 |
||
|
||
| ||
|
||
|
||
| ||
 CONTENTS
Lecture 1 - introductoryThe epoch of flexibly programmable graphics accelerators has at last began. Certainly, there are drawbacks! But they are being corrected. At the same time, programs of realistic graphics show that capabilities of even the latest generation of accelerators are miserable. But the direction in which they are developing is true and soon you will see an incarnation of realistic graphics on every desktop. Thank you for your attention (lengthy applause). Today we are aimed at preliminary examination of capabilities of the recently announced ATI's new-generation chip, we will also discuss its main competitor, still un announced NV30 and prospects of hardware graphics acceleration. Lecture 2 - characteristics of the main heroSo, ATI announced the RADEON 9700 in advance - earlier it was known as R300: 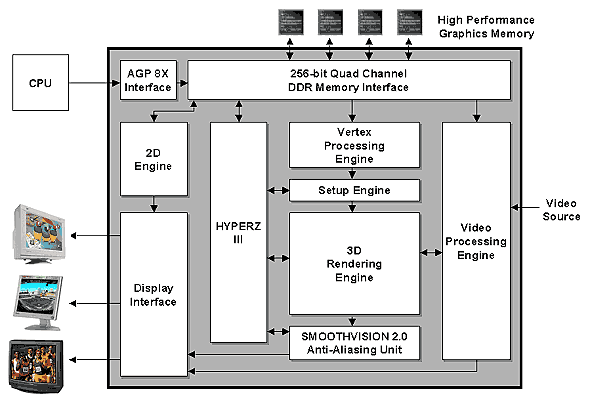 This chip unveils a new generation of graphics architectures from ATI by realizing the latest trends in the hardware outlined by the API DirectX 9. Some time ago we already touched upon key requirements that the DX9 sets for accelerators. Here are promised characteristics of the new chip and a flagship card based - RADEON 9700:
Well, the characteristics are really impressive. Later we will comment on each item and now we are turning to Lecture 3 - comparison of key characteristicsFor comparison we have chosen the most popular game solutions as well as the main future competitor of the R300 - NV30. The given possible specs of the NV30 are not official or precise - they
are taken from different sources and based on rumors found on the Net.
The considerable part of the parameters is assumed according to the open
data on new cross-ÀPI higher-level languages Ñ Graphics / Cine FX which
are meant to facilitate programming of such flexible chips. Besides, some
assumptions are based on the DX 9 requirements:
Notes:
However, its real market position can be estimated only after
comparing the specs and performance in applications of the final versions
of the R300 and NV30. And the R300 is not available yet. The potential
of the new architectures can be entirely revealed only with the DirectX
9 which is due to arrive in autumn. The NV30 will probably be released
also by that time. In autumn we will be able to witness a new battle of
giants. That is why the calendar advantage of the R300 doesn't give it
any trumps except a doubtful priority in the PR sphere.
NVIDIA decided to take risks - being one of the first who got an access to the .13 process, the company is in a completely different situation. The new process must have all its imperfections corrected, the mass production can be time shifted and percentage of operable chips can be very low in the beginning. On the other hand, the process will be tweaked, NVIDIA will get more benefits regarding the prime cost and clock speed (originally higher-frequency architectures of NVIDIA + the finer technology give 400 against 300). So, time works for NVIDIA; that is probably why ATI was in such a hurry with the "paper" release and will possibly put on the market first cards yet before the DirectX 9. However that may be, the stake on a king for a day is risky.
The question is whether these NV30 capabilities will be included
into the DX (for example, as a DX9.1, shaders 2.1 etc.) or will be available
only as OpenGL extensions.
