, the hardware part will have capabilities exceeding the DX requirements for vertex and pixel shaders 2.0.
- (7) 16 scalar floating-point processors are combined into groups of 2,3 or 4 for processing vector values. I.e. 4 complete 4D vector instructions can be executed per clock, like on the R300 or NV30; scalar and 2D/3D vector instructions can be more depending on a combination of instructions waiting to be executed.
- (8) Shading of triangles in 8x8 blocks for optimization of caching and preliminary HSR on the block and pixel levels.
- (9) The number of parallel 32bit integer processors for pixel shaders. The processors can be reconfigured flexibly to support a certain calculation format, for example, R10G10B10A2 or R16G16B16 integer formats. In the latter case the number of pixels processed in parallel will reduce twice (two processors will be used for one pixel). Besides, there is a severe limitation - the chip can record into the frame buffer (i.e. physically shade) up to 4 pixels at a clock. Because of a considerable number of processors and limitations of the .15 technology 3Dlabs couldn't provide support for the floating-point format, but they hope to do it in their future chips.
- (10) The real number of normal texture units is likely to be lower - 16 or even 8.
P10's architecture
The P10 has a very specific architecture - fixed blocks alternate with programmable ones a lot of times, and programmable blocks are usually made in the form of wide arrays of simple processors which are flexibly configurable into groups for processing certain tasks.Here is a block-diagram of the P10:

An interesting feature useful for professional applications is the P10's capability to execute simultaneously competitive command streams from different applications. This is what is controlled by the command processor:

The P10 supports virtual texturing controlling block caching of large textures in the accelerator's memory:

Now let's look at the entire diagram of the 3D graphics pipeline of the P10 which deals with 3D imaging:
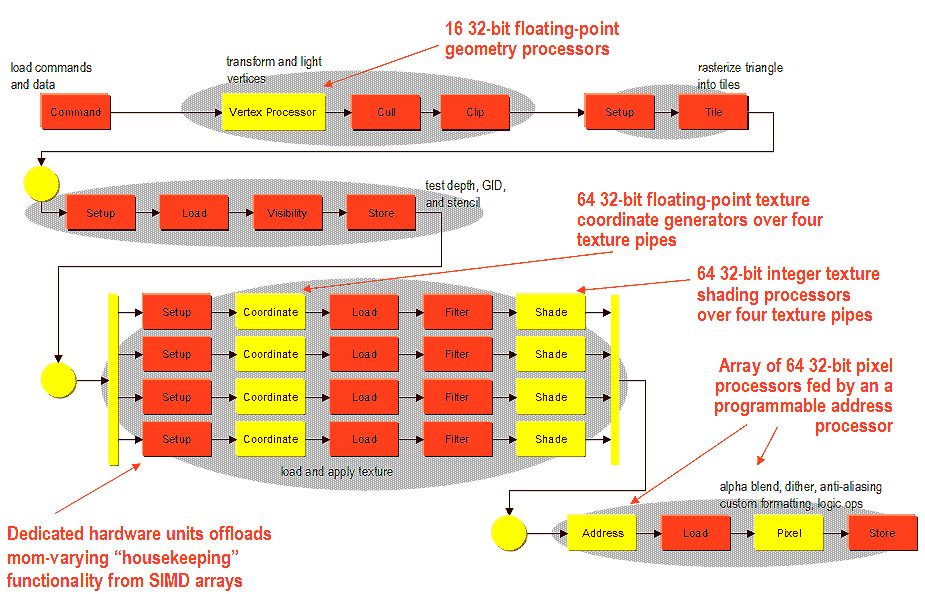
First of all commands get into the vertex processor:

Vertex coordinates and their attributes obtained from the vertex processors array are sent for shading. First, the dedicated hardware units get rid of back sides and triangles which are not visible (see also the general diagram, Cull and Clip blocks):

Each tile is shaded according to the following scheme:
The following picture shows how it is defined whether certain blocks and pixels need to be shaded (see also the general scheme):

