 |
||
|
||
| ||
|
||
|
||
| ||
[ Part I ]

The NV25 chip was awaited for a long time by many as an echo of 3dfx's deals, as a competitor against ATI RADEON 8500 and as the second optimized and enriched incarnation of NV20. Let me dive directly into the root of the matter... Attention! Before reading the review you should turn to the previous articles on NVIDIA GeForce3 (NV20) and ATI Radeon 8500 (R200). Product lineThe GeForce 4 line is based on two chips - NV17 and NV25 which is the today's main hero:
Note:
This pretty monster will help promoting and advertising NV25 based products demonstrating advanced soft illumination, skeletal animation, hair and fur made of vertex shaders and per-pixel relief:

TheoryNV25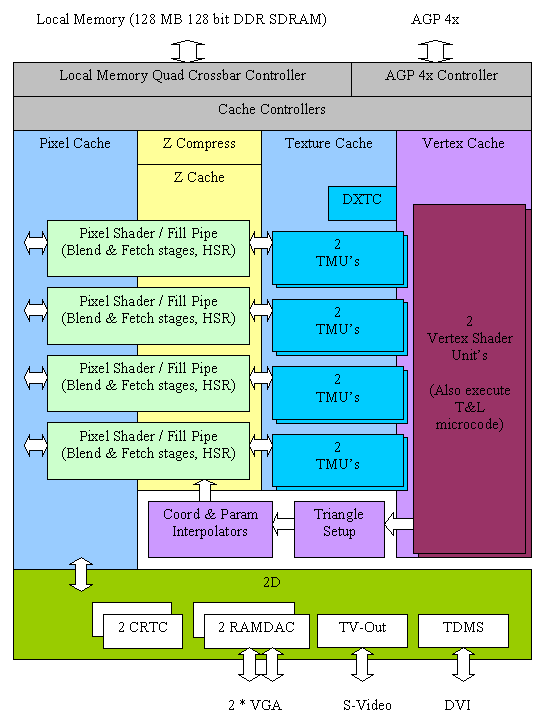
Main architectural innovations of the NV25 (vs. NV20)
Further we will check all these declared advantages of the new chip. The above changes are rather evolutionary rather than revolutionary as compared with the previous NVIDIA's product (NV20). But it is typical of NVIDIA to release first a product carrying a great deal of new technologies and then its improved (optimized) variant. Just take TNT and TNT2, GF256 and GF2, and now GF3 and GF4. The experience shows that usually the second variant meets with great success. Performance characteristicsFirst of all, a bit of explanation:
And now take a look at the summary table of the key characteristics of the chips and cards tested today. Keep in mind that in the nearest quarter the ATI RADEON 8500 will be a main competitor of NV25 based cards (GeForce 4 Ti 4600 and Ti 4600) because of the postponed release of RADEON 8500XT and because first R300 based products won't appear very soon.
Comments:

Here is a complete list of OpenGL extensions supported by the NV25 in the current drivers: GL_VENDOR: NVIDIA Corporation GL_RENDERER: GeForce4 Ti 4400/AGP/SSE2 GL_VERSION: 1.3.1 GL_EXTENSIONS:
The same list in the latest drivers of the R200: GL_VENDOR: ATI Technologies Inc. GL_RENDERER: Radeon 8500 DDR x86/SSE2 GL_VERSION: 1.3.2475 WinXP Release GL_EXTENSIONS:
The most of NV25 extensions remained standard which means a stronger influence of NVIDIA on the OpenGL. Now let's turn to the video cards based on two NV25 versions: GeForce4 Ti 4400 and 4600. CardsBoth models are reference cards based on the NVIDIA GeForce4 Ti 4400 and 4600. The look very close to each other, though there are some differences. Besides, the Ti 4400 chip works at 300 MHz instead of 275 MHz of production cards. The frequency of the Ti 4600 correspond to the planned one. The cards have an AGP x2/x4 interface, 128 MBytes DDR SDRAM located in 8 chips on the right and back sides of the PCB.
 
The cards are equipped with memory chips of the BGA form-factor from Samsung. Access time of the Ti 4400 is 3.6 ns which corresponds to 275 (550) MHz.

Access time of the Ti 4600 is 2.8 ns which corresponds to 357 (714) MHz.

The cards use memory chips in a new BGA package. This form-factor provides more effective cooling of chips and memory (the GeForce4 Ti 4600 operates at a frequency a little less than the rated one for 2.8ns). Frequencies of our samples (core/memory) are:
Despite a high frequency of the chips and memory they do not warm up much, especially the memory chips. That is why I think that no additional cooling for memory will be provided on production cards. Let's return to the differences between the cards: NVIDIA GeForce4 Ti 4400


NVIDIA GeForce4 Ti 4600


There are differences only in the right part which has a power transformation unit. The memory chips and the GPUs have different voltage levels and consumption currents. Take a look at the cooler on the GPU:


Air is pumped through a channel with a fin heatsink by a fan located to the left. The reference card based on the NVIDIA GeForce4 Ti became larger (Hercules 3D Prophet III Titanium 500 based on the reference design of GeForce3 Ti 500 is used for comparison (below)):

Compare the dimensions of the GeForce4 Ti and 3dfx Voodoo5 which is the largest gaming video card:

As you can see, our card is just a bit smaller.

The dual-head support is a distinguishing feature of this card from the previous ones. The most powerful accelerators from NVIDIA had never the TwinView support before (now this option is called nView). Look at a size of the VGA (d-Sub) connector. There is also space for the second DVI connector which will probably be in great demand in the near future. Below the VGA connector is a TV-out with an S-Video connector. The video-interface chip for this function is located on the back side of the card and is marked as CX25871 (up to 1024x768 supported); the chip is produced by Conexant. As the TV-out interface is integrated in the GPU the production samples will probably lack for this chip. In the lower part of the card we have a DVI connector (digital/analog) which generates a signal for the second analog CRT monitor (a DVI-to-VGA adapter is used):

Later we will examine the dual monitor support in detail. OverclockingIt is obvious that it makes no sense to overclock the junior model (Ti 4400). The GeForce4 Ti 4600 can operate stably at 320 MHz of the GPU and 365 (730) MHz of memory. The overclocking potential is just 20 MHz (it is possible that it depends on a sample), and the memory showed an excellent reserve taking into account that it is produced by Samsung. We were also able to overclock the 3.6ns memory on the TI 4400 up to 300 (600) MHz . Note:

Test system and driversTest system configuration:
The test systems were coupled with ViewSonic P810 (21") and ViewSonic P817 (21") monitors. In the tests we used NVIDIA's drivers v27.20 and 27.30. VSync was off, S3TC was activated. For the comparative analyses we used the following cards:
Driver and nView settingsIn the tests we used v27.20 and v27.30 drivers (both versions are identical regarding an interface and speeds, that is why we will address settings of only v27.20 for the Windows XP).

Here we have a new AA level - 4xS. It appears only for new cards based on the NV25.
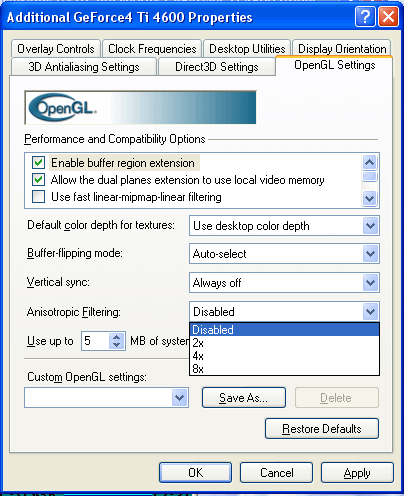
Now it is possible to adjust anisotropic filtering in the OpenGL. However, its feature is avaialble starting from v23.*.
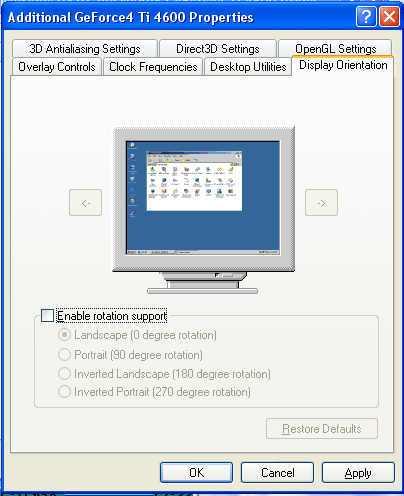
A new feature allows to rotate an image at 90 degrees which is very helpful for designers working with LCD displays. Unlike program packets which are able to rotate an image by 90 degrees this feature is implemented on the GPU level, that is why it doesn't slow down 2D displaying and makes no compatibility problems with new OS versions.
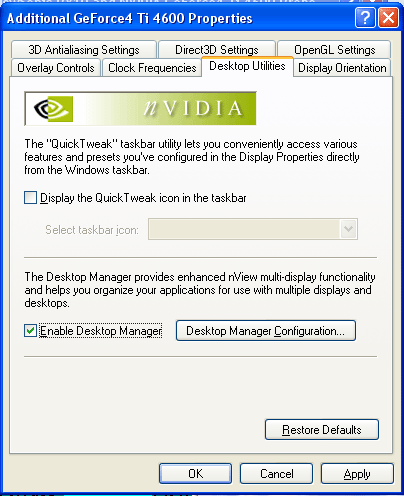
nViewnView is a data displaying management system. It consists of two parts:
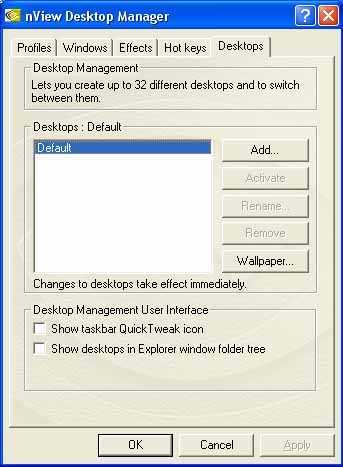
In the Desktop Manager mode we can create several (up to 32) virtual desktops on one screen:
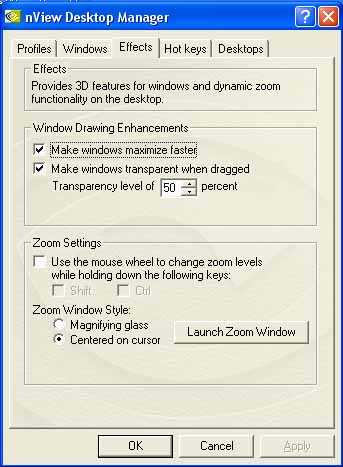
Besides, we can manage windows, effects when working with the latter ones etc.:
Then you can create your own profile and safe there all made settings:
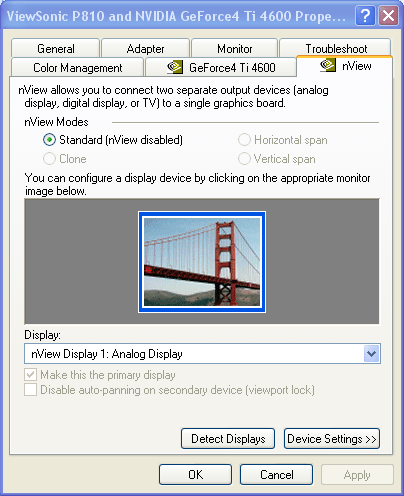
The most interesting function is dual monitor support. We already saw the TwinView function on the GeForce2 MX cards, that is why this tub isn't new for us:
Apart from the Clone mode there are others.

Of course, there is an Extended mode which allows a second display device to become an additional part of your desktop real estate. You can also adjust DVC settings (digital vibrance control) for each monitor separately (it is shown on the shots below: first DVC is enabled on the left screen, then on the right one):
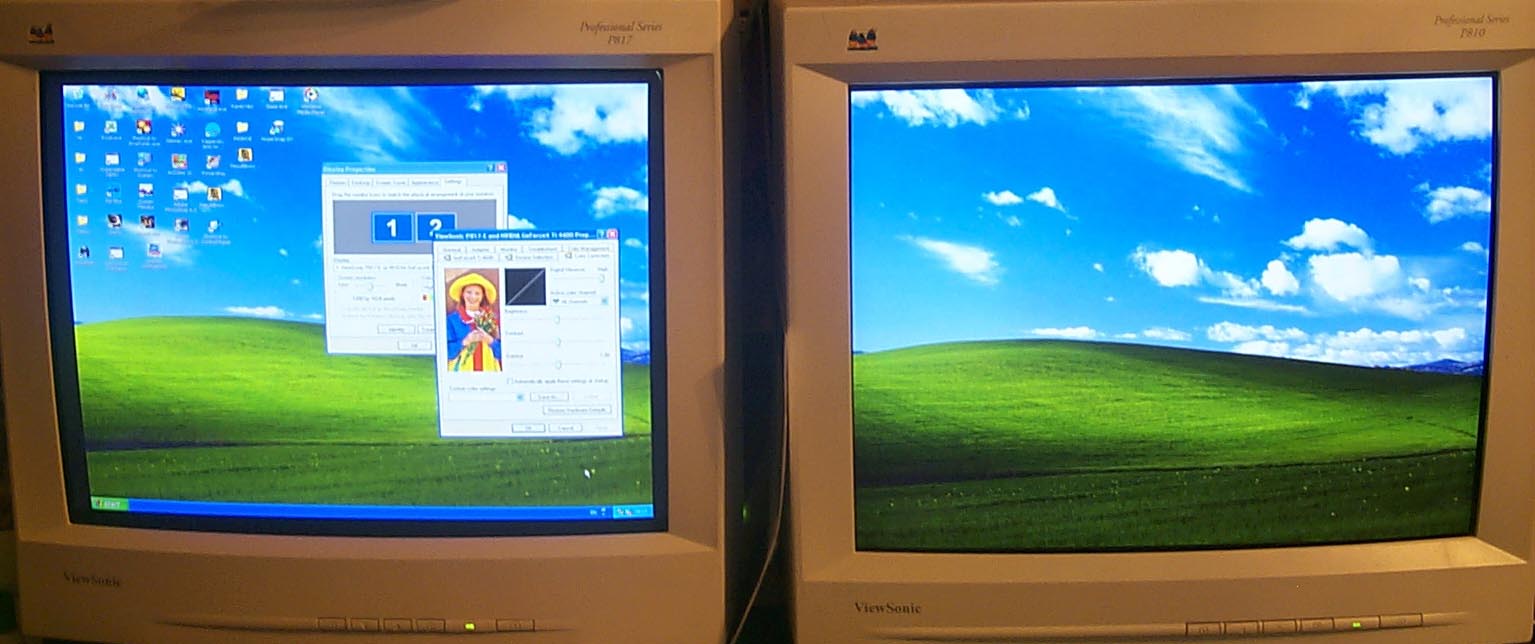

