 |
||
|
||
| ||
|
||
|
||
| ||
Part 2: Graphics card features, synthetic benchmarks
 Contents
OK, we have covered all features of the new architecture in the first part of the article. We know that the new R600 series is currently represented just by a single card:
Three video cards were tested in our lab: the reference card, MSI and HIS models. Running a few steps forward, I can say that they are all practically identical (reference cards).
The author of RivaTuner, Alexei Nikolaychuk, has managed to add support for R600 to his utility (although it was not easy): 
 The second screenshot shows fan speed controls. When set to 100%... my system unit sounded like it started up its jet engine and was about to take off... The fan speed and airflow are unthinkable! The fan noise is not very irritating, but the airflow itself generates much noise. But it happens when you set the fan speed to 100%. In practice, it actually runs at 37% in 3D mode (the cooler is inaudible in 2D mode - it rotates at 25%). But it will be described below.
Video Cards
PCB layout of the R600 card is evidently much more complex compared to R580 (X1950 XTX) owing to the doubled memory bus. Nevertheless, the manufacturer tried to keep the PCB length similar to the old solutions and equip it with an appropriate cooler (of normal dimensions). There are similar HD 2900 XT cards for OEM shipments to system integrators, which are equipped with a bulkier cooling system and a fan, which is installed outside the PCB. So such cards will be 300 mm or longer. But this modification will be available to system integrators only. These cards will not be sold in retail. It should be noted that the card has two connectors for external power supply due to its very high power consumption (above 200 Watt). One of them is not the usual 6-pin connector, but an 8-pin one (PCI-E 2.0). There are no adapters for this connector yet. And we don't need them, because a usual 6-pin cable from a PSU can be plugged into this connector. And the remaining two pins are responsible only for unlocking overclocking (the driver determines if these pins are powered; and if not, it blocks any attempts to increase frequencies through the driver).
The cards have TV-Out with a unique jack. You will need a special adapter (usually shipped with a card) to output video to a TV-set via S-Video or RCA. You can read about TV Out here. We can also note that all top models from ATI traditionally come with VIVO (including Video In - so you can convert video into the digital form). This function here is implemented with the help of RAGE Theater 200, not the traditional Theater:
 Of course, we must note the sterling HDMI support. That's why the video card is equipped with its own audio codec. Its signals are applied to DVI. Then the sterling video/audio signal goes through a bundled special DVI-to-HDMI adapter to an HDMI receiver. The cards are equipped with a couple of DVIs. They are Dual link DVI, so you can get 1600x1200 or higher resolutions via the digital channel. Analog monitors with d-Sub (VGA) interface are connected with special DVI-to-d-Sub adapters. Maximum resolutions and frequencies:
Now what concerns the cooling system. As it's identical in all the three products, we'll examine the reference design:
In the beginning of this part we mentioned 37% of the fan speed, at which the cooler usually runs, remember? But the cooler remains noticeably noisy. The core temperature does not exceed 80°C in this case:
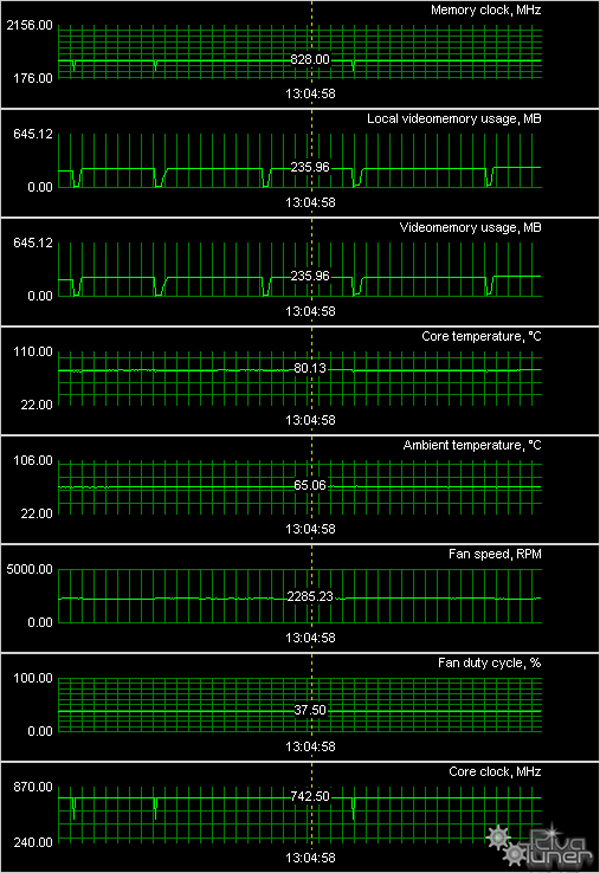
We tried to slow the fan down to 31% (when the cooler noise does not disturb you anymore).