64 pixels are shaded in parallel, which is a whole 8x8 block (!). Each of 64 pixels follows this way through fixed and programmable hardware units:
When the final value, as a result of the pixel shader, is calculated, it is sent to one of the dedicated programmable pipelines:
Finally, before we turn to the performance tests let me show you a list of DirectX 8 capabilities supported in the current drivers:
- Texture size - up to 2048x2048, nonsquare textures are possible
- Anisotropy degree - up to 8
- Light sources - up to 16
- Textures in a pass - up to 8
- Clipping surfaces - 6
- Sprite scaling - up to 127
- Primitives per one call - up to 1073741823 (a lot)
- Vertex buffer - 65536
- Vertex streams - up to 8
- Vertex Shader 1.1
- Vertex Shader constants - 128
- Pixel Shader 1.2
- Pixel shader value - up to 8
- Multisampling mode: No, 2, 4, 8 samples
- Final buffer formats:
- D3DFMT_A8R8G8B8
- D3DFMT_X8R8G8B8
- D3DFMT_R5G6B5
- D3DFMT_X1R5G5B5
- D3DFMT_A1R5G5B5
- Depth Buffer formats:
- D3DFMT_D32
- D3DFMT_D24S8
- D3DFMT_D16
- D3DFMT_D24X8
- Texture formats:
- D3DFMT_A8R8G8B8
- D3DFMT_X8R8G8B8
- D3DFMT_R5G6B5
- D3DFMT_X1R5G5B5
- D3DFMT_A1R5G5B5
- D3DFMT_A4R4G4B4
- D3DFMT_A8
- D3DFMT_L8
- D3DFMT_A8L8
- D3DFMT_A4L4
- D3DFMT_V8U8
- D3DFMT_L6V5U5
- D3DFMT_X8L8V8U8
- D3DFMT_Q8W8V8U8
- D3DFMT_DXT1
- D3DFMT_DXT2
- D3DFMT_DXT3
- D3DFMT_DXT4
- D3DFMT_DXT5
- Cube texture formats:
- D3DFMT_A8R8G8B8
- D3DFMT_X8R8G8B8
- D3DFMT_R5G6B5
- D3DFMT_X1R5G5B5
- D3DFMT_A1R5G5B5
- D3DFMT_A4R4G4B4
- D3DFMT_DXT1
- D3DFMT_DXT2
- D3DFMT_DXT3
- D3DFMT_DXT4
- D3DFMT_DXT5
- 3D texture formats:
- D3DFMT_A8R8G8B8
- D3DFMT_X8R8G8B8
- D3DFMT_R5G6B5
- D3DFMT_X1R5G5B5
- D3DFMT_A1R5G5B5
- D3DFMT_A4R4G4B4
- D3DFMT_A8
- D3DFMT_L8
- D3DFMT_A8L8
- D3DFMT_A4L4
- D3DFMT_DXT1
- D3DFMT_DXT2
- D3DFMT_DXT3
- D3DFMT_DXT4
- D3DFMT_DXT5
- Simple texture filtering modes:
- D3DPTFILTERCAPS_MINFPOINT
- D3DPTFILTERCAPS_MINFLINEAR
- D3DPTFILTERCAPS_MINFANISOTROPIC
- D3DPTFILTERCAPS_MIPFPOINT
- D3DPTFILTERCAPS_MIPFLINEAR
- D3DPTFILTERCAPS_MAGFPOINT
- D3DPTFILTERCAPS_MAGFLINEAR
- D3DPTFILTERCAPS_MAGFANISOTROPIC
- Cube texture filtering modes:
- D3DPTFILTERCAPS_MINFPOINT
- D3DPTFILTERCAPS_MINFLINEAR
- D3DPTFILTERCAPS_MIPFPOINT
- D3DPTFILTERCAPS_MIPFLINEAR
- D3DPTFILTERCAPS_MAGFPOINT
- D3DPTFILTERCAPS_MAGFLINEAR
- 3D texture filtering modes:
- D3DPTFILTERCAPS_MINFPOINT
- D3DPTFILTERCAPS_MAGFPOINT
At last, here is a list of OpenGL extensions supported at the moment:
| Matrox, ICD for Parhelia version 1.2 | NVIDIA, GeForce4 Ti 4400/AGP/SSE2, version 1.3.1 | 3Dlabs, Wildcat VP870, version: 1.2.0 |
| GL_ARB_multitexture | GL_ARB_imaging | GL_ARB_multitexture |
| GL_ARB_point_parameters | GL_ARB_multisample | GL_ARB_texture_env_add |
| GL_ARB_texture_compression | GL_ARB_multitexture | GL_ARB_texture_env_combine |
| GL_ARB_texture_cube_map | GL_ARB_texture_border_clamp | GL_ARB_texture_env_crossbar |
| GL_ARB_texture_env_add | GL_ARB_texture_compression | GL_ARB_texture_border_clamp |
| GL_ARB_texture_env_combine | GL_ARB_texture_cube_map | GL_ARB_texture_cube_map |
| GL_ARB_texture_env_dot3 | GL_ARB_texture_env_add | GL_ARB_texture_env_dot3 |
| GL_ARB_transpose_matrix | GL_ARB_texture_env_combine | GL_EXT_bgra |
| GL_S3_s3tc | GL_ARB_texture_env_dot3 | GL_EXT_blend_subtract |
| GL_ATI_element_array | GL_ARB_transpose_matrix | GL_EXT_blend_minmax |
| GL_ATI_vertex_array_object | GL_S3_s3tc | GL_EXT_compiled_vertex_array |
| GL_EXT_bgra | GL_EXT_abgr | GL_EXT_polygon_offset |
| GL_EXT_blend_color | GL_EXT_bgra | GL_EXT_rescale_normal |
| GL_EXT_blend_func_separate | GL_EXT_blend_color | GL_EXT_separate_specular_color |
| GL_EXT_blend_logic_op | GL_EXT_blend_minmax | GL_EXT_secondary_color |
| GL_EXT_blend_minmax | GL_EXT_blend_subtract | GL_EXT_texture3D |
| GL_EXT_blend_subtract | GL_EXT_compiled_vertex_array | GL_EXT_texture_object |
| GL_EXT_secondary_color | GL_EXT_separate_specular_color | GL_EXT_texture_edge_clamp |
| GL_EXT_compiled_vertex_array | GL_EXT_fog_coord | GL_EXT_texture_env_add |
| GL_EXT_draw_range_elements | GL_EXT_multi_draw_arrays | GL_EXT_texture_env_combine |
| GL_EXT_element_array | GL_EXT_packed_pixels | GL_EXT_texture_env_dot3 |
| GL_EXT_fog_coord | GL_EXT_paletted_texture | GL_EXT_texture_cube_map |
| GL_EXT_multi_draw_arrays | GL_EXT_point_parameters | GL_EXT_texture_filter_anisotropic |
| GL_EXT_packed_pixels | GL_EXT_rescale_normal | GL_EXT_multi_draw_arrays |
| GL_EXT_point_parameters | GL_EXT_clip_volume_hint | GL_SGIS_multitexture |
| GL_EXT_rescale_normal | GL_EXT_draw_range_elements | GL_SGIS_texture_border_clamp |
| GL_EXT_secondary_color | GL_EXT_shared_texture_palette | GL_SGIS_texture_lod |
| GL_EXT_separate_specular_color | GL_EXT_stencil_wrap | GL_NV_register_combiners |
| GL_EXT_stencil_wrap | GL_EXT_texture3D | GL_NV_vertex_program |
| GL_EXT_subtexture | GL_EXT_texture_compression_s3tc | GL_NV_texgen_reflection |