Lecture 4 - memory controllerIn the new product ATI uses a familiar (from NVIDIA products) approach for memory control, which includes a 4-channel memory controller and an internal switch on the chip: 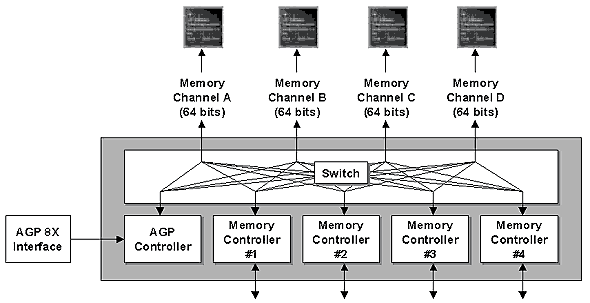 Well, earlier ATI preferred two- or one-channel controllers and large data blocks, while NVIDIA's caching and operation with memory is based on smaller blocks yet since the NV20. Both approaches have advantages and disadvantages, for example, the NVIDIA's one warms up memory stronger and is more critical to its parameters and quality. As a result, an overclocking potential is lower. The ATI's approach copes with memory better but is less efficient in complex tasks which use a lot of streams to access memory. As accelerators become more flexible, the number of streams which can be simultaneously read from the memory increases - there are several data flows for vertex shaders, 4 or 6 textures in a single pass. That is why the NVIDIA's approach is more effective in modern applications, and since the release of the R300 ATI also uses it :-). The memory optimization technology got one more Roman one in its name - now it is called HyperZ III. The idea is the same - new techniques are lacking but the old ones are improved. The technology provides quick compression and cleanup of the Z-buffer using 8x8 blocks, and 3 levels of a hierarchical presentation of the Z buffer for early determination of visibility of whole blocks of polygons. 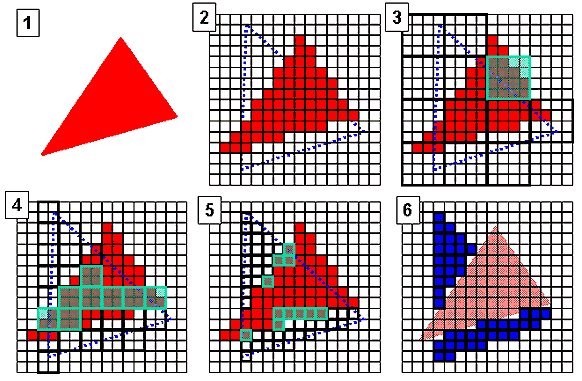 So, we have a shaded polygon (1) located close to an observer. And we want to shade polygon 2 located further and, therefore, partially overlapped. First of all we search at the highest level of the hierarchical Z buffer which stores distances to the largest 4x4 blocks, then we mark the unit which entirely belongs to the above triangle (3) and doesn't need to be shaded. Thus, we get rid of 16 pixels. Then we go to a lower level and cast aside 8 2x2 blocks. At the last level of the 1-pixel precision we find several pixels more which mustn't be shaded. Although this illustration is simplified, it is enough to get an idea of the principle of operation of the Z buffer and of a computation benefit. Like all modern accelerators, the R300 sports an Early Z Test. Its idea is simple - real color values (hence texture values and test results as well) are calculated for visible pixels. Obviously, with more complicated shaders and methods of texturing this technology will save more on a memory bandwidth and computational clocks of the accelerator. On a typical scene, with an overdraw factor of 2, it will throw off about a quarter or a third of pixels, at best - 50% in case of an ordered rendering of a scene. It is interesting how NVIDIA is going to name the similar technologies of its new chip - LMA III or not like ATI - LMA 3? However that may be, but clear that NVIDIA won't take the previous name LMA II :-). Lecture 5 - pixel pipelines and texture unitsWith the DX9 the requirements to complexity of pixel pipelines of the chip
will rise. The main catalyst of these requirements is the 2.0 version of
pixel shaders:
When describing the Cine FXm - an API-independent analog of higher-level effect files of the DirectX 9 compiled both for the latest versions of the OpenGL and for the DX9, NVIDIA mentions pixel shaders of 1024 instructions (!) processed continuously in one pass. The pixel shader can enable up to 512 constants each considered as one instruction. It seems that in this respect the NV30 is far ahead of the DX9 requirements. Earlier, pixel shaders were used with stages - the number of texture
stages was equal to the maximum number of textures used, the number of
computational stages was equal to the maximum number of instructions. Each
computation stage has a normal ALU and could implement any shader instruction.
Stages were adjusted for their instructions and then combined in a chain.
As a result, data (values of two general registers) when processed passed
all stages, and each carried out an instruction over them. It took a clock
to fulfill an operation, hence a pipeline of 8 stages which processed up
to 8 different pixels at different stages. The pipeline got the following
results at a clock:
But the chip makers couldn't actually afford even 8 stages per pipeline - 32 normal ALUs, of even an integer-valued format, would occupy too much space on the chip. Usually each pixel pipeline was given 2 or 4 stages (the Matrox Parhelia 512 had 5), and in case of a longer shader stages of 2 or 4 pipelines were combined in a chain. The number of shaded pixels fell down 2-4 times in that case. As the shaders are getting more complex, such approach ceases to be advantageous. It is necessary to provide at least 64 single-clock ALUs (for the stage approach), which is unrealizable, especially in case of floating precision of data representation. Besides, the number of temporary registers values of which are to be stored in each ALU and transferred from stage to stage at each clock is increasing. And what should we do when shaders become lengthier? Let's see what we have on the R300. There are 8 pixel pipelines each equipped with its own processor for pixel shaders. This is not a set of switched stages with ALU but exactly a processor (RISC) which implements an instruction at a clock. Lack of instruction flow management simplifies the matters. The longer the shader, the higher the expected result. On the other hand, complexity of tasks to be fulfilled at a clock is not so crucial anymore: now we can build almost any scene in one or two passes, and this is much more beneficial than several passes of speedier but simpler shaders. The restriction in the number of instructions in the new approach is very conditional - nothing prevents the processor from fulfilling 256 or 1024 instructions in turn - the only thing required is memory on the chip. It's interesting that to provide compatibility with the first versions of the shaders the pixel pipeline of the R300 and the NV30 supports calculations not only in floating formats F32 and F16 but also in the integer format I12. Without such support processing of old shaders could bring some unpleasant problems - emulation of some instructions might require up to 4 operations! 