The horizontal and vertical span mean that the desktop together with a control panel is just spread onto the second monitor,
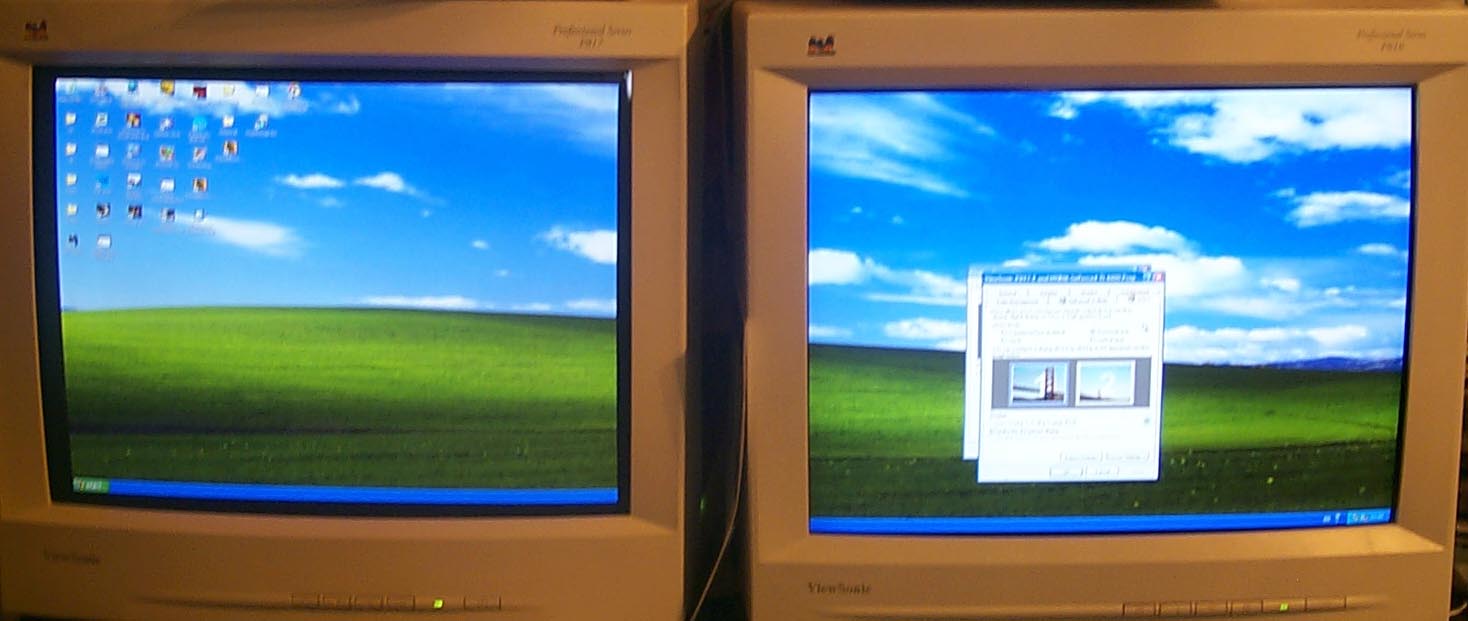

Extension of the desktop allows many users to achieve their dream - to work on the first monitor and watch movies on the second one. It becomes really possible if you use TV-out as the second monitor.
To make the above shot we used a WinDVD player started on the primary monitor, then dragged to the secondary window and switched to the full screen. If DVD playback protection will get enabled on the secondary monitor to some reason, you can open a DVD window on the primary monitor and then interchange the primary and secondary receivers in the drivers. By the way, the NV25 doesn't support the MPEG2 hardware decoder. In our "program" case with the latest WinDVD version the CPU utilization wasn't more than 18% (the nView was activated). Test results2D graphicsImage quality in 2D is excellent. You can work comfortably in 1600x1200 at 85 Hz. I think that the quality of the Matrox G400/G450 is achieved in this respect. Remember that estimation of 2D quality is subjective and depends on a certain card and on compatibility of a video card and a monitor. 3D graphics, MS DirectX 8.1 SDK - extreme testsWe used modified examples from the latest version of the DirectX SDK (8.1, release). Optimized MeshThis test demonstrates a practical limit of an accelerator's throughput when triangles are used. Several models are displayed simultaneously in a small window, each consisting of 50,000 triangles. No texturing. The models are minimal in size: each triangle is not greater than 1 pixel. Such result can not be obtained for real applications where triangles are usually large and where lighting textures are used. Below there are results for three drawing methods - Optimized for an optimal drawing speed (taking into account an internal cache of vertices on the chip), Unoptimized and Strip (when one Triangle Strip is displayed):
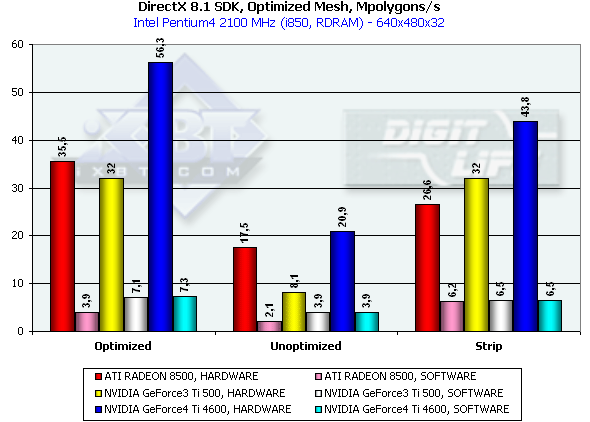
In the first case, Optimized model, the memory subsystem doesn't have a great effect, and we measure a pure performance of transformation and drawing of triangles. The Ti 4600 (NV25) thrives. 56M triangles/sec is a twice higher result as compared with the RADEON 8500 and Ti 500. This is achievement of the second T&L unit. In case of the Unoptimized model we measure efficiency of caching and of memory bandwidth. The result of the NV25 is proportional to the difference in frequencies of the R 8500 and Ti 4600. In case of the Strip the R200 loses; the NV25 beats the NV20 in accordance with the frequency difference. The NV20 and NV25 performs better when the program geometry calculation is activated forcedly. The NVIDIA chips have an advantage thanks to the FastWrites mechanism which transfers graphics data directly into the accelerator from the processor passing by a system memory. In case of the Strip there is no more such advantage because a data rate is twice lower. Performance of the vertex shader unitThis test demonstrates an ultimate performance of the vertex shader unit. A complicated shader calculates both specific transformations and geometrical functions. The test is carried out in the lowest resolution to minimize a shading effect. Z-buffer is off, and the HSR can't affect the results as well:
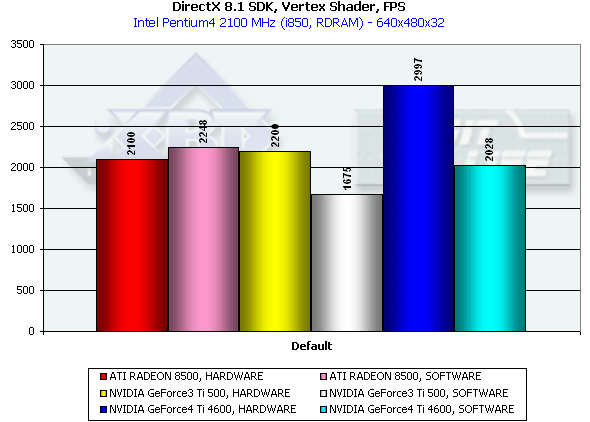
The dual T&L of the NV25 is beneficial again. Besides, one of the most powerful CPUs loses in a speed of graphics data processing. The NV25 has a more efficient delivery of geometry calculated on a program level as compared with the NV20 (the drivers are equal for both chips). The R200's speed of processing of vertex shaders has grown twice and it is now equal to the program emulation speed. This time we decided to check whether the R200 processes vertex shaders on a program level and lowered the clock frequency to 1 GHz. The results (HARDWARE 1860, SOFTWARE 1470) show that they are processed on a hardware level. Well, ATI was able to optimize the drivers successfully. Vertex matrix blendingThis feature is used for true animation and skinning of models. We tested blending using two matrices both in a tough hardware variant and using a vertex shader with the same function. Besides, we obtained the results of the T&L program emulation:
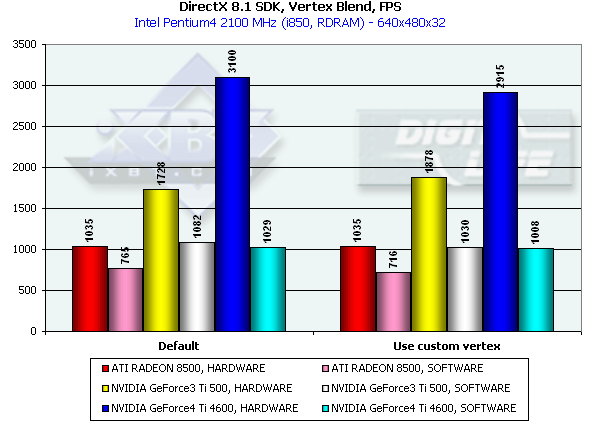
This time the program emulation loses to the hardware implementation being limited by the graphics data rate via the AGP. As I mentioned before the NVIDIA products has some advantage thanks to the FastWrites support. This time (vs. the last big test of the R200) in case of the hardware implementation the shaders go on a par with the hardware blending, and now it makes no sense to use the latter on modern chips. It is interesting that the tough hardware blending is a bit slower on the NV20 and a bit faster on the NV25 than the shader one, but the difference is insignificant, which is reasonable as neither NV20 nor NV25 have a fixed T&L. In fact, functions of this unit are implemented by a special shader microcode, and equality of the results shows that optimization of the driver-compiled shaders is optimal. EMBM reliefThis test measures a performance drop caused by Environment mapping and EMBM (Environment Bump). We tested in 1280*1024 as exactly in this mode difference between cards and texturing modes is the most vivid:
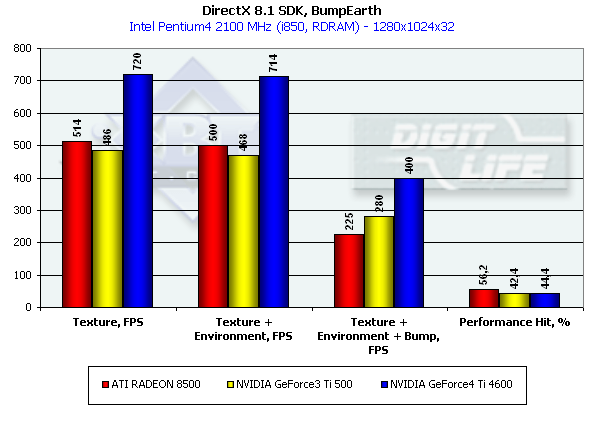
The Ti 4600 outscores all other cards in an effective fillrate in all three modes. The R200 suffers most from the EMBM. The NVIDIA chips shade much more efficiently especially if we take it per unit of clock frequency - 240 MHz of the NV20 will be, thus, equal to 275 MHz of the R200. Performance of pixel shaders Again we used MFCPixelShader and measured performance of the cards in the high resolution using 5 shaders different in complexity for bilinear filtered textures:
The Ti 4600 is again riding high, and the dependence on the shader complexity and on the number of textures is very similar to the previous chip (NV20). The R200 looks weak, especially when fulfilling complex tasks. Reuse of texture units is dearer for it than for the NVIDIA products. Well, in the DX 8.1 SDK tests the NVIDIA GeForce4 Ti 4600 is an undoubted leader. However, remember that only real applications will allow us estimate an overall balance of this chip. Stay tuned! 3D graphics, VillageMark (HSR efficiency)To estimate realization of the HSR we used a test with a high OverDraw level - VillageMark v.1.17. Here are the results of both cards with enabled and disabled HSR:
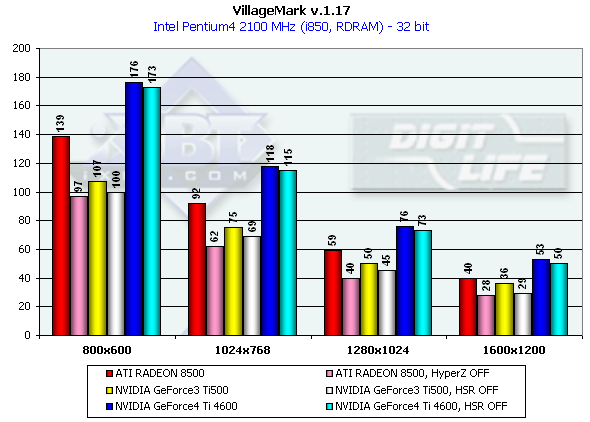
Apart from obvious advantage of the NV25 in 1280x1024, the performance drop with the HSR disabled is quite small both for NV25 and NV20. But it doesn't mean that the HSR is less efficient. If for the R200 card we disable the HyperZ completely (including HSR, Z compression, fast Z-clear), for the NVIDIA cards we could disable only the Z compression, while the HSR (Z-Cull) is disabled in the 27.XX at default and can be activated with the help of keys in the register. On the whole, the NV25 performs better in the scenes with a high overdraw parameter. It should be noted that the scene in this test is drawn not from the depth layer by layer but 'as is', that is why HSR of non-tile chips which performs best in this way of scene drawing doesn't have a great effect in comparison with tile architectures which sort a scene on a hardware level. As the most of real applications display scenes without sorting polygons we consider this test quite correct. 3D graphics, preliminary test based on the iXBT/Digit-Life RightMark Video AnalyserAt the moment we are developing a 3DMark-like packet the tests of which will be freely available. We have created a little preliminary test based on one scene and an engine which will be a base of this packet. The test will have complicated geometry (over 150,000 polygons in a frame) and wide utilization of DirectX 8.1 features. Lighting is based on vertex shaders, shading - on pixel ones, EM and EMBM are used widely, i.e. up to 4 textures are put over one pixel. Besides, the Shadow Buffer technology is used to calculate shadows of objects in a real-time mode. The test doesn't depend much on a processor (later we will return to strong dependence on a processor in the 3D Mark 2001 in all High Detail scenes). Here are some screenshots:



Test results:
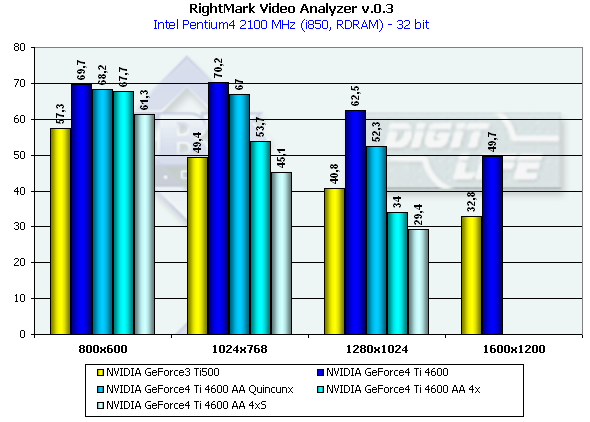
The test doesn't depend much on resolution because of very complicated scenes and a big load on the geometrical part of the accelerator. But when AA is enabled which influences positively visual quality of the scenes with a great number of small polygons resolution becomes important. I think that resolution won't be a problem soon and all applications will be focused on flexibility of more and more complicating geometry. It is interesting that again in 1280*1024 the gap between the NV25 and the NV20 is the largest. The increased memory bandwidth and its doubled size helped the NV25 much in this mode. Note that this mode is typical of 17" and 18" monitors. 3D graphics, 3DMark2001 - synthetic testsFillrateWe measured this parameter only for 32-bit color depth:
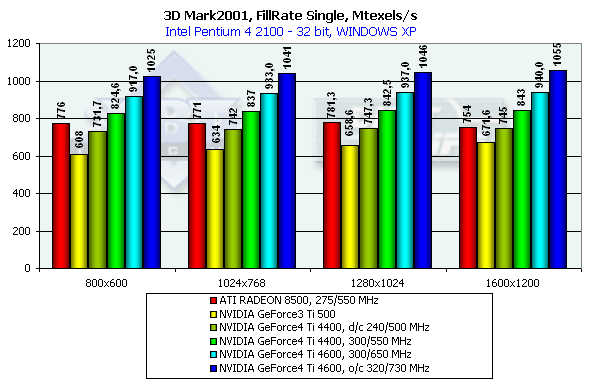
The NV25 is again a leader. It is of really great interest to compare shading efficiency of the NV25 operating at the rated frequency of the Ti500 (240/500). The gain is noticeable, that is why architectural optimization of the fill pipeline and memory controller is also significant. The theoretical limit of this test is 960M pixels/sec for the Ti 500, 1100 for the RADEON 8500 and 1200 for the Ti 4600. This time the NV25's architecture approaches the theoretically maximum fillrate comparable to the R200. Despite the same production technology and just a little greater number of transistors the NV25 easily outdoes the NV20 both in the limiting working frequency and in efficiency of operation at the same frequency.
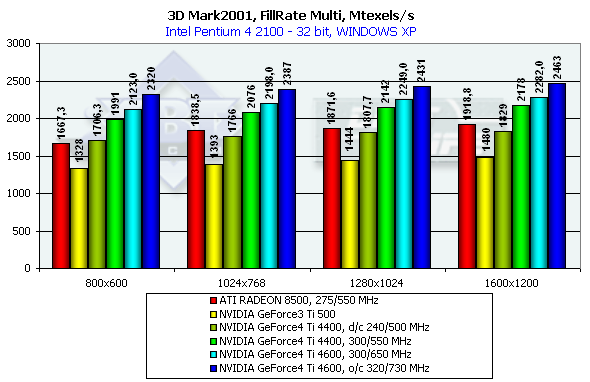
In case of several textures the chips have drawn much nearer to the theoretical limit. The best result of this test can be achieved at the highest resolution. Scene with a great number of polygonsRemember that in the highest resolution the dependence on a fill rate almost disappears:
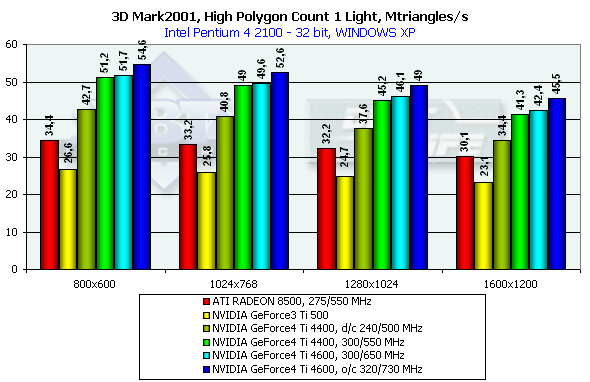
The NV25 becomes a leader when one light source is used. Its result is very close to the practical limiting bandwidth for triangles obtained earlier with the Optimized Mesh from DX8.1 SDK. You can see that the overall efficiency has increased due to the second shader unit if you compare results of the NV25 and NV20 at the same frequency. The R200 also came very close to the limiting value obtained in the SDK test, but it considerably falls behind in the absolute value, although the core frequency is almost equal to the NV25.
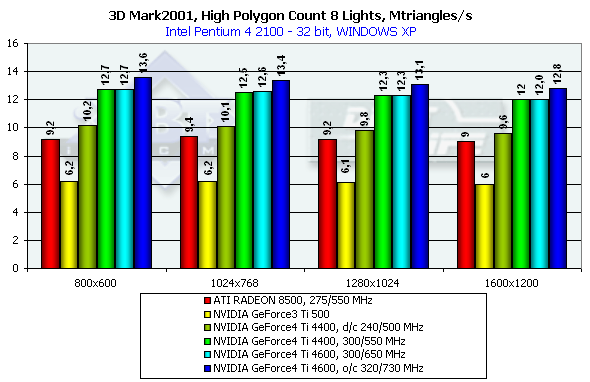
In case of 8 light sources the performance of the R200 falls down slower as compared with the NV20 and NV25, though the palm still belongs to NVIDIA. Relief texturingLook at the results of a synthetic EMBM scene:
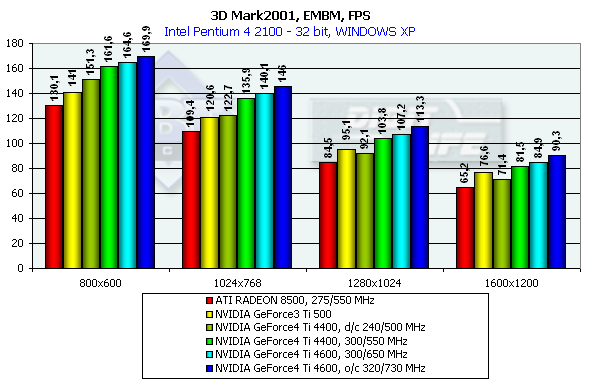
The results reflect EMBM mostly in high resolutions; in 800x600 the the determining factor is geometry. It is interesting that at the same frequency the EMBM is implemented by the NV25 slower than by the NV20 - probably it is a cost of optimization of the fill pipeline which is very effective in case of usual shading and especially beneficial when the MSAA is enabled. And now comes the DP3 relief:
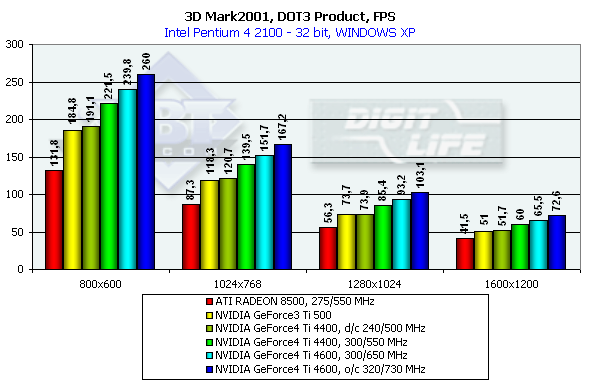
The NV25 again leads. Vertex shadersThe test results are shown for several resolutions.
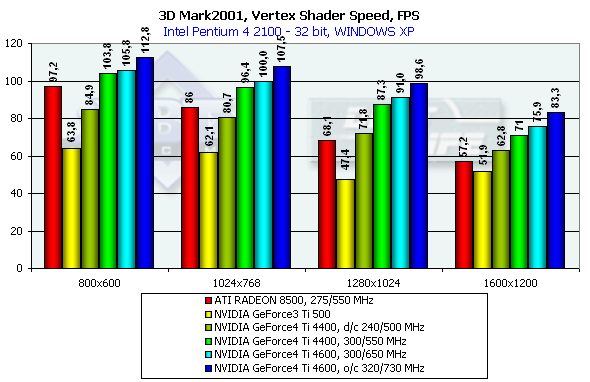
As the resolution increases the R200 becomes weaker as it is limited by the shading efficiency; the speed of the NV25 goes down much slower. Besides, the dual T&L of the NV25 is twice better in its architecture than the NV20 at the same frequency. Pixel shaderTaking into account that in too low resolutions a bottleneck is geometry, and in too high ones it is memory bandwidth let's take a look at 1024x768 and 1280x1024:
The NV25 thrives again despite the same frequency with the NV20. However, pixel shaders do not have a great architectural advantage as the possibility of hardware realization is much poorer as compared with vertex shaders. Sprites
The NV25 outscores the NV20 by a great margin at the same frequency. In the low resolution a geometry processing speed makes a decent effect, but in middle ones everything takes its places again. I can't say the NV25 is leading firmly, but it is well seen that the NV25 was much improved as compared with NV20. Besides, its capabilities of sprite scaling are also wider. Well, in the synthetic tests the NVIDIA GeForce4 Ti 4600 takes the palm, but you should remember that only real applications will let us make the final conclusions. 3D graphics, 3DMark2001 - gaming tests3DMark2001, 3DMARKS
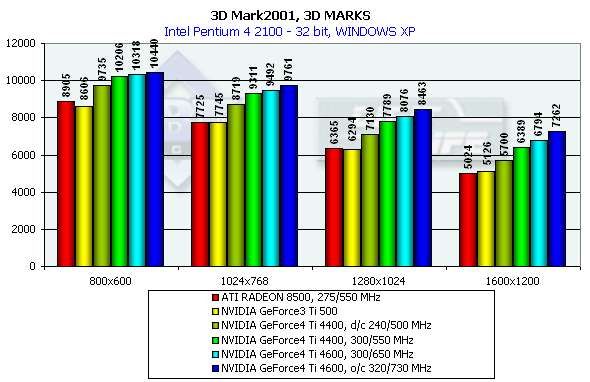
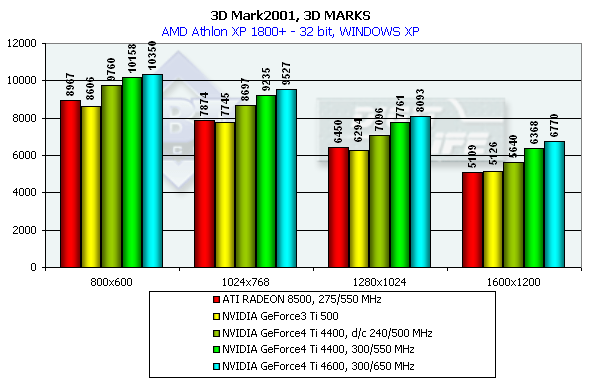
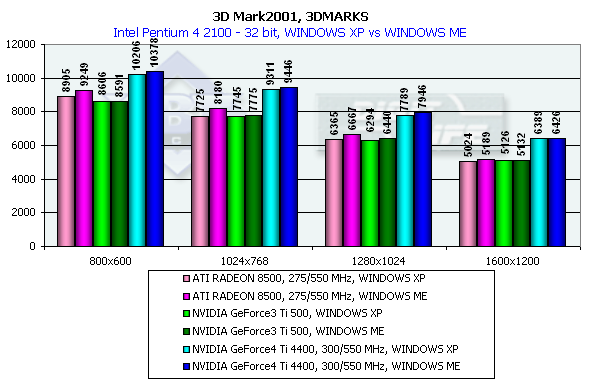
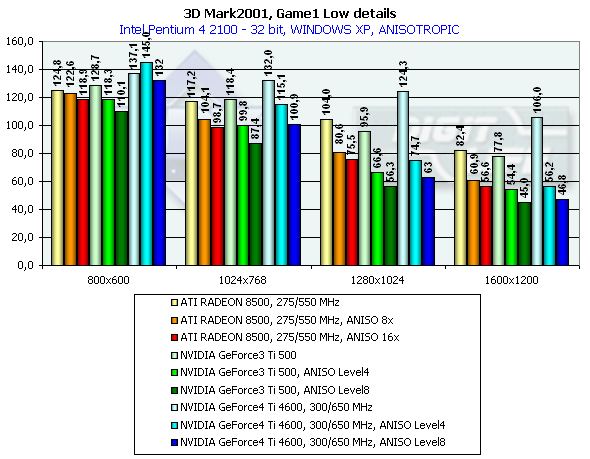