 In this case the core temperature reached 100°C, so the cooler was forced to speed up to 100% (it was howling!) for a short time, and then the turbine settled down to 37%. Fan speed is controlled in big steps. So you can set it either to 31% or 37% (the new version of RT allows to do it). Hence the conclusion that 37% is the required minimum for this cooler to avoid GPU overheating. It cannot run slower. That is engineers were not overcautious in this case. They really set the default 3D mode of the cooler to the minimal level, which does not allow overheating. And this mode is not quiet. That's a big disadvantage of the new accelerator. There is a small consolation: the noise is generated by the airflow, not by the turbine, so its frequency is not very irritating.
Now have a look at the processor.
HD 2900 XT — R600 is manufactured on Week 4, 2007. It's in January. So the chip is 3.5 months old. As the package had to be designed for a 512-bit bus with many pins, engineers had to rotate the die by 45° inside the package. So the aspect is not quite usual :) We are not going to compare GPUs by size (because it will be evidently much larger than R580, and we cannot compare it with G80, because it's covered by a cap). Let's just say that the core is very big and hot (from our experience we know that it's the source of 90% heat from the card, because memory chips operate at frequencies lower than nominal, so they do not get very hot). As all the cards today are samples, boxes and bundles are out of the question. We can only say that the bundle shall include a set of adapters - DVI-to-VGA, DVI-to-HDMI, VIVO, TV cables.
Installation and DriversTestbed configuration:
VSync is disabled.
Synthetic testsD3D RightMark Beta 4 (1050) and its description (used in our tests) are available at http://3d.rightmark.org We used more complex tests for pixel shaders 2.0 and 3.0 — D3D RightMark Pixel Shading 2 and D3D RightMark Pixel Shading 3 correspondingly. Some of the tasks, which appeared in these tests, are already used in real applications. The other ones will certainly appear there soon. These tests can be downloaded from here. Starting from this article, we are planning to use the new version of the benchmark — RightMark3D 2.0. It is written to test Direct3D 10 compatible video cards under MS Windows Vista. Some of its tests were rewritten for DX10, new types of synthetic tests were added: modified pixel shader tests, compiled for SM 4.0, geometry shader tests, vertex texture fetch tests. But after we ran the tests and analyzed their results, we found out that the tests had a number of inaccuracies and mistakes, which had to be fixed for valid comparison. It requires additional time, so we cannot publish the analysis of new test results in this article. But when everything is fixed, we'll publish an article about RightMark3D 2.0, with a lot of cards tested. We apologize for the situation! Synthetic tests were run on the following cards:
We decided to compare R600 with the GTS modification of the G80 card, because it's the official competitor of the HD 2900 XT. When AMD launches a top solution — we'll compare it with the top card from NVIDIA (now it's GeForce 8800 Ultra). Pixel Filling test
This test determines a peak texel rate in FFP mode for various numbers
of textures applied to a single pixel: 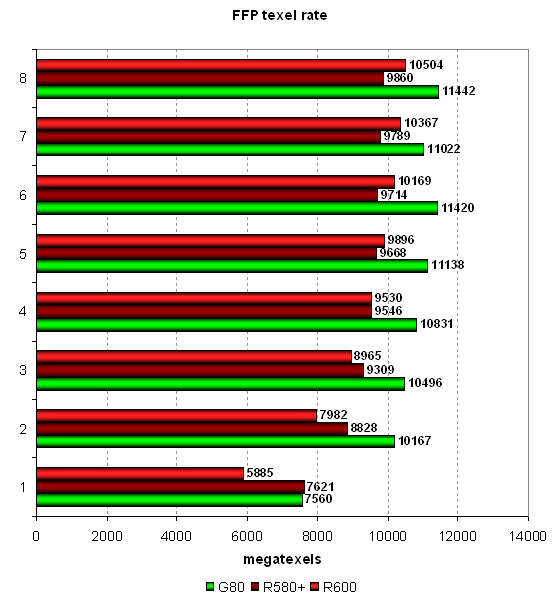 24 texture units in GeForce 8800 GTS and sufficient memory bandwidth, which does not limit performance, provide results similar to theoretical maximum — 12000, especially in modes with a lot of textures. R580+ is also highly efficient, its real texel rate is close to theoretical maximum. Theoretical maximum of the main hero of the review is 12000 megatexels per second, and its result in synthetic tests is 10500. That is its texturing efficiency is a tad lower than in the other models. Judging by our results, the GPU can really fetch 16 texels per cycle for 32-bit
textures and bilinear-filter them. This filter for 32-bit textures
does not lead to a performance drop. Interestingly, in case of a small
number of textures per pixel, R600 is slightly outperformed by R580+.
