 |
||
|
||
| ||
|
||
|
||
| ||
Parallel geometry processingLet's get back to the key innovations of GF100. All the previous GPU generations used one unit for fetching, setup and rasterization of triangles. This kind of graphics pipelines provided limited performance and could often be a general bottleneck. Another reason was the complexity of parallelization, given the lack of corresponding API improvements. Such pipelines, with single raster units, used to provide sufficient performance. But the growing complexity and large-scale use of geometry computing made rasterization the key bottleneck of increasing geometry complexity of 3D scenes. For example, active use of tessellation changes the load on various GPU units. With tessellation, the density of triangles grows by factors of ten. This puts heavy load on previously serial parts of the graphics pipeline like triangle setup and rasterization. To provide high tessellation performance, they needed to solve this issue by introducing changes to the architecture and rebalancing the entire GPU graphics pipeline. To achieve high geometry processing performance, NVIDIA developed a scalable geometry processing unit dubbed PolyMorph Engine. Each of 16 PolyMorph units GF100 has contains own vertex fetch unit and a Tessellator. This significantly improves geometry processing performance. Besides, GF100 features four Raster Engines. Those work in parallel and allow setting up up to 4 triangles per clock. Together, these units provide a nice boost to triangle processing, tessellation and rasterization performance. 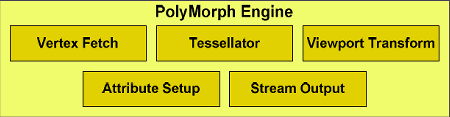 PolyMorph Engine has five stages of operation: Vertex Fetch, Tessellation, Viewport Transform, Attribute Setup, and Stream Output. Results of each stage are transferred to a Streaming Multiprocessor. The latter executes a shader program, returning the data for the next PolyMorph Engine operation stage. After all stages are completed, the results are transferred to Raster Engines. The first stage starts with fetching vertices from a global vertex buffer. The fetched vertices are sent to the SM for vertex shading and hull shading. During these two phases vertices are converted from object space coordinates to world space coordinates. Besides, parameters required by tessellation (e.g., tessellation factor) are calculated and sent to the Tessellator. During the second stage, the PolyMorph Engine reads the tessellation parameters and breaks the patch (smooth surface defined by control points), outputting the resulting mesh. These new vertices are send to the SM, where domain and geometry shaders are executed. The Domain Shader calculates the final position of every vertex based on data from the Hull Shader and the Tessellator. This stage is when a displacement map is usually applied to added detail to the patch. The geometry shader does additional processing, adding or removing vertices or primitives if necessary. During the last stage, the PolyMorph Engine performs viewport transformation and perspective correction. Then attributes are set up, while vertices may be output to memory for further processing by means of stream output. The previous architectures, had similar fixed function operations performed by only one pipeline. Theoretically, GF100 should have both fixed function and programmable operations parallelized. This, in turn, should boost performance if it's bottlenecked by such operations. Raster EnginesAfter primitives have been processed by a PolyMorph Engine, they are sent to a Raster Engine (GF100 has 4 of those). Raster Engines also work in parallel to achieve high geometry processing performance.  A Raster Engine performs three pipeline stages. During edge setup stage, it fetches positions of vertices and calculates triangle edge projections. Reversed triangles are discarded as invisible (back face culling). Each edge setup units processes a single dot, line or triangle per clock. The Raster Engine uses edge projections for every primitive and calculates pixel coverage. If antialiasing is enabled, coverage for every color and coverage fetch is calculated. Each of the four Raster Engines outputs 8 pixels per clock, e.g., 32 rasterized pixels per clock in total. From a Raster Engine pixels are sent to a Z-cull unit. The latter compares the depth of pixels from a tile with the depth of pixels in the screen buffer and discards ones that are positioned behind the pixels in the screen buffer. Z-culling saves resources by eliminating unnecessary pixel calculations. We believe that the new GPC architecture is the most important innovation in GF100's geometry pipeline. Because tessellation requires much higher performance of triangle setup and rasterization units. 