According to the general benchmarks the GeForce4 outscores its predecessor by 30%. The RADEON 8500 lost to the GeForce3 Ti 500 in the 3DMark2001 test. The 3DMark2001 includes 4 gaming tests, three of which are implemented at low and high detailing graphics levels. High detailing means that the processor and video accelerator are much more loaded with additional effects and polygonal complexity of the scenes. However, at a high detailing level in these tests the performance becomes limited by a CPU frequency in case of a highly efficient accelerator. The GeForce 4 proved it. And we had to exclude High Detail tests. 3DMark2001, Game1 Low details
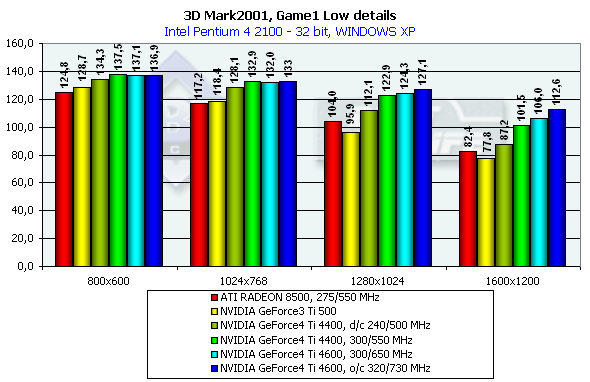
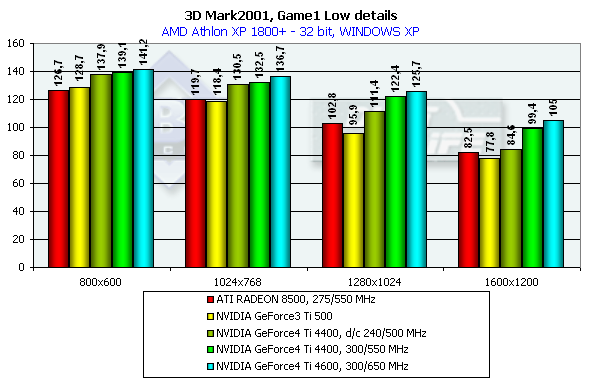
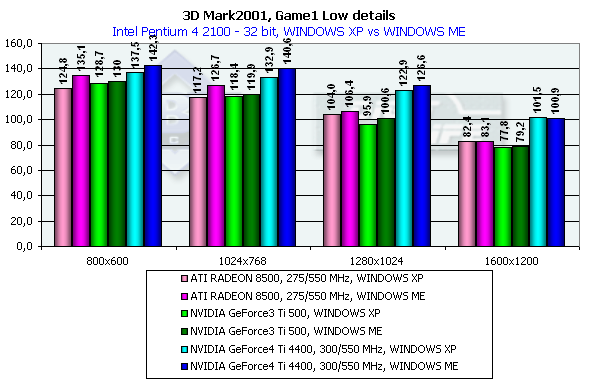
This is a war auto simulator. The developers state that this game scene spends processor time for calculation of physics and motion of objects as a real game. Characteristics:
In 1600x1200x32 the GeForce3 Ti 500 is beaten by the GeForce4 Ti 4400 by 30.5%, and by the GeForce4 Ti 4600 by 36.2%. If we compare OSs we will see that the results in the XP are worse than in the ME. 3DMark2001, Game2 Low details
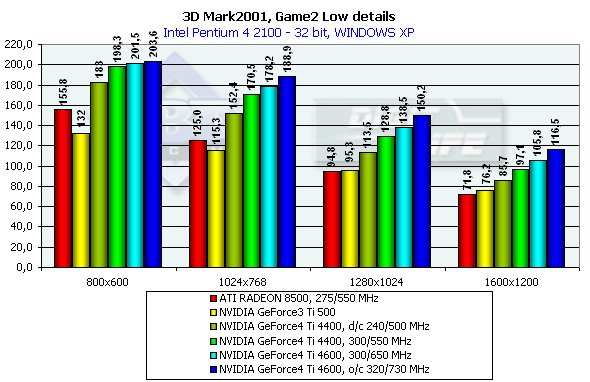
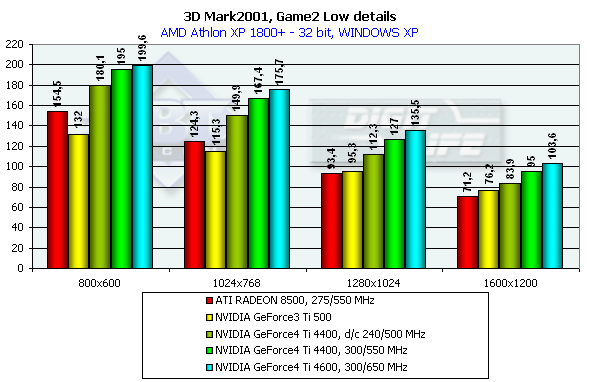
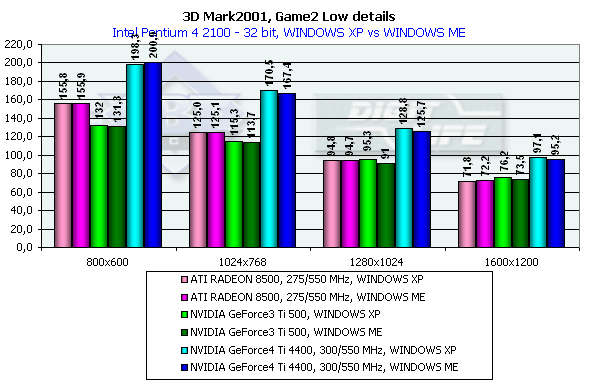
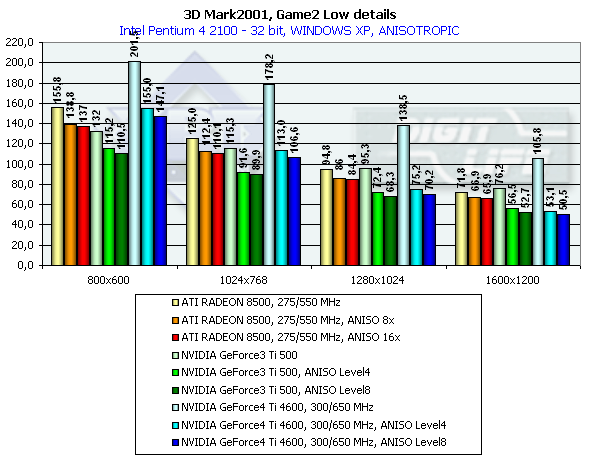
This is an arcade scene from a 3D Adventure or strategic game. The scenes have a high overdraw factor and a weak optimization of the geometry. The accelerator must provide optimization of operation with a Z-buffer. Characteristics:
In 1600x1200x32 the GeForce3 Ti 500 is beaten by the GeForce4 Ti 4400 by 27.4%, and by the GeForce4 Ti 4600 by 38.8%, and in 1280x1024x32 the figures are 35.1% and 45.3% respectively. It is interesting that again the peak falls on 1280x1024 and the drop falls on 1600x1200. The ATI RADEON 8500 performs equally in Widows XP and ME, and the NVIDIA shows better scores in the former one. 3DMark2001, Game3 Low details
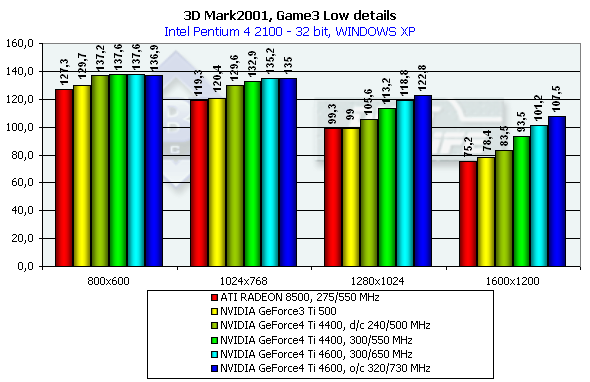
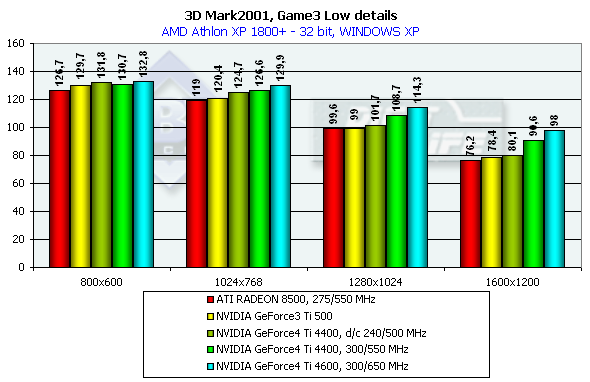
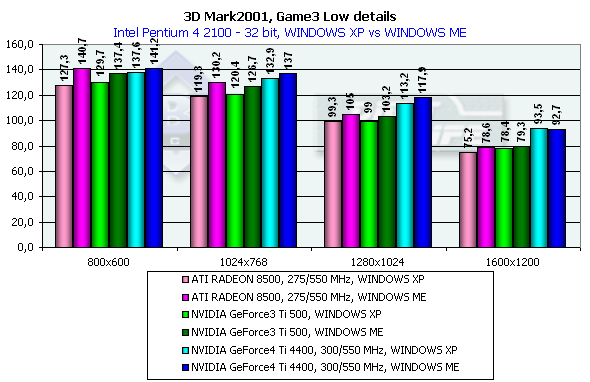
The scene is based on the "Matrix". A detail level is not high, it corresponds to the Quake2. There is skinning (matrix blending) and skeletal animation, detailed textures and a great deal of various bullet shells and pieces which load the GPU very much. Characteristics:
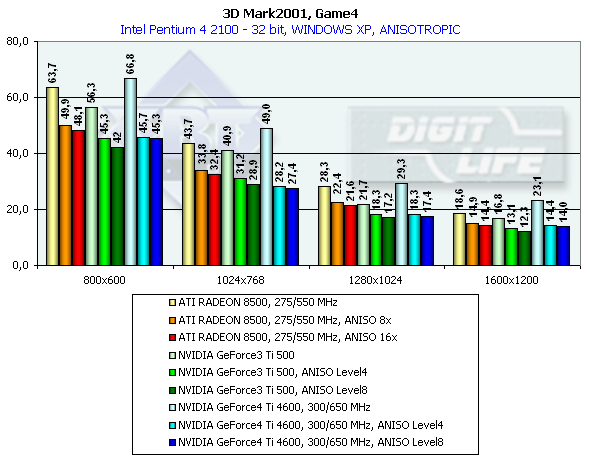
In 1600x1200x32 the GeForce3 Ti 500 falls behind the GeForce4 Ti 4400 by 19.3%, and behind the GeForce4 Ti 4600 by 29.1%. Comparison of the OSs showed that the performance of all cards is higher in the ME. 3DMark2001, Game4
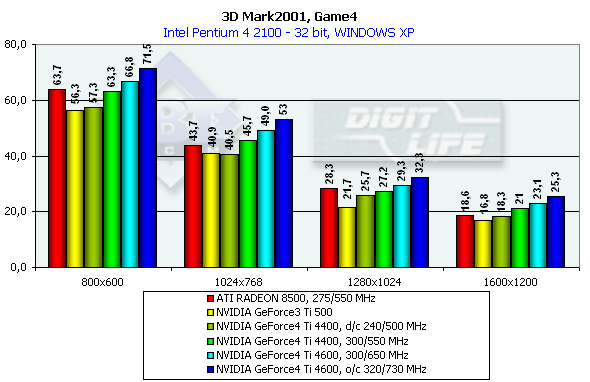
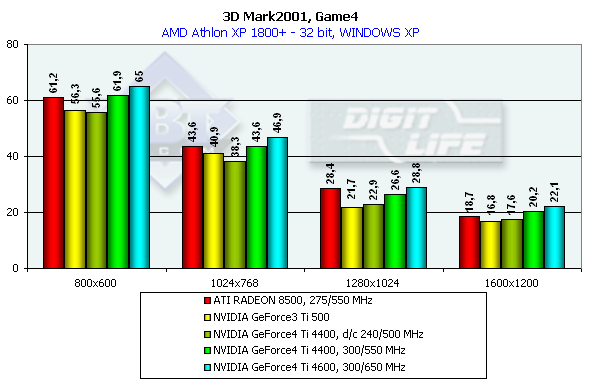
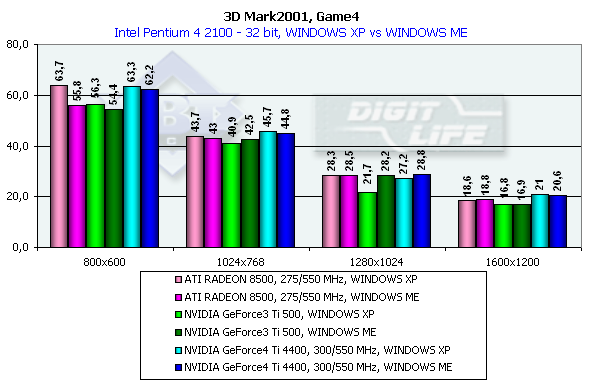
This test uses pixel shaders, vertex shaders and cube texturing to form water surfaces. That is why it is better to play this game only on the GeForce3/4 or RADEON 8500 (in the demo mode water surface is not displayed). Characteristics:
In 1600x1200x32 the GeForce3 Ti 500 falls behind the GeForce4 Ti 4400 by 25%, and behind the GeForce4 Ti 4600 by 37.5%. Comparison of the OSs showed that the NVIDIA card performs better in the ME and the ATI RADEON 8500 has equal results both under ME and XP. 3D graphics, gaming testsTo estimate performance in 3D games we used the following tests:
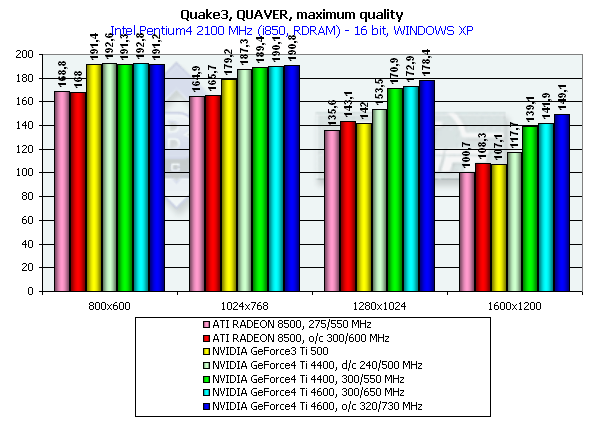
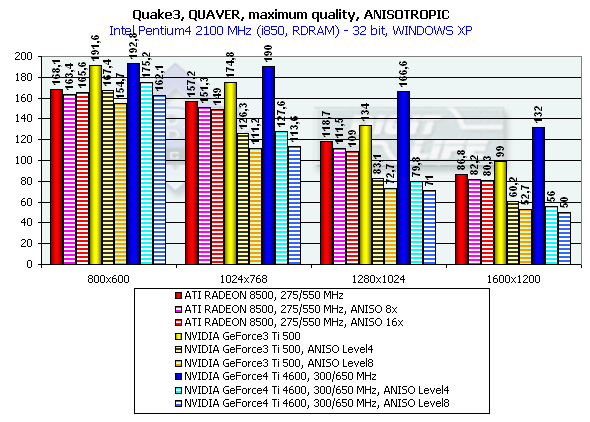
Quake3 ArenaQuaver, highest quality modesThe tests with Quaver were carried out in 16-bit and 32-bit color modes at the highest detailing and complexity levels of geometry (r_subdivisions "1" r_lodCurveError "30000"). This benchmark loads accelerators with complicated geometry as well as with huge textures and a great deal of effects. Pentium 4 2100
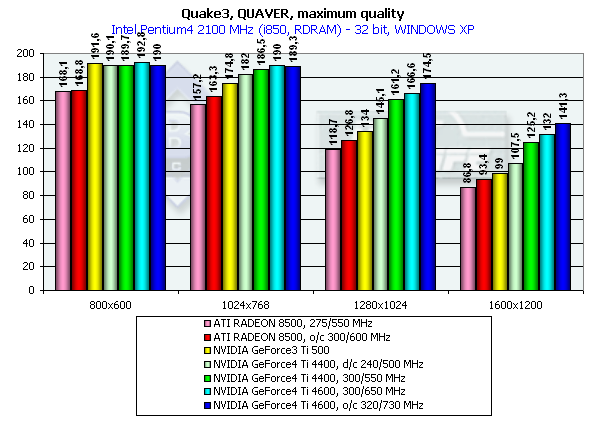
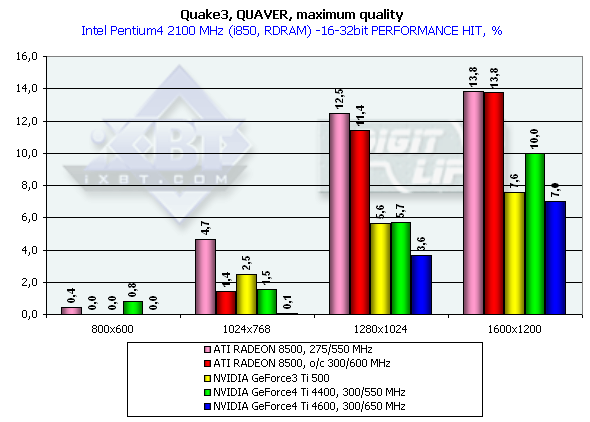
Athlon XP 1800+
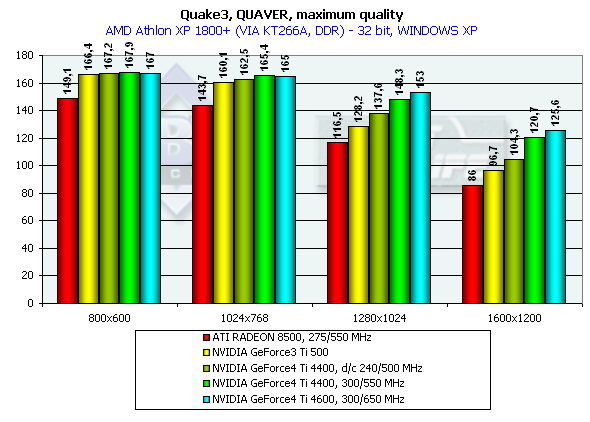
The GeForce 4 which was purposely slowed down to the frequency of Ti 500 (d/c 240/500 MHz) shows much better performance than the Ti 500 which means good optimization of different units of the GeForce4 in comparison to the GF3. We also overclocked the ATI RADEON 8500 to the assumed level of the next revision - 300/300 (600) MHz, and we can see that such gain won't help the chip.
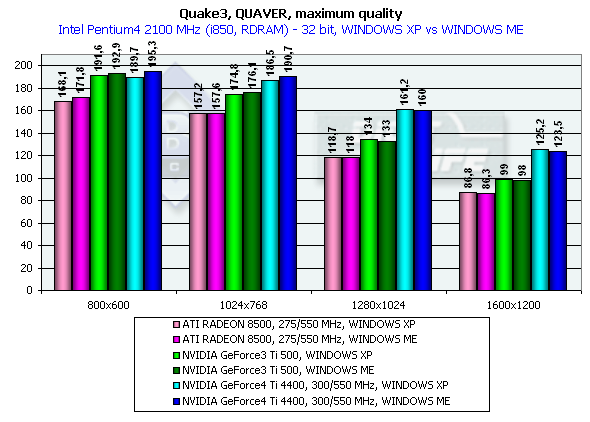
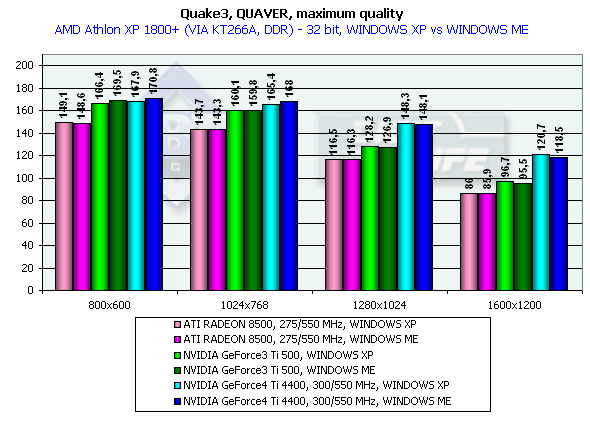
Both developers worked well on the OpenGL ICD making the performances equal in the Windows XP and Windows ME, and the NVIDIA's drivers do have better results in the Windows XP. In 1280x1024x32 the GeForce3 Ti 500 lags behind the GeForce4 Ti 4400 by 20.3% and behind the GeForce4 Ti 4600 by 24.3%. In 1600x1200x32 the figures are 26.5% and 33.3% respectively. The chip's frequency grew up from 240 to 300 MHz and now amounts to 25%. Serious SamKarnak demo, Quality modeHere are screenshots of the settings:






Pentium 4 2100
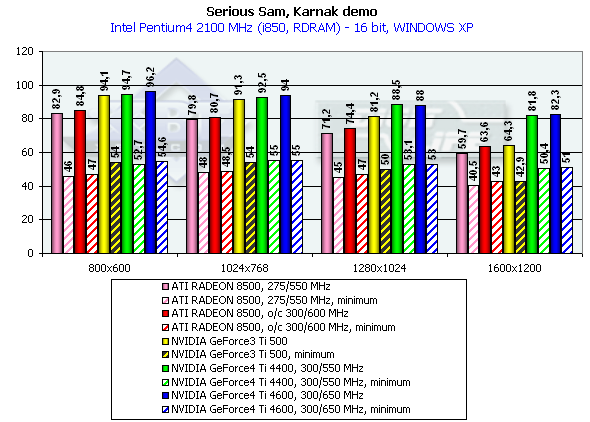
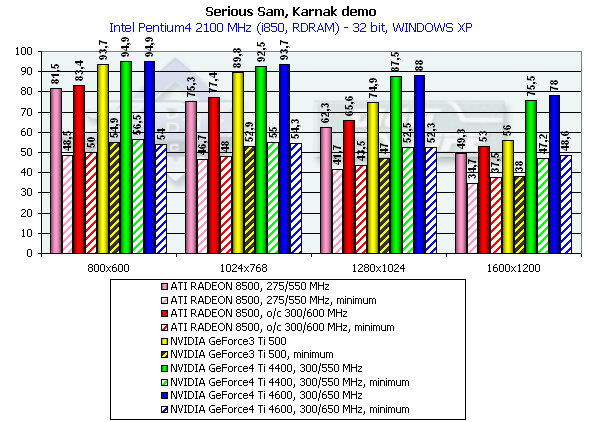
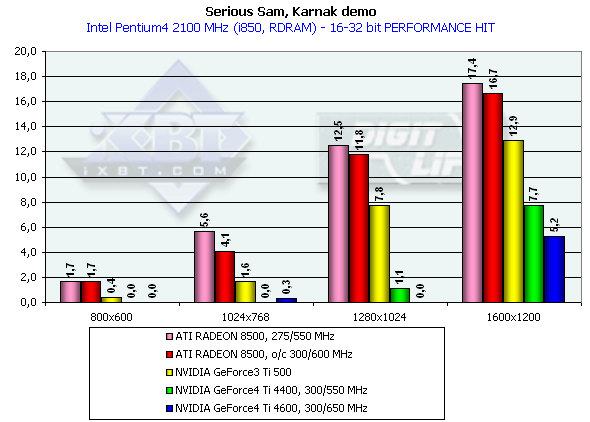
Athlon XP 1800+
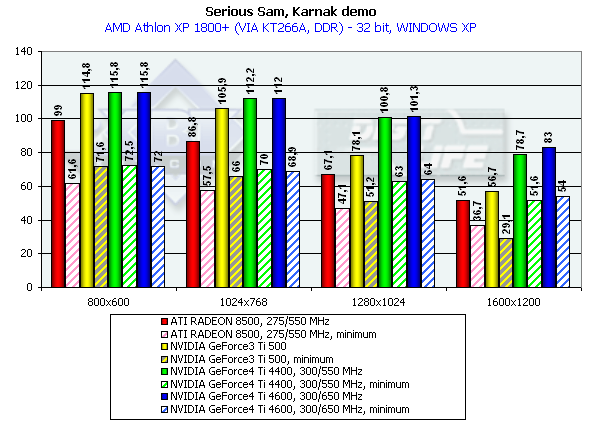
The diagrams show both average and lowest performance results. The performance drop, when moving from 16 to 32-bit mode, showed that the time of 16-bit color has passed. All accelerators provide good playability even in 1600x1200x32.
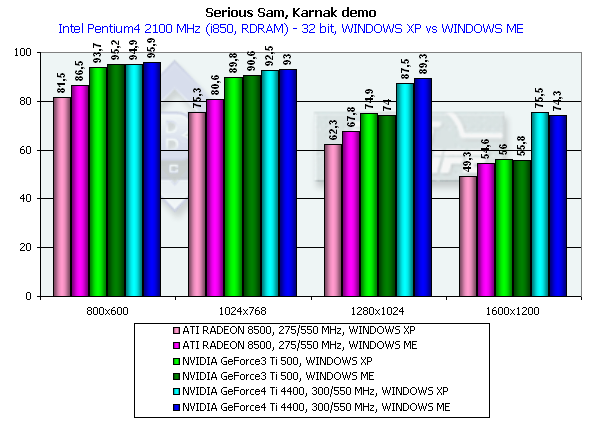
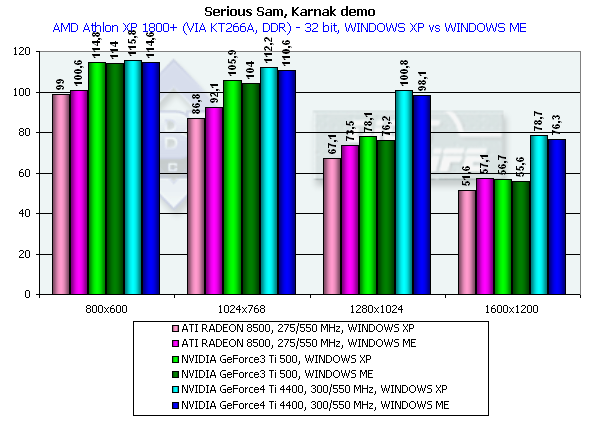
In 1600x1200x32 the GeForce3 Ti 500 falls behind the GeForce4 Ti 4400 by 34.8%, and behind the GeForce4 Ti 4600 by 39.3%. Return to Castle Wolfenstein (Multiplayer)Checkpoint, highest quality modesThe tests were carried out in 32-bit color at the highest detail and quality levels of textures. Pentium 4 2100
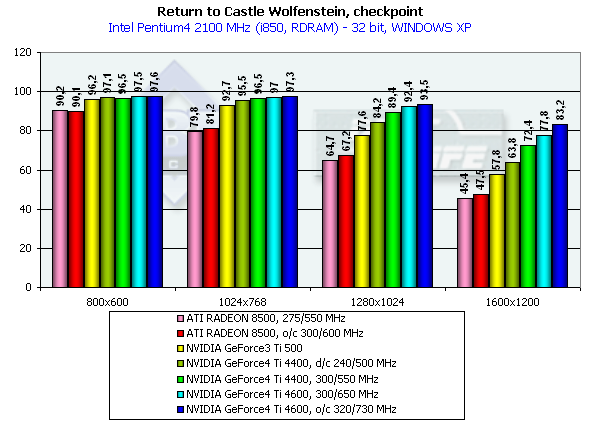
Athlon XP 1800+
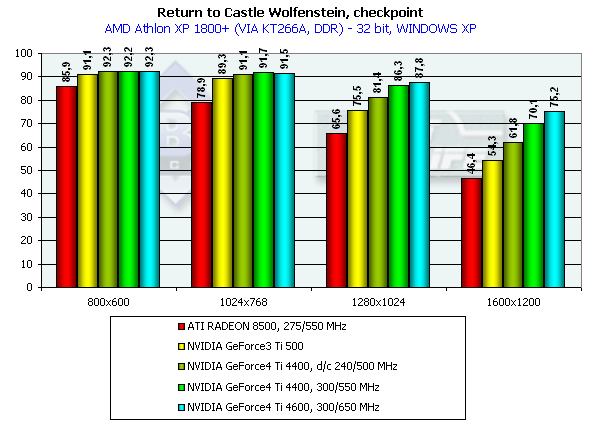
Although this game is more GPU and CPU dependent the competitors take the same places.
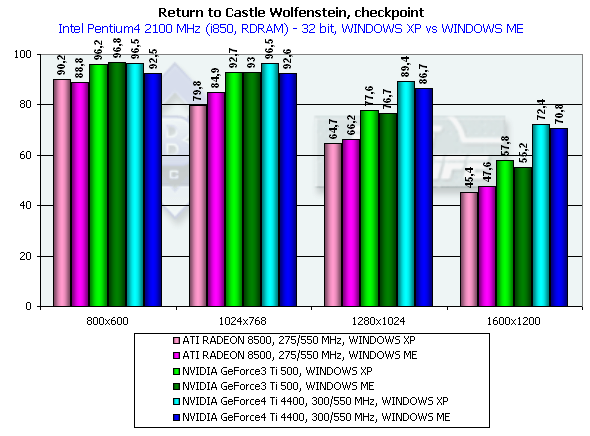
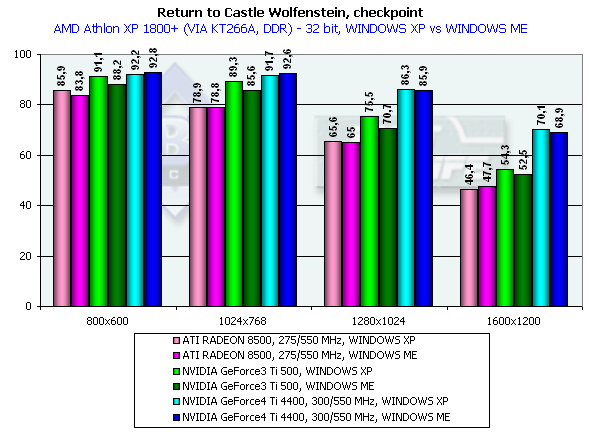
Again we can see that the OpenGL ICD works excellently under the Windows XP. The NVIDIA based cards have better results in the Windows XP than in the Windows ME. In 1600x1200x32 the GeForce4 Ti 4400 beats the Ti 500 by 25.6%, and the GeForce4 Ti 4600 outscores it by 34.6%, which are very good results for the GPU whose frequency is higher by 25%. As you can see, the memory bandwidth is of vital importance here. GiantsGamegauge, highest quality modesWe think that this game excellently shows power and capabilities of modern video cards when geometry is very complicated as compared with other benchmarks for DX (the game shows relief texturing technique based on the Dot3 and environment mapping which requires a high fillrate from the accelerators). The disadvantage of this test is dependence on a CPU frequency and on a platform. Pentium 4 2100
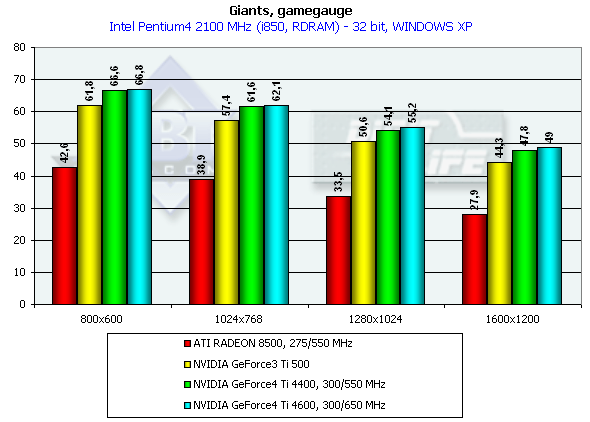
Athlon XP 1800+
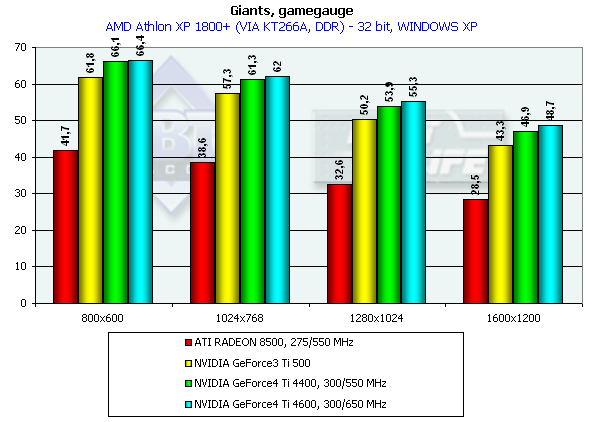
The performance gain is not so striking this time.
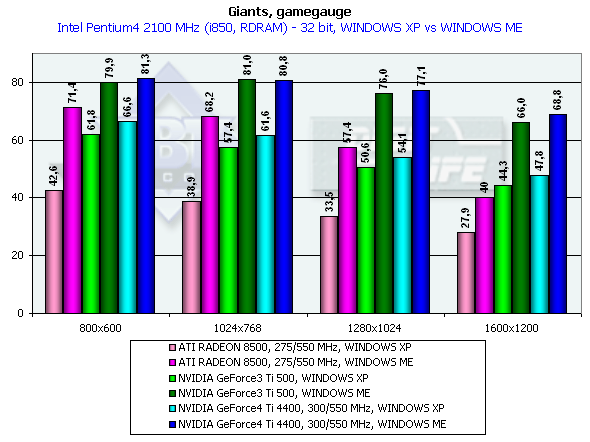
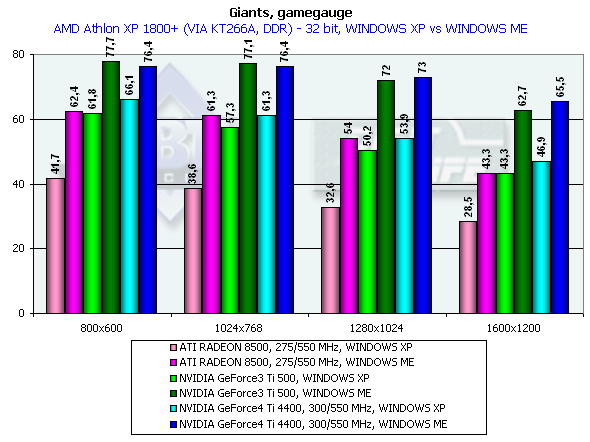
Look how better the performance is under the Windows ME than under the Windows XP. It is obviously not the drivers but the game which was adjusted for this OS. The Ti 500 loses to the GeForce4 Ti 4400 by 7.9%, and to the GeForce4 Ti 4600 by 10.6% (in 1600x1200x32). Keep in mind that it is the Windows XP which demonstrates a lower performance. Besides, the engine of the game hardly reacts on power growth of a video card. Probably, it is CPU dependence which is guilty. GLMarkHighest quality modesGLMark uses extensions of OpenGL from NVIDIA typical of the GeForce3, that is why it is interesting to compare GeForce3 and GeForce4 in this test, though the results of the ATI RADEON 8500 are also shown (but remember that this card is not able to use some bump mapping functions peculiar to the GeForce3 and some NVIDIA extentions for acceleration of GeForce3/4 cards. The cards were tested only in 32-bit color. Pentium 4 2100