In heavier conditions it shoots forward, that is the new GPU is more
efficient in heavy modes. 
Only in case of four textures per pixel and more, R600 catches up with its predecessor. That's a bit strange, considering the equal number of TMUs, ROPs and higher frequency. Perhaps, the new architecture is biased towards more texture fetches. It outperforms R580+ in case of many textures, but it's still outperformed by a not so fast NVIDIA GPU in fillrate.
As usual, we'll have this task executed by Pixel Shader 2.0 just for our conscience' sake:
 This time there are no changes, FFP and Shaders 2.0 work in a similar way (perhaps, FFP is emulated by an effective shader), all the cards demonstrate results similar to the previous ones. We shall not publish this graph in our future reviews, if we don't see a significant difference between FFP and PS 2.0. Geometry Processing Speed testWe'll start our tests of execution units with a traditional word of warning: synthetic tests on a unified architecture should be treated with care, they usually load certain units of a GPU, while real applications use all its resources simultaneously. And if a GPU of the old architecture can demonstrate results close to peak values in a well-balanced 3D application, a unified GPU may show worse results in such situations compared to synthetic results. So, let's analyze extreme geometry tests. First of all we'll test
the simplest vertex shader, which shows maximum triangle throughput:
 It's clear why unified GPUs G80 and R600 outperform R580+. Almost
all unified execution units in this test are busy with geometry, which
cannot be expected from a prev-gen GPU. But the results are evidently
limited by the API and platform, not by the peak performance of unified
units, their task is too easy. Our GPUs execute the task with similar
efficiency in various modes, peak performance is little different
in FFP, VS 1.1 and VS 2.0. But G80 shows a significant difference
in FFP mode, almost irrelevant for real applications. Let's see what
changes in a more complex test with one diffuse light source:
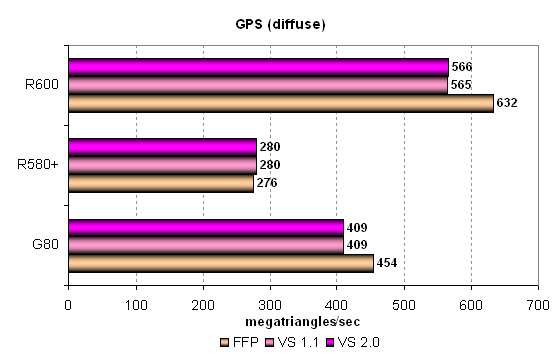 The layout of forces in this test is closer to the real situation, although potential of unified architectures is evidently not revealed completely. Both modern GPUs from AMD and NVIDIA outperform the old GPU of the traditional architecture. It's only natural. This time the FFP mode was faster both in R600 and G80. Perhaps, FFP emulation uses some special units or there are just fewer overheads. Anyway, R600 outperforms G80 GTS by more than one third in all modes. Let's see what happens in heavier modes. The third GPS diagram offers
a more complex lighting computations for a single light source with
the specular component:  The unified architectures break away even further. The leader in geometric performance is R600. The gap between the leader and G80 is larger this time — approximately by 40%. The unified architecture reveals its potential here. We can see that a lot of unified processors are much stronger than 8 vector processors allocated to geometric tasks in R580+. Interestingly, a mixed light source reveals optimized FFP emulation in all GPUs. Let's analyze the most complex geometry task with three light sources including
static and dynamic branching: 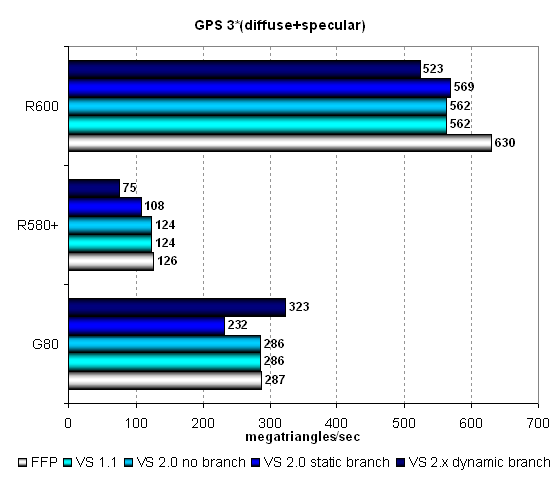 The situation is actually the same as in the previous case, but R600 shoots further forward. The unified architecture of the R6xx GPU is indeed very good at geometry. The more difficult a task, the better its results versus traditional GPUs and even unified G80! R600's results are almost twice as high as G80's ones. By the way, we can again note opposite weak spots of vertex units in AMD and NVIDIA architectures — dynamic branching causes a big performance drop in GPUs from the former company, static branching — in GPUs from the latter. Geometry bottom line: R600 demonstrates very high results