16 PolyMorph Engines considerably speed up triangle fetch, tessellation and Stream Out, while 4 Raster Engines provide a high speed of triangle setup and rasterization. In the next parts of the review we'll see if our tessellation estimations are correct. Dedicated Tessellators in every Streaming Multiprocessor and Raster Engine of every GPC should provide up to 8x geometry performance boost compared with GT200. We'll see if this is so. Memory subsystemAn efficiently organized memory subsystem is very important for a GPU today. All the more so because general-purpose computing are drawing more attention. So, NVIDIA's new GPU features a more advanced memory subsystem. GF100 has a dedicated L1 cache in every Streaming Multiprocessor. The cache works together with Multiprocessor's shared memory, complementing it. The shared memory speeds up memory access from predictable-access algorithms, while the L1 cache speeds up access from irregular algorithms in which addresses of requested data is not known by default. 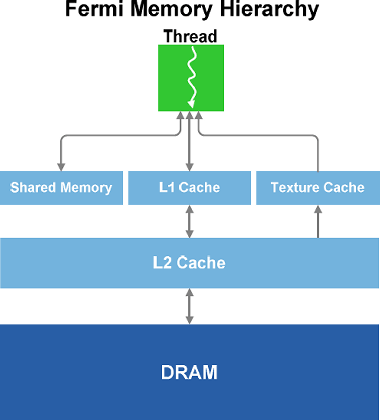 Each Multiprocessor in GF100 has 64KB of onchip memory that can be configured as 48KB shared + 16KB L1 or 16KB shared and 48KB L1. For graphics GF100 uses the first mode, cache working as a register buffer. For calculations, the cache and shared memory let streams of one unit exchange data, working together, thus reducing bandwidth requirements. Besides, the shared memory itself allows using many algorithms efficiently. Besides, GF100 has 768KB of unified L2 cache that handles all requests for loading and storing data, as well as texture fetches. The L2 cache enables efficient and high-speed data exchange across the entire GPU. So algorithms in which data requests are unpredictable (physical computing, ray tracing, etc.) get a considerable performance boost from hardware cache. Besides, postprocessing filters in which several Multiprocessors read the same data get sped up due to fewer data calls from external memory. Unified cache is more efficient than different caches used for different needs. In the latter case there can be situations when one of the caches is used completely, but it's impossible to use other idling caches at that. This may make caching efficiency lower than it's theoretically possible. But the unified L2 cache of GF100 allocates space for different calls dynamically, thus providing higher efficiency. In other words, one L2 cache has replaced texture L2 caches, ROP caches and onchip buffers of the previous-generation GPUs. GF100's L2 cache is used to both read and write data and is fully coherent, while that of GT200, for example, is only used to read data. In general, the new GPU enables more efficient data exchange between pipeline stages and can considerably save external memory bandwidth, increasing the efficiency of use of GPU execution units. New ROPs and improved antialiasingROPs, as well as blending & antialiasing subsystem, of GF100 has also undergone significant changes aimed at improving their efficiency. One ROP section in GF100 contains 8 ROPs -- twice as much as in the previous generation. Each ROP can output a 32-bit integer per clock, an FP16 pixel per two clocks, or an FP32 pixel per four clocks. The key ROP-related drawback of the previous GPUs is low 8x MSAA performance. NVIDIA has considerably improved this mode in GF100, having increased buffer compression efficiency, as well as ROPs efficiency in rendering of small primitives. The latter innovation is also important, because tessellation increases the number of smaller triangles, thus increasing requirements to ROP performance. Image quality is another thing we're interested in. The new GTX 400 series introduce a new antialiasing algorithm 32x CSAA (Coverage Sampling Antialiasing) that enables very high antialiasing of both geometry and semitransparent textures using alpha-to-coverage. In this case 32 stands for 8 fair multisampling fetches + 24 pixel coverage fetches. The previous-generation GPUs only used 4 or 8 fetches that couldn't eliminate aliasing completely and resulted in banding. The new 32x CSAA mode uses 32 coverage fetches that minimize all aliasing artefacts. TMAA (Transparency Multisampling Antialiasing) also benefits from the new CSAA mode. TMAA is usually used in older DirectX 9 applications that do not use alpha-to-coverage, because it's not available in this API. In this case alpha test technique is used that provides sharp edges to semitransparent textures.  The left image shows the best TMAA mode GT200 is capable of: 16xQ with 8 multisampling and 8 coverage fetches. The right image shows TMAA on GF100: 32x CSAA with 8 multisampling and 24 coverage fetches. Using coverage fetches doesn't increase memory bandwidth and size requirements much. In case of GF100 the performance of the 32x CSAA mode is similar to that of the usual 8x MSAA mode, the difference being only 10% or less. Considering there's little difference between 4x and 8x modes, 32x CSAA becomes the best mode in terms of performance/quality ratio. Especially, in case of solutions as powerful as GTX 470 and GTX 480. Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. |