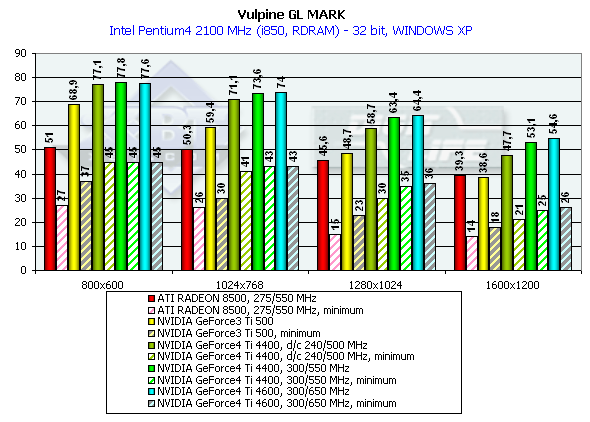
Athlon XP 1800+
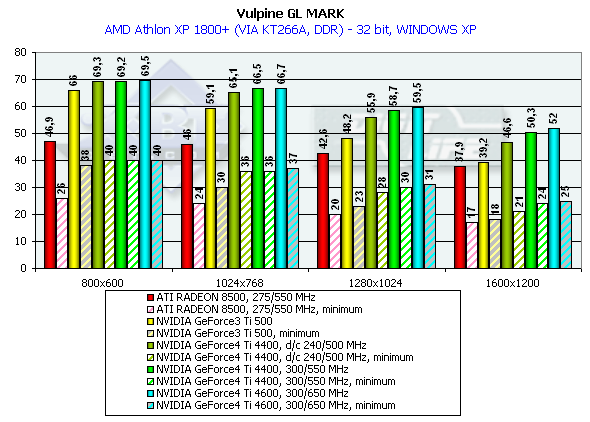
This is a very complicated test (considering the number of polygons and effects of relief texturing). Only in 1280x1024x32 the GeForce4 allows playing comfortably. The Ti 500 yields to the GeForce4 Ti 4400 by 37.5%, and to the GeForce4 Ti 4600 by 41.5%. The test of the GeForce4 at the Ti 500's frequency of 240/500 MHz showed once again that the architecture of the new GPU is much improved. AquaMarkDefault Quality ModesThe test uses a set of textures of 24 MBytes, pixel shaders are enabled, and the cards were tested only in 32-bit color. Pentium 4 2100
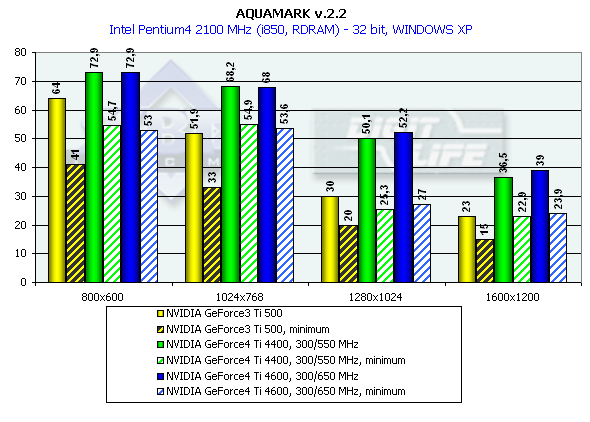
Athlon XP 1800+
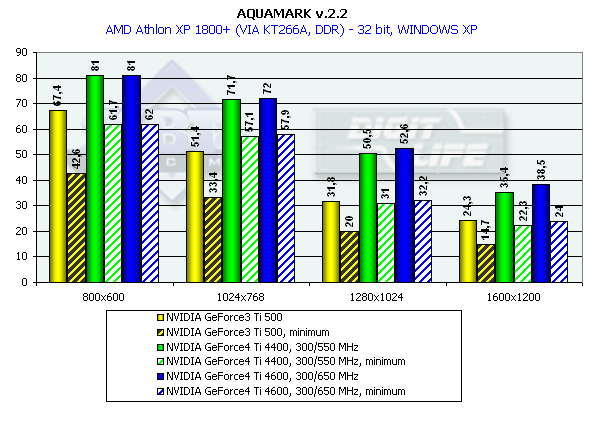
Almost a year ago the the AquaMark benchmark was created on the base of the AquaNox game. Scene complexity in the AquaMark was almost 130,000 polygons. However, the GeForce4 easily copes with it. In 1600x1200x32 the Ti 500 loses to the GeForce4 Ti 4400 by 58.7%, to the GeForce4 Ti 4600 by 69.5% ! It is interesting that this test makes strong demands to a GPU instead of the memory bandwidth. The difference between the 4400 and 4600 models is minimal. ANISOTROPIC FILTERINGThe MIP-mapping technology improves image quality for scenes with objects that extend from the foreground deep into the background. It creates for each texture a set of MIP-levels (its copies of different detail levels) which are chosen based on the size and the resulting scale. The further the triangle is, the more blurry the MIP-level will be used. Trilinear filtering smoothes over sharp edges of MIP-levels. Thus, while bilinear filtering removes sharp edges between texture pixels, the trilinear one softens an image even more so that only close objects can be seen sharper. At the same time, walls which are at a too sharp angle for us are too blurry. And anisotropic filtering is used to cope with such inconvenient objects for bilinear and trilinear filterings. Different processor makers realize this function differently. Besides, speed characteristics of anisotropic filterings of ATI and NVIDIA differ much as well. Only the resulting quality is similar. But is that true? As you know, the NVIDIA's anisotropy (in case of GeForce3) has high quality, but it eats much as well. The performance drop can reach 50%! ATI's anisotropy (in case of RADEON 8500) is much cheaper and provides apparently the same quality. Quality of anisotropy can be estimated by examples of walls, floors etc. And our attentive readers know that the RADEON 8500 doesn't use any anisotropy on some surfaces located at angles different from 90 degrees. Look at the screenshots of the Serious Sam game: ATI RADEON 8500
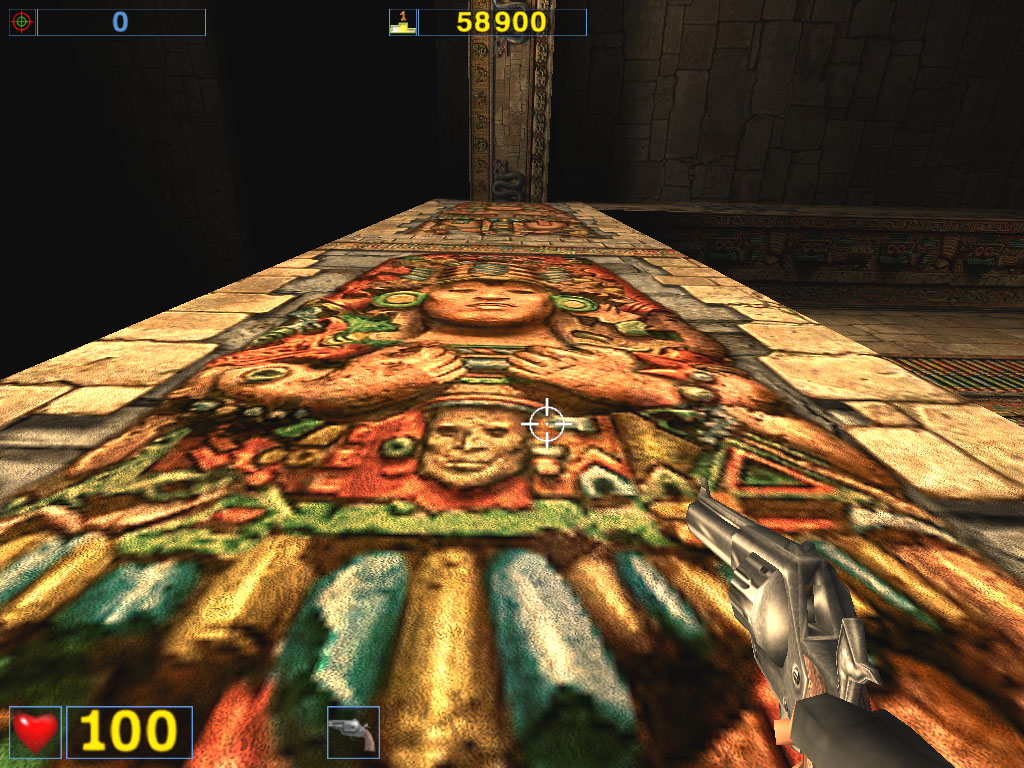
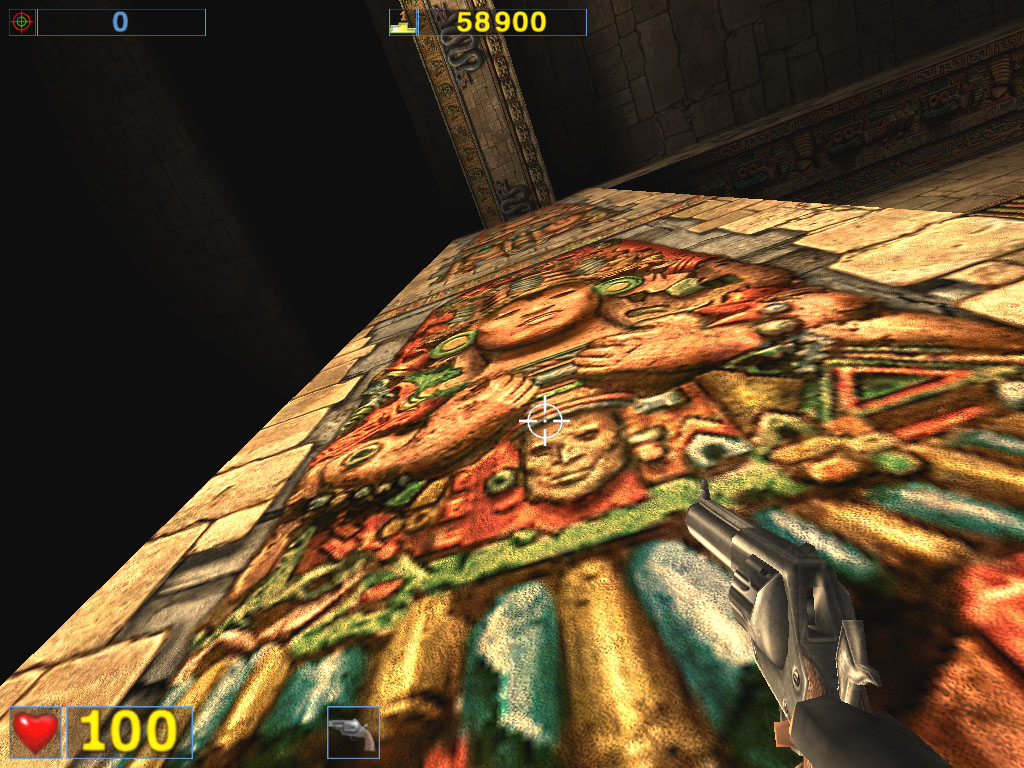
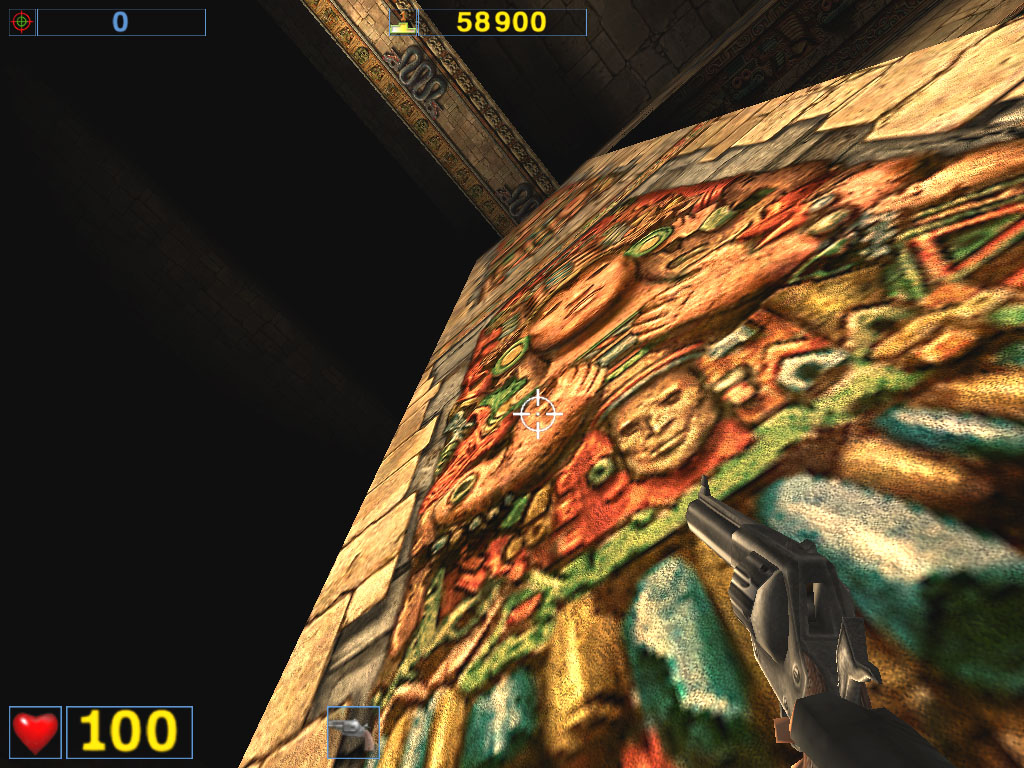
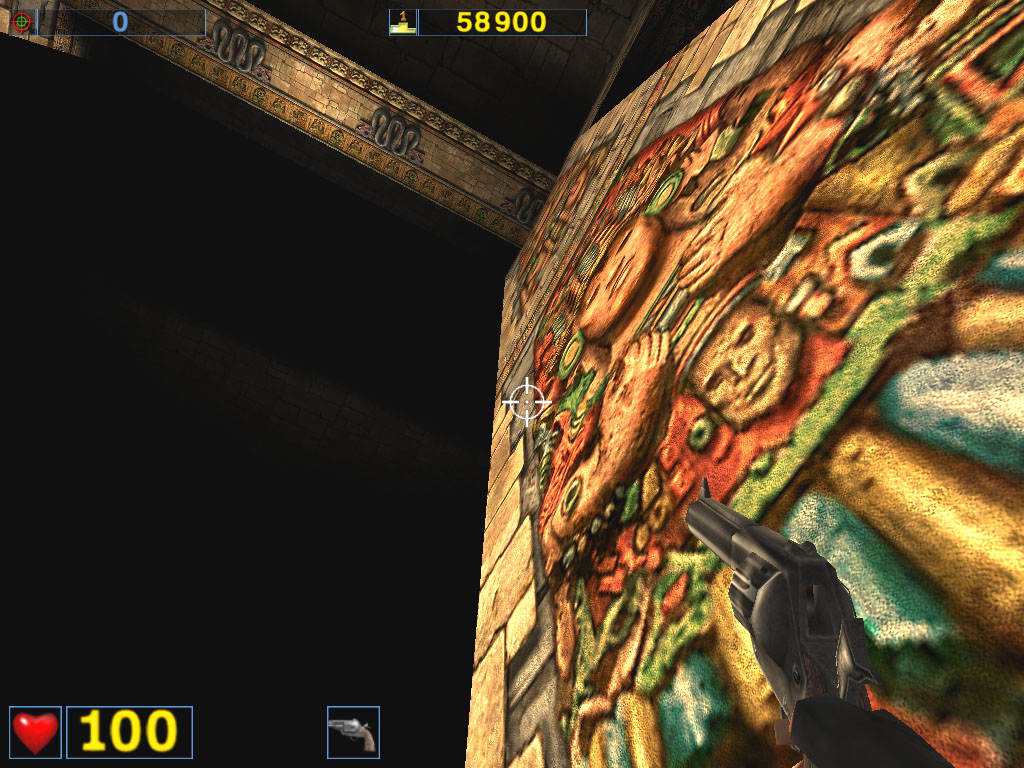
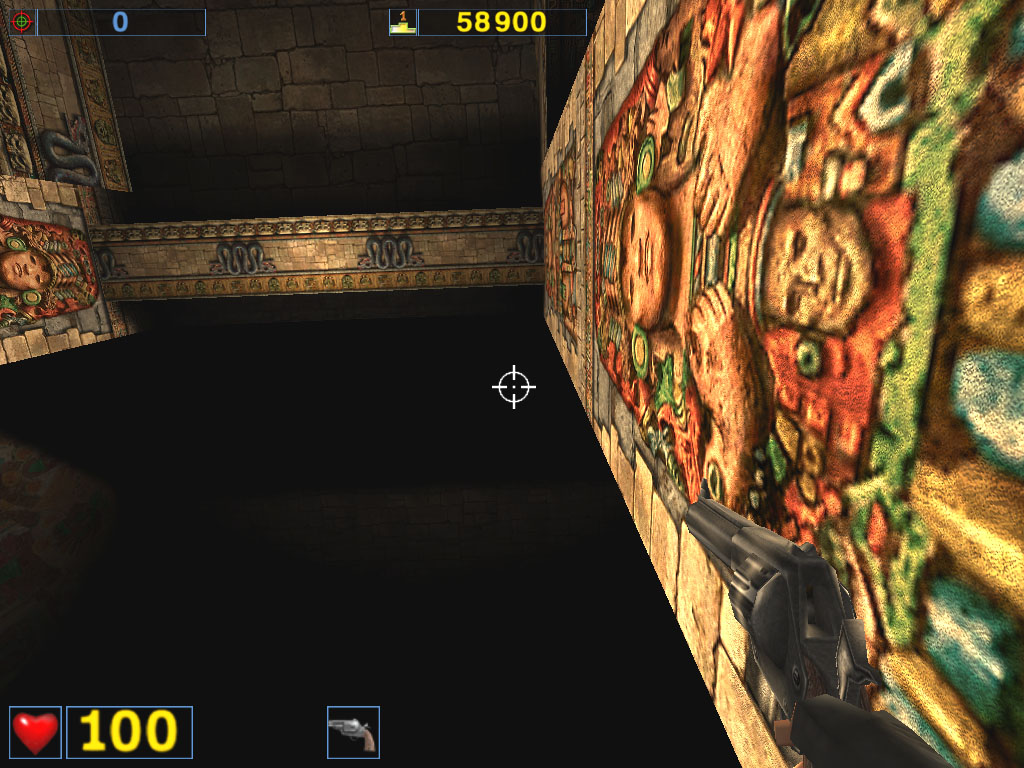
NVIDIA GeForce4