in synthetic geometry tests. Owing to its unified architecture and special modifications (enlarged vertex cache, etc) this GPU performs well in such tests. It can use all its unified stream processors to solve geometry tasks. The new unified architecture from AMD illustrates its capacities especially well with complex vertex shaders. What is left for us now is to see what happens in real games, as most of ALU work will consist in executing pixel shaders, not vertex ones. Pixel Shaders TestAs we didn't include GPUs of old NVIDIA architectures, which gain advantage when the number and precision of temporal registers is reduced, we haven't published FP16 results here. Today all tested solutions execute pixel shaders with reduced precision at the same speed as FP32. The first group of pixel shaders is too simple for modern GPUs. It includes
various versions of relatively simple pixel shaders: 1.1, 1.4, and
2.0.  These tests are too easy for G8x and R6xx, of course. They cannot show us the worth of unified architectures versus R5xx. The new GPUs do not gain noticeable advantage over one of the most powerful GPUs of the traditional architecture in such simple tests, as it has a lot of pixel processors. Performance in the simplest tests is limited by texture fetches and fillrate. G80 wins here. But R600 shoots forward in more complex PS 2.0 tests. The more complex a task, the wider the breakaway from competitors again. Let's have a look at results in more complex pixel programs, somewhere between
SM 2.0 and 3.0: 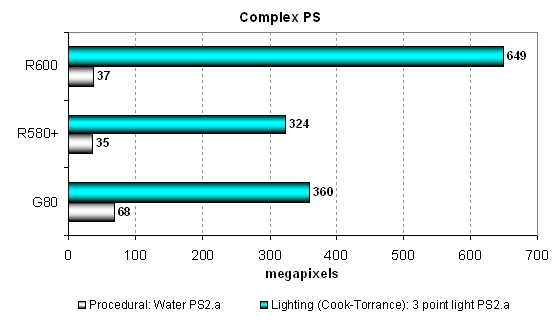 The water test, which is more dependent on texelrate, uses dependent fetch of deeply nested textures. G80 is second to none here, neither among old AMD GPUs, nor among new models. Similar results of R580+ and R600 prove that they are strongly dependent on TMU speed. But in the second test (more compute-intensive) R580+ almost catches up with the junior modification of G80, and R600 shoots far forward. Many unified processors in R600 counted. Perhaps, this task matches its superscalar architecture well. New Pixel Shaders testsThese tests were introduced not long ago, they are more complex than the above tests. In fact, we are planning to give up early synthetic tests with outdated shader versions (below 2.0) and use HLSL Shaders 2.x, 3.0 and 4.0. Performance of old shaders can be tested in games that have been using them for a long time already, while synthetic tests must face the future. These tests are divided into two categories. We'll start with easier shaders, SM 2.0. Two tests are added here, they implement effects that are already used in modern 3D applications:
Both shaders are tested in two modifications: arithmetic and texturing. Let's
analyze arithmetic-intensive variants, they are more promising from
the point of view of future applications:  The situation resembles the previous group of tests, but there are some differences. The leader in the Frozen Glass test is G80 (1.5-times as fast). Both solutions from AMD are on a par. So we can assume that the performance is limited by texelrate, as texture fetches are inevitable in any tests, especially in real 3D applications. Parallax Mapping demonstrates a reverse situation — G80 and R580+ are approximately on a par, while R600 is 1.5 times as fast as those two cards. See what different tests with different load on TMUs and ALUs mean. One test favors this architecture, the other one favors that one. Let's analyze texturing-intensive modifications of the same tests: 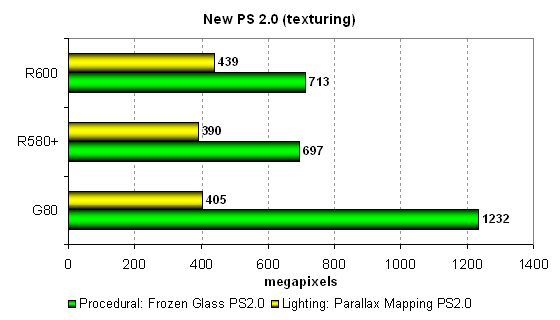 The situation changes here. Performance in these tests is limited by the speed of texture units, so AMD solutions in the Parallax Mapping test come close to G80. And NVIDIA's GPU has become even faster in the first test relative to its competitors. These diagrams show that the arithmetic-intensive modification of the shader works faster on all GPUs. The texturing-intensive