Cache subsystem
The doubling theme was probably very popular in Nehalem: engineers doubled not only the branch unit, but also TLB (Translation-Lookaside Buffer). They did it in the same way: the unit inherited from Core 2 was preserved without any changes (only a tad enlarged), the new second level was added above the old TLB -- it's even larger (512 entries) and offers more functions (L2 TLB can translate page addresses of any size). Support for arbitrary-size pages is hardly necessary for a desktop processor, this feature will come in handy with heavy server applications. And the large TLB is apparently another step to SMT.
However, most changes were introduced to the main cache subsystem, namely, L1-L2 interaction and L3 cache, added to Nehalem. For one, L2 again belongs to a given core, it's not shared. In its turn, L3 is shared between all cores. For two, Intel slightly modified latencies of L1 and L2 -- L1 latency is now higher by one cycle than in Core 2, and L2 latency is 1.5 times as low.
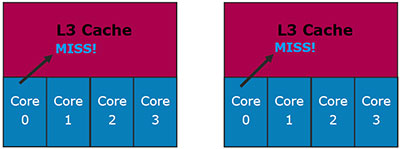
But we are mostly interested in L3 here. Just like L2 in Core 2, it's a dynamic shared cache. Moreover, it's finally inclusive instead of non-exclusive: data in L1/L2 must be present in L3. Intel even explains the reason for this solution (the left image corresponds to exclusive cache, the right image -- inclusive).
Let's analyze the first situation: Core 0 requests data from L3 Cache and fails to find them there.
In case of exclusive cache (left) it means nothing: these data may be stored in L1/L2 caches of other cores. Inclusive cache cuts this situation out, so there is no need in additional checks.
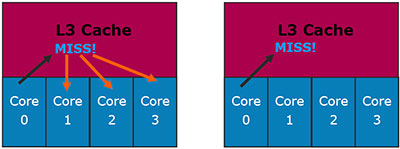
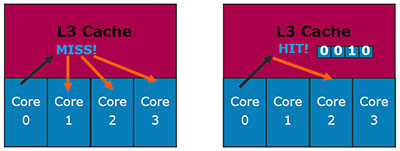
Let's analyze a different situation: Core 0 requests data from L3 cache, which are really stored there. The exclusive cache experiences no problems here: if the data are found in L3, they are not stored anywhere else. Inclusive cache might have a problem here: data must be in L1/L2 of one of the cores. Which one?..
It's not a problem for Nehalem: each line in L3 Cache contains core valid bits (by the number of physical cores), they indicate in which core the original L1/L2 data are stored. So there is no need to poll each core.
Intel has a consistent idea of an optimal cache architecture: performance is more important than size. It may have to do with the fact that the company designs large caches well. :) We are a bit disappointed that L3 in Core i7 won't operate at the processor clock rate, but at some fixed frequency for an entire series. However, two facts make up for this fly in the ointment: firstly, L3 in AMD Phenom also operates at the fixed frequency; and secondly, this frequency is higher in Core i7 (2.66 GHz).
QPI as a QPB replacement
We apologize for this strange title, but we really like it: abbreviation of the new processor bus from Intel (QuickPath Interconnect) differs from the old one (Quad Pumped Bus) only by a letter. So what is QPI? Technically, it's a bidirectional 20-bit bus with point-to-point topology, where 16 bits in each direction carry data, and another 4 bits are used for error correction and the protocol. Processing 6.4 billion transactions per second, QPI provides the data exchange rate of 12.8 GB/s in each direction, 25.6 GB/s in total. So it's the fastest processor bus (1600-MHz QPB provides the total bandwidth of 12.8 GB/s, AMD HyperTransport 3.0 -- 24 GB/s). However, the fastest modification of QPI is planned only for Core i7 Extreme Edition so far. Regular Core i7 processors will be equipped with a tad slower modification with the bandwidth of 4.8 billion transactions per cycle.

It stands to reason that such bandwidth is excessive in most cases for a desktop processor, especially considering the fact that QPI will be used solely to connect to the chipset, as the memory controller is already built into the processor. (This solution is useful only when the chipset provides a lot of PCI Express 2.0 lanes, as in the Intel X58 chipset for Nehalem.) So QPI was apparently designed for absolutely different applications, you can see it on the picture above. Processors with the new architecture, designed for the server segment, will contain several QPI controllers to connect to each other directly for the optimal implementation of the NUMA memory architecture (Non-Uniform Memory Access). It's widely used in server platforms from the nearest competitor.
Thus, server modifications of Core i7 will topologically become similar to AMD Opteron. That's OK, because designers of server software will finally get an answer to the question what memory architecture to optimize their applications for. However, it's the server segment. And what concerns the desktop segment, you will hardly notice advantages of QPI.
Write a comment below. No registration needed!