Here are animated GIF files:
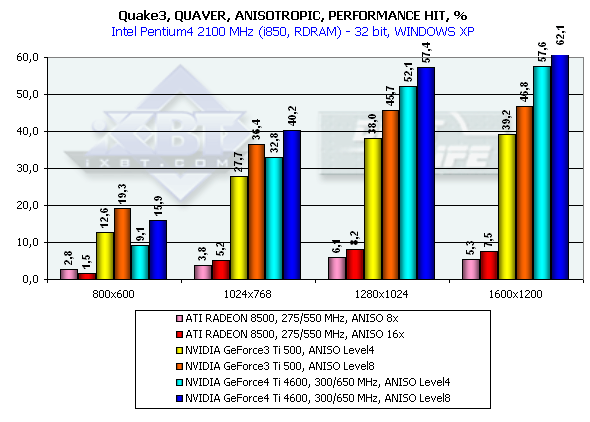
At some angles the RADEON 8500 provides no sharpness. The NVIDIA GeForce3 and GeForce4 do not have such problems. It isn't good if a user can't choose between the full anisotropy with great losses and its cheaper approximation. The GeForce4 has, in fact, the same anisotropy method as of the GeForce3, i.e. 3 levels, each having the maximum texture sampling value for realization of anisotropic filtering (Level2 - 8, Level4 - 16, Level8 - 32 samples). NVIDIA's and ATI's approaches to anisotropic filtering realizationWhile bilinear and trilinear filterings are mathematically strictly defined (though some time ago NVIDIA called a trilinear filtering some approximation method - dithering of values from different MIP levels), the concept of anisotropic filtering doesn't imply definite algorithms of its realization. Approaches of NVIDIA and ATI to this issue are different. Let me show you some figures: 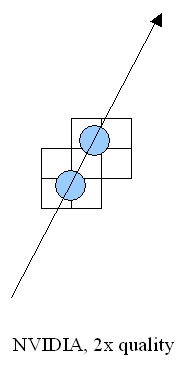  NVIDIA: the figure shows fetching of bilinear samples in the texture space during implementation of the anisotropic filtering. Depending on filtering quality settings and inclination of surface a standard bilinear (or trilinear) filtering is implemented from one to four times for points lying on a straight line which divides a pixel projected from the screen onto a texture surface along its long side (the line is shown with an arrow on the figure). The values obtained this way (blue circles) are averaged, and make the result of the filtering. Each value is based on four closest discrete values of the texture (rectangles) and can have its own independent coordinates. Such approach suits for arbitrarily oriented textures but it requires a great level of performance - for the visible part of triangles non-parallel to the screen the number of fetched texture samples grows up several times, so does the shading time. The ATI's approach is more limited but more efficient as well:   The values are fetched in a line which can lie either horizontally or vertically in the texture's plane. For values of the projection vector which are close to the orts (the arrow on the figure) the filtering quality will be high, but as it turns the effect will be decreasing until this method starts making no sense at all. In real applications the filtering will work good on walls or ceilings, but the results will be vanishing on surfaces located at angles different from the right one the result will be less noticeable till the critical angle of 45 degrees is reached. However, such approach is beneficial from the computational point of view. First of all, we can choose organized lines from 2õN texture points in size (squares on the figure) which can be effectively fetched during N/2 cycles with the help of standard texture units meant for bilinear filtering. Then we filter values (circles on the figure) using every time the same offset values relative to the discrete points of the original texture. Such operation can be fulfilled at one clock by a special circuit of ten multipliers which is integrated into a texture unit; interpolation parameters are, thankfully, calculated just one time and remain unchangeable for all 1..5 calculated points. Besides, we can speed up this algorithm which is anyway efficient by calculating texture variants specially compressed on axes in advance (so called RIP mapping). The NVIDIA's approach needs more time to get the result but it processes objects at any angles equally good, not only those positioned just horizontally or vertically. The ATI's method has a rational core as the most of modern games use mostly horizontal and vertical surfaces. Quake3
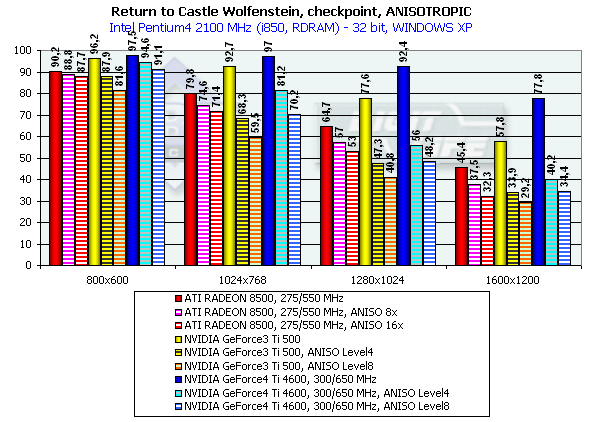
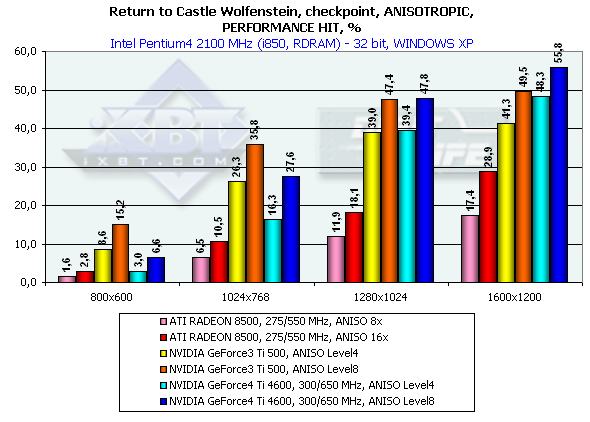
Return to Castle Wolfenstein
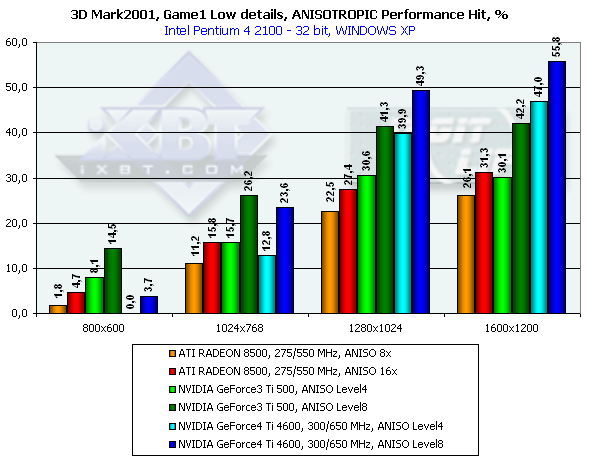
3DMark2001, Game1 Low details
3DMark2001, Game2 Low details
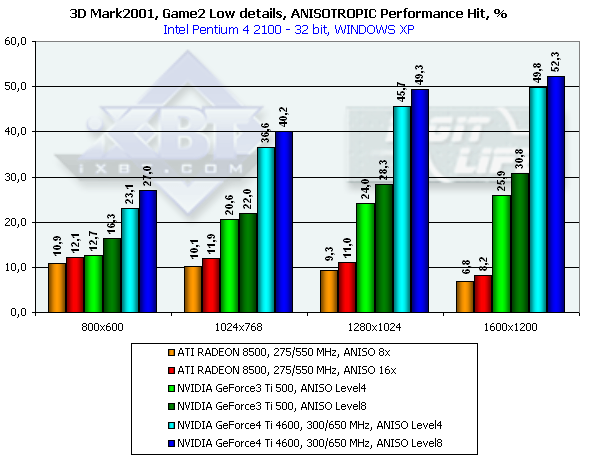
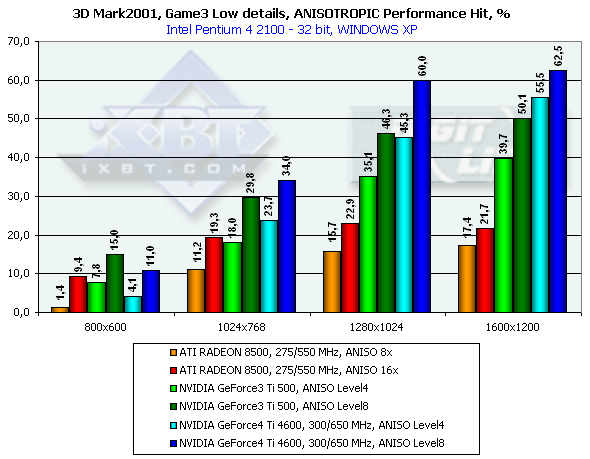
3DMark2001, Game3 Low details
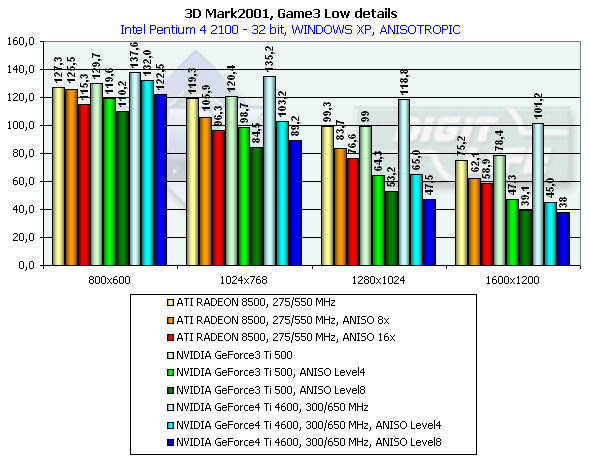
3DMark2001, Game4
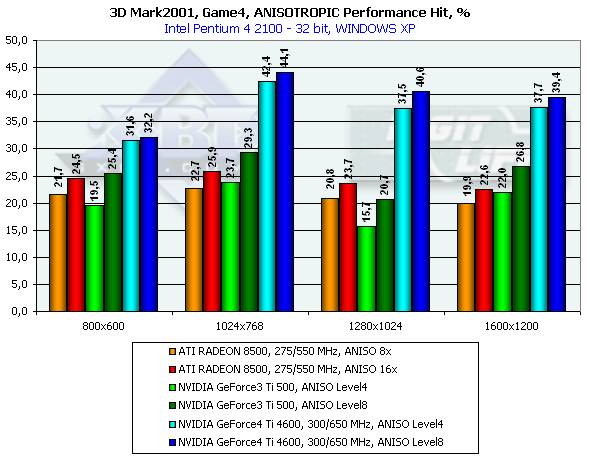
As you can see, the performance of the GeForce4 falls down by a greater margin as compared with the GeForce3. The Level8 kills all advantages of the GeForce4 as far as speed is concerned. But is it possible at least at Level4 to get the same quality as that of the RADEON 8500? Yes! There will be losses relative to the Level8, but high quality can be provided by making the LOD BIAS value lower. Till recently this parameter could be changed only in the Direct3D with the help of tweakers, for example, RivaTuner. The 27.* drivers allows making it in the OpenGL as well but only in the Registry. Let's see what we can get by setting LOD BIAS to -1 for the Serious Sam: The Second Encounter. Anisotropic filtering Level 8