| GL_EXT_texture3D | GL_EXT_texture_edge_clamp | GL_WIN_swap_hint |
| GL_EXT_texture_compression_s3tc | GL_EXT_texture_env_add | GL_KTX_buffer_region |
| GL_EXT_texture_cube_map | GL_EXT_texture_env_combine | - |
| GL_EXT_texture_edge_clamp | GL_EXT_texture_env_dot3 | - |
| GL_EXT_texture_env_add | GL_EXT_texture_cube_map | - |
| GL_EXT_texture_filter_anisotropic | GL_EXT_texture_filter_anisotropic | - |
| GL_EXT_texture_lod_bias | GL_EXT_texture_lod | - |
| GL_EXT_vertex_array | GL_EXT_texture_lod_bias | - |
| GL_EXT_vertex_array_object | GL_EXT_texture_object | - |
| GL_EXT_vertex_shader | GL_EXT_vertex_array | - |
| GL_EXT_texture_env_combine | GL_EXT_vertex_weighting | - |
| GL_EXT_texture_env_dot3 | GL_HP_occlusion_test | - |
| GL_KTX_buffer_region | GL_IBM_texture_mirrored_repeat | - |
| GL_MTX_fragment_shader | GL_KTX_buffer_region | - |
| GL_NV_texgen_reflection | GL_NV_blend_square | - |
| GL_SGIS_multitexture | GL_NV_copy_depth_to_color | - |
| GL_SGIS_texture_lod | GL_NV_evaluators | - |
| WGL_EXT_swap_control | GL_NV_fence | - |
| - | GL_NV_fog_distance | - |
| - | GL_NV_light_max_exponent | - |
| - | GL_NV_multisample_filter_hint | - |
| - | GL_NV_occlusion_query | - |
| - | GL_NV_packed_depth_stencil | - |
| - | GL_NV_point_sprite | - |
| - | GL_NV_register_combiners | - |
| - | GL_NV_register_combiners2 | - |
| - | GL_NV_texgen_reflection | - |
| - | GL_NV_texture_compression_vtc | - |
| - | GL_NV_texture_env_combine4 | - |
| - | GL_NV_texture_rectangle | - |
| - | GL_NV_texture_shader | - |
| - | GL_NV_texture_shader2 | - |
| - | GL_NV_texture_shader3 | - |
| - | GL_NV_vertex_array_range | - |
| - | GL_NV_vertex_array_range2 | - |
| - | GL_NV_vertex_program | - |
| - | GL_NV_vertex_program1_1 | - |
| - | GL_SGIS_generate_mipmap | - |
| - | GL_SGIS_multitexture | - |
| - | GL_SGIS_texture_lod | - |
| - | GL_SGIX_depth_texture | - |
| - | GL_SGIX_shadow | - |
| - | GL_WIN_swap_hint | - |
| - | WGL_EXT_swap_control | - |
Card
This is not a preproduction sample, but a production card.It is equipped with an
 |
 |
| Samsung memory chips of the BGA form-factor and 3.3ns access time, which corresponds to 300 (600) MHz. The memory works presumably at 250-300 MHz |  |
| 3Dlabs Wildcat VP870 | |
|---|---|
 |
 |
| With cooler | |
 |
|
The design is very unusual. Sure, the 256bit high-speed bus made the design so complicated. First of all, there is a screen protecting from pickups:

Contrary to the Matrox Parhelia 128MB, the PCB of the Wildcat VP870 is almost empty - there is no a great amount of additional and buffer elements. The developers decided to show that the PCB consists of 8 layers and made a window with the layers enumerated:



There is a DVI-out, that is why you must have a DVI-to-d-Sub adapter to connect two CRT monitors. A TV-out (S-Video) is also provided. On the whole, the PCB is quite expensive, but it is less dearer than the Matrox's one. I think it's possible to make a relatively cheap card on such PCB.
The memory modules are located around the chip but at different distances. Besides, the distance between the processor and the chips is much shorter, that is why the card looks quite empty - some of the chips are hidden under the cooler. Now look at the VPU:

Although the VPU is equipped with a 256-bit memory interface, it has a usual package, though a bit greater. In spite of a very complicated architecture, the processor doesn't heat up much because the number of transistors and technology are comparable to the NV25 chips, and the clock speeds are not very high.
But anyway, such a powerful chip needs an efficient cooler. Take a look
at its shape and dimensions.
| This is a closed heatsink with a fan shifted off from the chip's center. Such cooler is installed on GeForce4 Ti cards, in particular, such coolers are typical of MSI and Triplex (they differ only in the covers' shapes). |  |
 |
Test system and drivers
Testbed:- Pentium 4 based computer (Socket 478):
- Intel Pentium 4 2200 (L2=512K);
- ASUS P4T-E (i850) mainboard;
- 512 MB RDRAM PC800;
- Quantum FB AS 20GB HDD;
- Windows XP.
- Pentium III 1000 MHz based computer:
- Intel Pentium III 1000EB;
- Chaintech 6OJV2 (i815E);
- 256 MB SDRAM PC133;
- IBM DPTA 20GB;
- Windows XP.
In the tests we used 3Dlabs drivers 4.23. VSync was off.
For comparison we used the following cards:
- ASUS V8460Ultra (GeForce4 Ti 4600, 300/325 (650) MHz, 128 MB, driver 29.42);
- Matrox Parhelia 128MB (220/275 (550) MHz, 128 MB, driver 2.31);
- Gigabyte MAYA AP128DG-H RADEON 8500 Deluxe (275/275 (550) MHz, 128 MB, driver 6.118);
- Hercules 3D Prophet 9000 Pro (RADEON 9000 Pro, 275/275 (550) MHz, 128 MB, driver 6.118);
- ATI RADEON 7500 (290/230 (460) MHz, 64 MB, driver 6.118);
- Joytech Apollo Blade Monster Xabre 400 (250/250 (500) MHz, 128 MB, driver 3.03);
- Leadtek Winfast A170V (GeForce4 MX 440, 270/200 (400) MHz, 64 MB, driver 29.42);
- NVIDIA Quadro4 750XGL (275/275 (550) MHz, 128 MB, driver 28.32(ViewPerf7),29.42(3DS MAX));
- NVIDIA Quadro4 900XGL (300/325 (650) MHz, 128 MB, driver 28.32(ViewPerf7),29.42(3DS MAX));
- ATI FireGL 8800 (RADEON 8800, 250/300 (600) MHz, 128 MB, driver 3.036).
Driver settings





Test results
2D graphics
Together with the ViewSonic P817 monitor and BNC Bargo cable the card showed excellent quality at the following resolutions and frequencies:| 3Dlabs Wildcat VP870 | 1600x1200x85Hz, 1280x1024x100Hz, 1024x768x120Hz |
|---|
Such cards are produced only by 3Dlabs, that is why it makes no sense to repeat that 2D estimation depends on a certain sample. But although in this case quality may not depend on a certain sample, the tandem of the card and monitor, and mainly, quality of a monitor and a cable, have a strong effect.
3D graphics, MS DirectX 8.1 SDK - extreme tests
For testing different extreme characteristics of the chips we used modified (for better convenience and control) examples from the latest version of the DirectX SDK (8.1, release). Let's carry out the tests that are well known to our readers:Optimized Mesh
This test defines a real maximum throughput of an accelerator as far as triangles are concerned. For this purpose it uses several simultaneously displayed models each consisting of 50,000 triangles. No texturing. The dimensions are minimal - each triangle takes just one pixel. It must be noted that the results of this test are unachievable for real applications where triangles are much greater, and textures and lighting are used. The results are given only for 3 rendering methods - model optimized for the optimal output speed (with the size of the internal vertex cache on the chip accounted for) - Optimized, Unoptimized original model, and Strip - unoptimized model displayed in the form of one Triangle Strip. Besides, values in the mode of software emulation of the vertex pipeline are given to estimate efficiency of geometry transfer from the processor to the GPU:
Vertex shader unit performance
This test allows determining the maximum performance of the vertex shader unit. It uses a complex shader which deals with both type-transformation and geometrical functions. The test is carried out in the minimal resolution in order to minimize the shading effect:
Vertex matrix blending
This T&L's feature is used for verisimilar animation and model skinning. We tested blending using two matrices both in the "hardware" version and with a vertex shader that implements the same function. Besides, we obtained results in the software T&L emulation mode:
EMBM
In this test we measure performance drop caused by Environment mapping and EMBM (Environment Bump). We set 1280x1024 because exactly in this resolution the difference between cards and different texturing modes is the most discernible:
Pixel Shader performance
We used again a modified example of the MFCPixelShader having measured performance of the cards in high resolution in implementation of 5 shaders different in complexity, for bilinear-filtered textures:So, let's draw the first intermediate conclusion. In the DX 8.1 SDK tests the VP870 card looks confident (as compared with the DX8 generation of game accelerators) in geometry processing, but it looks much weaker in shading. It's well seen that it is designed exactly for professional use. The card will hardly become a strong competitor of the DX9 generation (R300 and NV30) even in geometry questions.
But we will return to these issues in autumn when it will be possible to test shaders 2.0 and other capabilities of the DirectX 9.0.
3D graphics, 3DMark2001 SE - synthetic tests
All measurements in all 3D tests were done in 32-bit color.Fillrate


