 |
||
|
||
| ||
|
||
|
||
| ||
In comparison with ATI's products targeting the same niche, performance of pixel and vertex shaders of NV3X based solutions is noticeably lower and turns out to be a bottleneck in real gaming applications that intensively use pixel shaders 2.0. NVIDIA's new drivers (v50.XX and higher) include enhanced and optimized compilers of vertex and pixel shaders, support for new texture formats and some other optimizations that do not affect image quality but foster the rendering speed. In this express test we will compare performance of drivers v40 and v50 to reveal how optimized the vertex and pixel shaders are in the new driver generation. We tested an average-level card based on the GeForce FX 5600 Ultra 128 MB clocked at standard core and memory frequencies. As usual, we used the latest release of the DirectX 9 and the Windows XP Professional OS. The new text version with a user-friendly interactive interface and source texts are available at http://www.rightmark3d.org/d3drmsyn/ I hope that due to the source texts of the test modules the D3D RightMark will be of interest both for those who want to measure their cards' performance and for those who want to develop their own test (originally compatible with the convenient shell) without programming time-taking interface functions such as data representation or parameter configuring. Look, comment, make your remarks! Before reading this review we recommend that you have a look at the previous tests with the synthetic benchmarking involved:
This article is an express addition to the reviews listed above. Pixel Shaders 2.0The tests were carried out at 1280*1024 to reduce influence of other factors. The vertical sync was turned off. The number of benchmarks was limited (abundance of the same data doesn't make the picture clearer) to five:
All the tests were carried out in 4 modes:
Here are the test results. Normalization based on the Cube Maps: 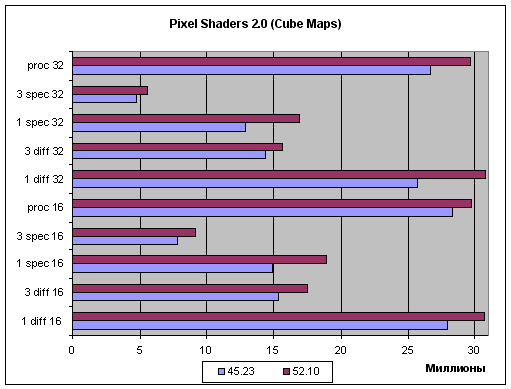 (in Millions) and normalization based on arithmetic operations: 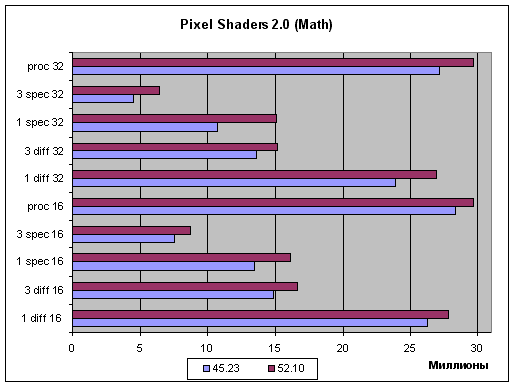 (in Millions) The X-axis gives Millions of pixels per second. Obviously, both tests have a noticeable performance gain with the new-generation drivers. It doesn't signify total or selective degradation of calculation accuracy as the performance grows also in the 16bit mode where there's no room for further decreasing of accuracy. Let's analyze the diagrams. First of all, I can't say that optimization touches mostly short or mostly long shaders as the performance grows more or less equally. But I must say that a long complex code is better optimized, the scores grow better in case of one complex light source and in case of the big procedural texture generation program, while three simple sources (the code of which repeats three times in the shader body) were less optimized. Optimization takes place both in case of the tables and in case of the arithmetical operations, but the latter benefit more. The texture access doesn't get faster with the new shader compiler but calculations can get a solid gain due to more optimal distribution of time registers (which have a great effect on performance of shader processors of the 3X family) and other approaches typical of all optimization compilers. It's also logical that in 32bit mode the optimization boosts performance to a greater degree. We know that the penalty for each superflueous time variable is twice greater in this case, that is why the effect from the optimization is clearer. So, the PS2 compilation is much optimized. I wonder if the guys at NVIDIA will be able to lift the performance even more in the next driver version. If you remember, the speed of the first R3XX drivers was too low until the drivers were optimized. But it's hardly possible to double the speed, and 20% is the developers' considerable achievement. Geometrical performanceThe tests were carried out at 1024*768 in the following modes:.