Anisotropic filtering Level 4, LOD BIAS = 0


Anisotropic filtering Level 4, LOD BIAS = -1


Anisotropic filtering Level 2, LOD BIAS = -1


Well, the effect is achieved. However, there are also some side effects - moire and texture noise, but the RADEON 8500 has the same when the anisotropy is enabled (at its maximum level). Here the performance drop is not so great. At the Level2 decreasing the LOD BIAS doesn't help any more, though quality of the Level4 at LOD BIAS = 0 can be achieved. ANTI-ALIASING (AA)This function is used to remove a stair-step effect. When the AA is enabled the performance drop is even more considerable. The Quincunx level is fast but it often makes textures soapy. In the GeForce4 we can use the next AA level (4x) which has excellent quality. Let's look at quality of two the most interesting AA types of the GeForce3 Ti 500 and GeForce4 and compare them.
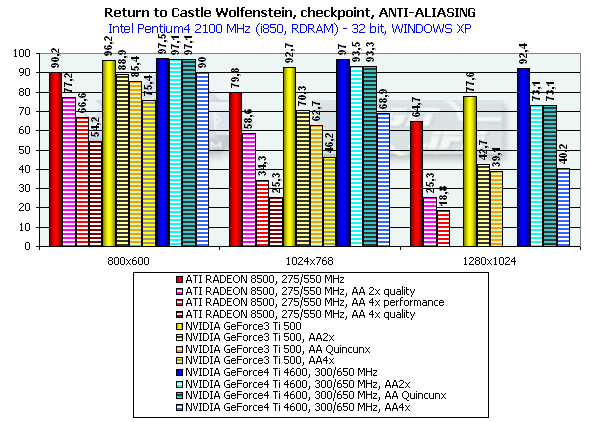
There is no much difference between the GF3 and GF4 at AA 4x and AA Quincunx levels. The AA 4xS doesn't improve visual quality as well. New hybrid ÀÀ mode: 4xS.The new hybrid (MS and SS simultaneously) mode of full-screen anti-aliasing is available on NV25 based cards. Two subunits (2x1) positioned one over the other and obtained the way typical of the 2õ MSAA are averaged in every original 2õ2 AA unit (a usual 4õ MSAA unit is shown on the right for comparison): 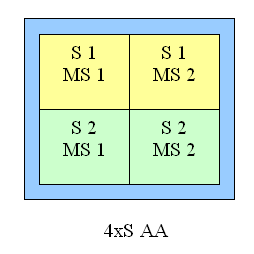 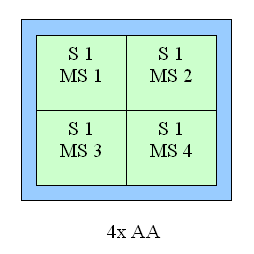 S1 is the first 2õ1 subunit, and S2 is the second one. Samples are calculated according to the multisampling method inside the subunit, i.e. from one selected texture value, but texture values can differ in upper and lower subunits, unlike in a usual 4x MSAA. From the accelerator's standpoint we just calculate a vertically doubled image in a standard 2x MSAA mode (2õ1 units). This mode can also be set up in the NV20 but only through undocumented driver parameters in the register. The NV25 based cards allow making this setting in the driver's control panel. It should be noted that the NV25 performs excellently: although the number of interpolated texture values is now twice larger, the performance differs from the 4õ by just a couple of percents, and visual quality is much better. This method can't improve the situation considerably on polygons' edges - SSAA and MSAA look similar there, but textures must be now less blurry. Moreover, for horizontal surfaces (landscapes, floor, ceiling) this method implements some anisotropic filtering functions (2õ quality). Later we will examine closely realization of the 4õS on real images and performance results. And now let's estimate a performance drop. Quake3
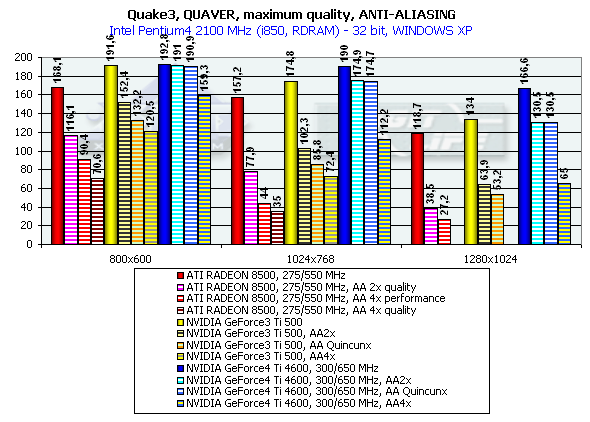
Return to Castle Wolfenstein
3DMark2001, Game1 Low details
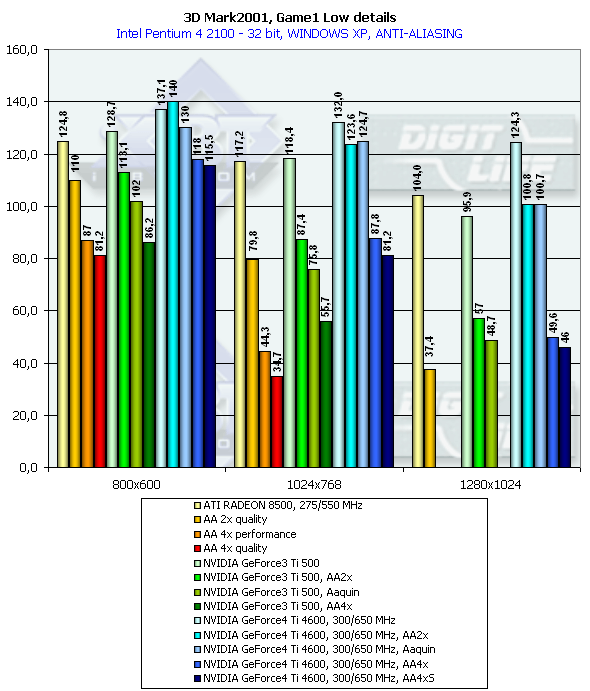
3DMark2001, Game2 Low details
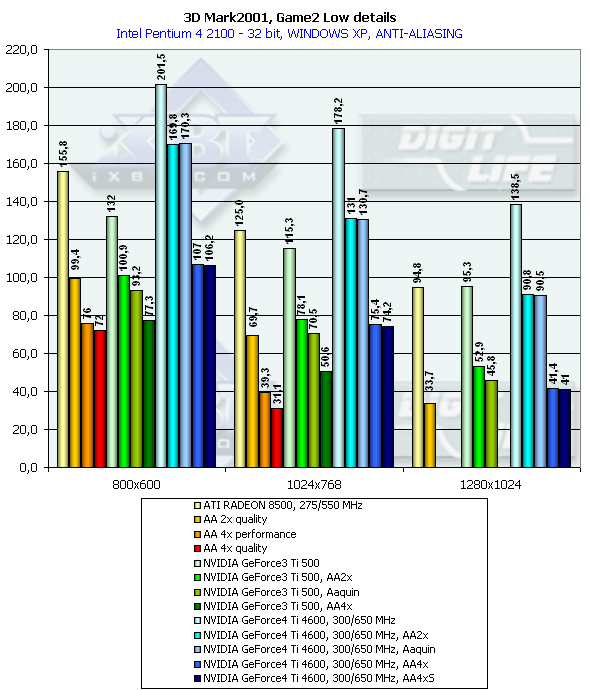
3DMark2001, Game3 Low details
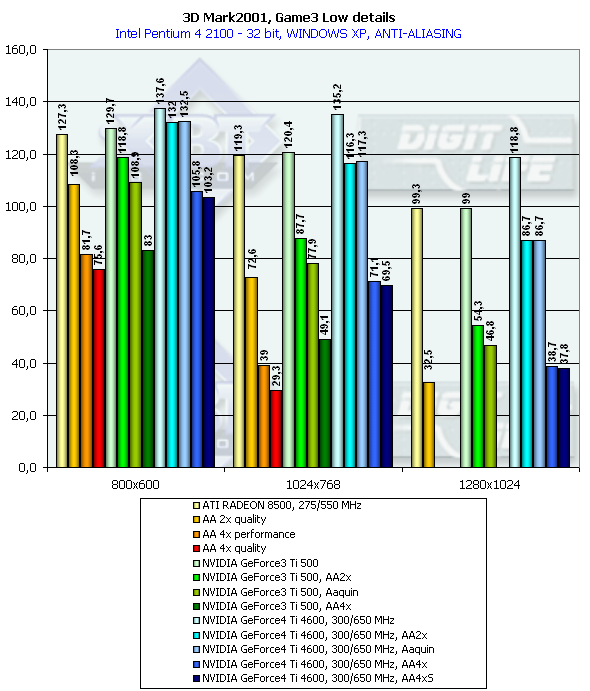
It is interesting that in AA 2x and AA Quincunx the performance is almost the same (thanks to a great memory bandwidth and optimization of the GeForce4 Ti 4600 in the multisampling mode). Other modes also became more attractive thanks to a greater performance of the GeForce4. The 4xS mode (works only in Direct3D) turned out to be quite strange. Its speed and quality are approximately at the 4x level. Probably, this mode will be improved. Joint operation of the anisotropic filtering and AA will be examined in our next reviews of production video cards on the GeForce4 Ti. Conclusion
The Ti 4400 will probably be positioned as a direct competitor against RADEON 8500, including the price. The Ti 4600 will take a higher position, and lack of competitors will let its price go up without limit. The new chip of NVIDIA (NV25) is able to sit firmly in the upper-level gaming market, and probably will be the main carrier of DX8 advanced technologies. [ Part I ]
Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
































