Scene with a large number of polygons
In this test you should pay more attention to the minimal resolution where the fillrate makes almost no effect:

Is the problem in the drivers or in a low performance of a pool of the vertex processors?
Bump mapping
Look at the result of the synthetic EMBM scene:

Vertex shaders

Pixel shader
Taking into account that too low resolutions are limited by geometry and too high ones by the memory bandwidth let's take a look at 1024x768 and 1280x1024:Sprites
So, the second intermediate conclusion. In the synthetic tests the 3Dlabs P10 loses to its competitors. But that was expected as the accelerator is not meant for games, and the 3D Mark 2001 is a game benchmark, even from the standpoint of synthetic algorithms. Besides, the drivers for the DX8 are not crucial for the developers of the P10 and are still too weakly optimized to fight against ATI and NVIDIA solutions.
3D graphics, 3DMark2001 - game tests
3DMark2001, 3DMARKS

3DMark2001, Game1 Low details

- Rendered triangles per frame (min/avg/max): 19773/33753/143422
- Rendered textures per frame with 16 bit textures (min/avg/max): 7.5/8.8/16.5 MB
- Rendered textures per frame with 32 bit textures (min/avg/max): 15.1/17.7/30.3 MB
- Rendered textures per frame with texture compression (min/avg/max): 10.7/12.2/21.0 MB
3DMark2001, Game2 Low details

- Rendered triangles per frame (min/avg/max): 46159/51440/147828
- Rendered textures per frame with 16 bit textures (min/avg/max): 8.0/8.8/10.1 MB
- Rendered textures per frame with 32 bit textures (min/avg/max): 15.6/17.2/19.8 MB
- Rendered textures per frame with texture compression (min/avg/max): 9.3/10.9/13.5 MB
3DMark2001, Game3 Low details

- Rendered triangles per frame (min/avg/max): 16681/21746/39890
- Rendered textures per frame with 16 bit textures (min/avg/max): 2.8/4.1/4.7 MB
- Rendered textures per frame with 32 bit textures (min/avg/max): 5.7/8.2/9.4 MB
- Rendered textures per frame with texture compression (min/avg/max): 5.0/7.2/8.4 MB
3DMark2001, Game4

- Rendered triangles per frame (min/avg/max): 55601/81714/180938
- Rendered textures per frame with 16 bit textures (min/avg/max): 14.9/17.4/20.7 MB
- Rendered textures per frame with 32 bit textures (min/avg/max): 28.4/33.5/40.0 MB
- Rendered textures per frame with texture compression (min/avg/max): 28.4/33.5/40.0 MB
On the whole, in the 3DMark2001 the predicted test results are proven: the 3Dlabs Wildcat VP870 and its drivers are not adjusted for DirectX game applications at all. I don't even know who is to blame: either the drivers or the balance of capabilities of the P10. Let's wait for a game accelerator on the P10 promised by Creative Labs.
And now let me console professional designs who can play their favorite games on this card (though they will have to reduce a resolution for better comfort).
3D graphics, game tests
There are not many flaws. But the Morrowind game, which is the first that forms a water surface through pixel shaders, showed us the following pictures on the 3Dlabs Wildcat VP870 (the screenshots of the RADEON 8500 are given for comparison):P10