Editor's note: Almost a portrait of the author of this article. Moreover, to accelerate calculations we can try a superscalar approach, let it be the simplest version like in the first superscalar RISC processors. Each ALU has several functional units - addition and subtraction unit, multiplication unit, division unit, a separate device managing data transfer between registers. It's not a great problem to create a processor which can simultaneously process instructions which relate to different units provided that they are not dependent, i.e. when a following instruction can be processed irrespective of a result of a previous one. That is why accelerator developers and Microsoft recommend taking into account dependences between neighbouring instructions and getting rid of them, if possible. On the other hand, a more advanced, speculative execution with rearrangement and rollback of instructions and register renaming of results for shader processors makes no sense now - it is too expensive taking into account an unjustified increased of complexity of each shader processor. As usual, in graphics it's more advantageous to make parallel fulfillment of shaders on the object level (level of vertices and pixels) by increasing the number of parallel processors dealing with blocks than to make parallel operation at the instruction level: the algorithms are not great and neighboring instructions are too tightly bound. That is why the number of pixel and vertex pipelines is twice greater as compared with the R200. In the near future pixel processors will become entire doubles (as to capabilities) of vertex ones because of the same data format and the same arithmetic instructions; the only thing lacking is an instruction order management, but this problem can be solved. The distinction between pixel and vertex processors will be vanishing. In several architecture generations a graphics accelerator will turn into a set of identical general-purpose vector processors which will have flexible configurable queues for asynchronous transfer of parameters between them. Processors' efforts will be distributed on the fly depending on an approach used for making an image of a balance of a required performance on certain tasks:
 The R300 is based on the 8x1 configuration - each pixel pipeline has only one texture unit connected: One of eight pixel pipelines of the R300 It seems that this is a forced economy caused by the .15-micron fab process. We can come up with a lot of real situations in a pixel shader when expectation of results of one texture unit significantly slows down processing of the shader! And it's possible to avoid such standstill with a second texture unit, thus, lifting the speed of pixel shader processing 1.5 or 2 times. Well, let's leave it for ATI and be happy that in spite of just one texture unit it's possible to enable trilinear filtering using this unit without speed losses. As well as combine trilinear and anisotropic filtering types (which was a well-known downside of the R200). For such long shaders it's rational to use a bit different approach of organization of texture units. Let's consider that units are not bound to a certain pixel pipeline but service any of them as requests for texture sampling are received. We thus could run shaders on different pipelines with some time shift of several instructions to make up for irregular interleaving of calculations and access to textures. First all units would service those pipelines which are waiting for textures and other pipelines would fulfill calculations. Then the situation would be vice versa. In this case the downtime would be much lower and 8 shared units would be enough for 8 pipelines. It's possible that ATI follows this approach but doesn't want to reveal the details. And it's possible that NVIDIA will take this approach for one of its future chips - because this idea was once discussed by engineers from 3dfx absorbed by NVIDIA. Lecture 6 - vertex pipelines and higher-level languagesVertex shaders haven't changed much like pixel ones, but at the same time
they are improved by a great margin - they are now able to control an instruction
flow. Now we have subroutines, loops, conditional and unconditional jumps.