modification makes no sense for modern GPU architectures. Even though the unified G80 chip is fast at texture fetches, it still "favors" computing more than texturing, to say nothing about AMD(ATI) solutions that traditionally prefer arithmetic. What concerns real applications, everything depends on preferences and decisions of programmers. To reveal potential of the new architectures, they have to choose compute-intensive algorithms. Now we are going to analyze results of another two tests of pixel shaders — Version 3.0, the most complex of our synthetic tests of pixel shaders for Direct3D 9. These tests generate much load not only on ALUs, but also on texture modules. Both shaders are relatively complex, long, with lots of branches:
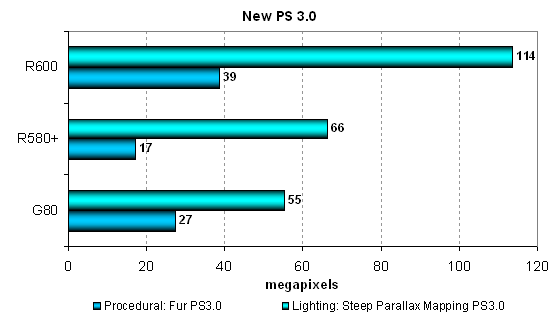 These tests generate much load even for such modern GPUs as G80 and R600. But R580+ does not fade into the background, it demonstrates results on the level of GeForce 8800 GTS, being left behind in one test, and outscoring this solution in the other. Obviously, all architectures work well with dynamic branches in pixel shaders. They are perfectly fit for such tasks. But we can also see that R600 provides the most efficient usage of our complex pixel shader (Version 3.0) with many branches. Its advantage over G80 reaches 1.5-2 times. Conclusions on pixel shader tests: R600 is based on the efficient computing architecture, perfectly fit for executing complex pixel shaders. The more complex arithmetic computations and branches in a task, the more efficient the new architecture from AMD versus the others. Unfortunately, R600 is short of some texture units for absolute leadership - they are important even in synthetic tests of pixel shaders, to say nothing of real games, where texelrate has a stronger effect. We'll have a look at test results of RADEON HD 2900 XT in modern games (published in the next part of the article) and see whether our assumptions are true. Point Sprites test
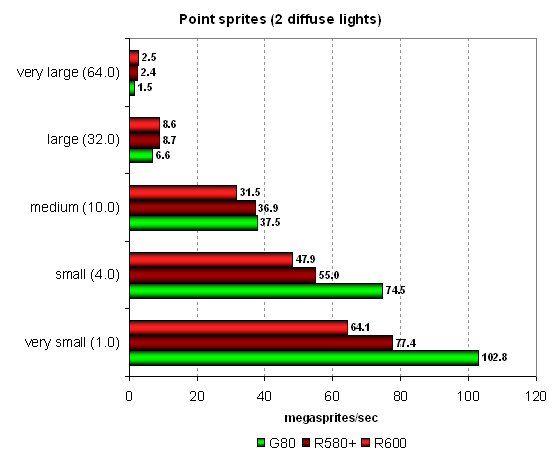 Let's analyze the operation of point sprites, which are used in a few real applications in different conditions. Results of all our previous tests are confirmed — NVIDIA GPUs outperform AMD solutions in case of small sprites owing to more efficient operations with a frame buffer. But as sprite size grows and lighting gets more complex, the latter start to win. R600 performs in this test just like the previous solutions from the company, there is nothing interesting here. In fact, this tests with small sprites is limited only by the fillrate. It does not demonstrate interesting results. So we are planning to give it up in future reviews and use new Direct3D 10 tests instead. Conclusions on the synthetic tests
So, AMD offers a very powerful unified architecture for PC, which is evidently designed for complex computations. Besides, it should scale well. Solutions for other price segments, to appear later, must be quite good. Especially as they will be manufactured by a perfected process technology and thus gain additional advantages. We have several questions only about not very many ROPs and especially TMUs in all solutions from this series. Can this potential weakness become a reason for vague results in our present game tests, which depend much on texelrate as well as fillrate? Of course, DirectX 10 tests and games await us in future. They will show the real worth of the new solutions. It's up to them to reveal the true potential of the new architectures from AMD and NVIDIA. But we shouldn't forget about modern games either... In the next part of our article we are going to test the new AMD solution in modern games and see how valid our synthetic conclusions are. The gaming part is actually the main part of this article, you should choose a video card judging by its results in real games. Part 3. Game benchmarks
Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


