RADEON 8500

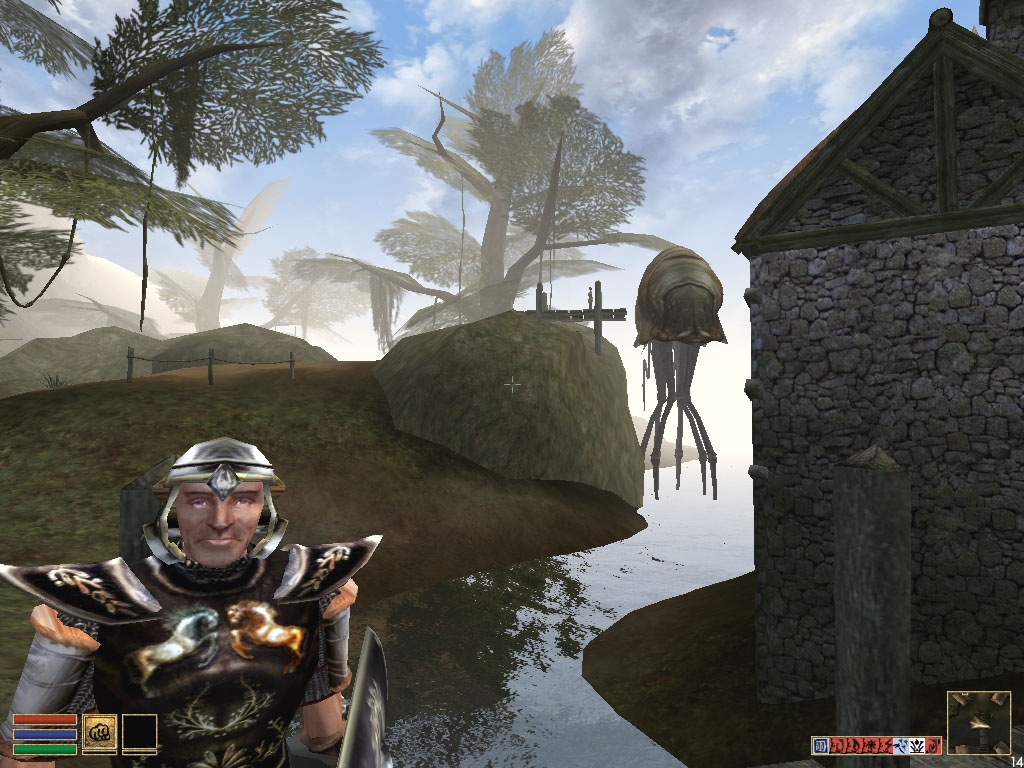
There were some distortions in other games (though not vital). Quality will be closer examined in the next (August) 3Digest (the gallery of screenshots will get pictures from many games obtained on the P10).
Professional tests, SPECviewperf 7.0
So, we have studied operation of the VP870 in the games and DIRECTX 8. But the main conclusion on a performance of a professional card must be drawn from professional tests. We chose two tests: the new SPECviewperf 7.0 and 3DS MAX 4.26. The new version of the SPECviewperf is an excellent professional synthetic test, and the 3DS MAX is an excellent example of a DCC application. The first test will show us how balanced professional capabilities of the card are, the second one will demonstrate its real advantages in real operation. The detailed descriptions of the tests and test techniques can be found on our site.So, we carried out the tests the following way: we installed the OS, then drivers of the video cards and then started the tests and made the measurements. The VP870 passed all the tests from the SPECviewperf suite without any problems - no hang-up, no quality losses. Well, this is what we expect from professional, carefully tested and certified drivers. Let's take a close look at the results:






Now the summary on the SPECviewperf 7.0 tests. The 3Dlabs's P10 based card leads in the most tests. As a rule, it works more efficient in the geometry optimization mode. That is why the specviewperf focuses mostly on geometry processing in most tests (or rather, it's done by real professional applications and tasks, and the benchmark reflects their popular needs). Besides, it makes sense to enable the geometry optimization mode forever, it never brings harm but often allows for a gain.
With the current prices and frequencies the VP870 card is the best choice in its niche (on the SPECviewperf 7.0). Now look at the scores in real applications:
Professional tests, Discreet 3DS MAX 4.26
After examination in the specviewperf which is still a synthetic test (though it excellently emulates accelerator's loads typical of real applications), we are going to study the VP870 in the 3DS MAX. In the 3DS MAX we removed modeling of designer's work, but we are sure this aspect will be clear from the scores. As all test scenes are rendered and displayed correctly (due to the drivers' certification) it makes no sense to include all screenshots into the review. We are going to show only the anti-aliasing operation.Let's start with the tests on standard demo scenes which come with the 3DS MAX. "Special driver" stands for a driver from the video card maker which is meant only for operation in the 3DS MAX. The ATI's drivers are called MAXIMUM, the NVIDIA's drivers are called MAXTREME, and the 3Dlabs' driver for the VP870 has no name because it has no specific management functions and uses only standard 3DS MAX settings. "OpenGL" stands for operation through a standard OpenGL driver. As you remember, in the SPECviewperf 3dmax-01 based on the 3DS MAX engine the VP870 is the first and, therefore, is the most obvious candidate for a rank of the best card for this 3D modeling system. So, let's dot the "i's" and cross the "t's".











Now let's turn to Line Antialiasing.

Below are screenshots of the anti-aliasing in different operating modes.
First of all, look at the screenshot with the line antialiasing disabled.
Geometry optimization, OpenGL:


Geometry optimization, OpenGL:


The card has an enormous potential which will probably be made use of with new drivers.
Summary on the 3DS MAX. The tests in the SPECviewperf pleased us. I hoped to get a new absolute leader. But the real applications show it's not simple. The card is of high quality and efficient, but its leadership is ambiguous. In different tests the results depend on multiple surrounding conditions and overwhelming advantage is not possible. The least thing we should admit is that the special driver is good and scores get really higher when it is used.
Conclusion
- First of all, this card is a perfect solution for professional designers working in the sphere of 3D modeling. Having the same price as the NVIDIA Quadro4 750XGL ($580 in August) (according to www.pricewatch.com), the 3Dlabs Wildcat VP870 NVIDIA Quadro4 doesn't fall behind in many tests and even outshines the more expensive Quadro4 900XGL.
- Originally the card was developed as a professional solution, and it performs excellently in modes and scenes where geometry processing speed prevails. It can also be referred to the modes with anti-aliasing, especially line AA.
- The pixel and vertex shaders realized in the P10 are not widely used in professional graphics, but there are traces of the flexible programmability of the chip noticeable in the highly optimized driver for the 3DS MAX. However that may be, but the potential of this card is not uncovered entirely; we should wait for the OpenGL 2.0, DirectX 9 and different high-level languages for programming graphics accelerators.
- We will continue studying the 3Dlabs Wildcat VP870 in different professional applications in Professional Cards Roundups (in particular, this autumn is going to bring a lot of new interesting materials).
- In game applications the 3Dlabs Wildcat VP870 is not that powerful, but it can be expected from a professional card. The drivers optimized for professional packets (just look at the list of ICD OpenGL extensions), the weak (unoptimized) DirectX 8 driver and peculiarities of the P10 itself designed for non-game applications do not allow for a greater speed in games.
- We consider that the gaming potential of this card is enabled by less than 50%, that is why we have no choice but to wait for a gaming card on the P10 or its special game-oriented modification with a higher shading performance. I hope such card will have drivers more suitable for games.
Alexander Medvedev (unclesam@ixbt.com)
Alexander Kondakov (kondalex@ixbt.com)
Write a comment below. No registration needed!