Emulation of the fixed TCL (also known as FFP - Fixed Function Pipeline), vertex shaders 1.1 and 2.0. TCL emulation: 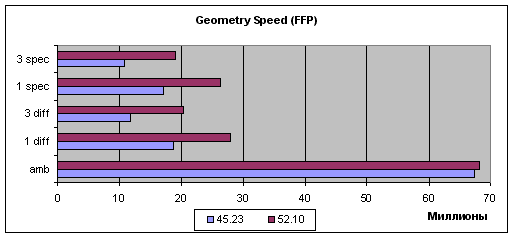 (in Millions) Shaders 1.1: 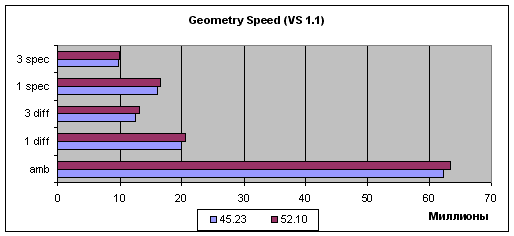 (in Millions) Shaders 2.0: 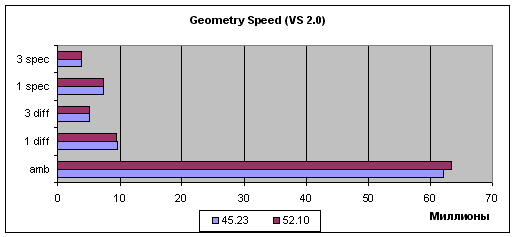 (in Millions) Judging by the simplest case (Ambient), i.e. by the peak performance, there's a kind of optimization but it's related rather with geometrical data transfer procedure than with vertex shaders. In case of more or less intensive geometrical calculations (other tasks) the gain is achieved only with the vertex shaders 1.1, though it's still anyway. In case of VS2.0 the performance drops twice again when loops are used (the only difference between shaders 1.1 and 2.0 in this test). That problem wasn't solved yet by the developers at NVIDIA - it's likely that such a great speed drop incomparable to known loop realization methods (as there's only one loop operation executed per dozens of other computational tasks, the difference should be tens of percent, not hundreds) is caused by hardware problems related with the accelerator architecture and can't be solved on the driver level. Well, hardly any of game developers would want to doom their vertex shaders to the twice slower performance. It's also interesting that the good old inflexible TCL benefits a lot in real tasks with several light sources. That's very good news as there are still many applications that fully or partially use the TCL for rendering geometry; moreover, the tasks of modern and upcoming games that do not use vertex shaders can be accelerated this way on NVIDIA's chips. So, the TCL emulation controlling shader integrated into the drivers is greatly optimized, which is definitely to the benefit of applications using TCL. On the other hand, the performance of the vertex shaders 1.1 didn't grow up much while the VS2.0 are as speedy as they were before. The problem of the VS2.0 the speed of which falls down twice in case of loops in the shader isn't solved yet. Finally we've got diagrams demonstrating dependence of geometry processing speed on scene complexity (three complexity levels - low, mid and high for vertex shaders 1.1 and 2.0): 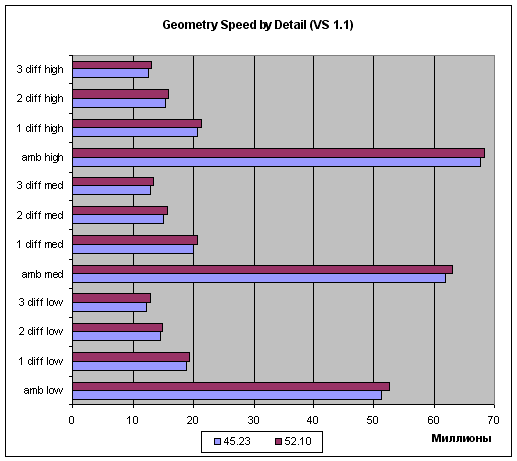  As you can see, the scenes with a higher detailing degree are preferable in case of simple tasks, but the gap disappears in case of more complex tasks (and longer shaders). ConclusionThe final verdict will be voiced after the release of the official version
the the v50 drivers, which will most likely be WHQL certified. But I'm
sure that we should expect some improvements in the pixel shaders 2.0 (which
are the weakest point of all NV3X chips) and in the TCL emulation. The
figures won't be too high or low but the gain will be noticeable enough
in real applications. HOwever, the drivers are not a cure-all for NVIDIA,
and the real solution of the problem can be found only in hardware, be
it NV38 or, more likely, NV40.
Alexander Medvedev (unclesam@ixbt.com)
Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. |