At present all decisions to change an instruction flow are based on constants coming to the shader; this make problems in making decisions on-the-fly separately for each vertex. It's not clear why Microsoft have decided on it - the ATI R300 (and NVIDIA NV30) are likely not to unroll loops and subroutines into a continuous row of instructions but allow an indicator of the next instruction to move around the memory of instructions inside the chip. Well, in the next DX generation this limitation will be eliminated, and we will be able to call vertex pipelines of any accelerator vertex processors. Contrary to the R300, the NV30 is already able to control an order of instructions according to data from temporary registers - like any usual processor. On the other hand, the R300 allows fulfilling shaders of up to 1024 instructions, the NV30 only up to 256 (and up to 65536 instructions in case of unrolling of loops and subroutines). Everything that was said in the previous part about the superscalar implementation can be also referred, probably to the greater degree, to vertex shaders. Quite lenthgy shaders make us think about optimization for successful combined execution of instructions. When the hardware and API developers got a possibility to execute shaders of thousands of instructions they turned to higher-level languages. It's much more pleasant to deal with some Ñ dialect than with an assembler code which isn't used for already 8-10 years. At last the hardware corresponds to the required level, and now instead of thousands of constants and instructions we have hundreds and instead of hundreds we have tens. Soon complexity of programs for an accelerator can become equal to that of programs for ordinary processors, at least, for the part that manages 3D graphics. For example, NVIDIA announced its Ñ Graphics (CG) dialect which first wasn't user-friendly at all, despite all disadvantages it is a cross API tool - a shader code could be compiled both in the OpenGL and in the Direct3D environments. The compiler comes with a rich set of effects and samples. There is a new CG version - for DX9 - which is more handy regarding data binding and utilization and it can be called a de facto standard. Microsoft in not in a hurry either - it is debugging its HLSL which is actually the same CG (or it can be vice versa because the development works were carried out by NVIDIA and Microsoft together) but working only within the DirectX. Besides, at present the HLSL works only with vertex shaders. ATI doesn't stand idle either and announces its Render Monkey. This dialect is different. The NVIDIA's CG and Cine FX (an analog of techniques and effects from DX9, as well as the CG cross API!) are the most convenient ones, at least, due to export plugins for popular packets of 3D modeling and realistic graphics. 
Rendered Monkey :-) Lecture 7 - anti-aliasing, video capabilitiesThere is no a breakthrough in the anti-aliasing technique, we have the same SMOOTHVISION 2x, 4x and 6x, although it is named SMOOTHVISION 2.0. However, despite the same approach to forming pseudorandom templates now we have the multisampling method (MSAA), which must improve performance of the method as compared with the SSAA SMOOTHVISION in the R200. However, the first one was also good. The speed of the MSAA version has reportedly become greater - maybe because of the wider bus or the optimized algorithm. In the practical part of the review on the R300 we will carefully examine performance drop issues when FSAA and anisotropic filtering are enabled. It should be noted also that on transparent textures (with an alpha channel) the chip switches to the SSAA mode and select all samples for each pixel of triangle (not only for its edges). It is interesting what NVIDIA is going to offer in its new chip whose various hybrids based on the MSAA look outdated as compared with the SMOOTHVISION. One more significant aspect of the R300 is a VideoShader technology. It uses computational capabilities of pixel pipelines for some tasks of encoding/decoding of MPEG1/2 video streams, conversion of color spaces, deinterlacing and some other video processing tasks. The following diagram shows which tasks fall on the shoulders of the pixel shaders and which are still fulfilled by hardware units: 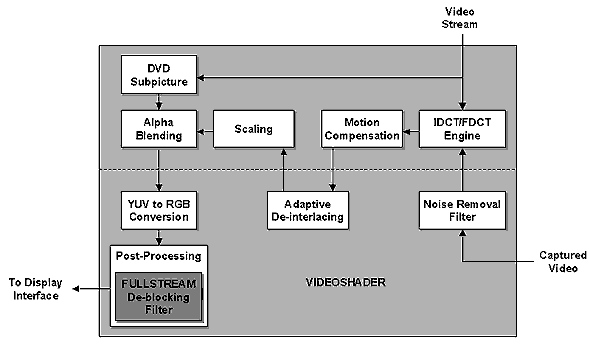 In the near future flexibility and performance of shader processors will let them solve quite complicated 2D video tasks (or, rather, parts of such tasks which are most intensive in calculations) up to MPEG4 decoding. It might also be possible to lay on them sound compression and voice recognition! Why not to use the huge power for turning an accelerator into a general-purpose coprocessor?  ConclusionWell, it's to early to consider ATI and its R300 winners - I'd rather say the company offered the best combination of the price and capabilities with the junior chip of the 9000 line - RV250. It's also unfair to consider the R300 a loser because it is a competitive solution. So, let's wait for the cards and for the DX9.According to the information that is available now and ignoring yet
unknown prices I'd put the competitors into the following order: NV30,
R300. Well, friendship loses again.
Alexander Medvedev (unclesam@ixbt.com)
Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. |














