Integrated memory controller
Many people say that the most obvious reason to use a three-channel memory controller in Nehalem is Intel's reluctance to adopt AMD designs -- they don't want to borrow from the competitor. However, having thoroughly analyzed AMD's toils and trouble with its integrated memory controller, we understand that Intel showed good judgment here instead of emotions or esprit de corps. You may remember that AMD had to redesign the memory controller from DDR400 to DDR2-800 once already, because requirements of some applications had gone dangerously close to maximum bandwidth. It certainly led to a different processor socket, different motherboards, and other perturbations hated so much by common users (especially those who intended just to upgrade their old computers). With the three channels supporting DDR3-1333 (server modifications codenamed "Nehalem-EP") or DDR3-1066 (desktop Nehalems) of the memory controller integrated into Nehalem, Intel probably intends to rid of the necessity to overhaul this unit in the nearest years, or at least to change it only insignificantly. For example, the company may add support for higher-frequency DDR3 memory to future CPUs without the need to upgrade a motherboard (dream on…)
What concerns the controller itself, we are promised unprecedented speed of data exchange (32 GBps is obtained by multiplying maximum bandwidth of DDR3-1333 by the number of channels, so it's crystal clear that we deal with a theoretical maximum value, not real results), low latency (why not -- memory controllers in Intel chipsets traditionally demonstrated low latencies), and some "Aggressive Request Reordering". Judging by the title, it's probably the most interesting feature of the new controller. However, no significant information is shared about this technology so far.
Hyper-Threading technology (Simultaneous Multi-Threading)
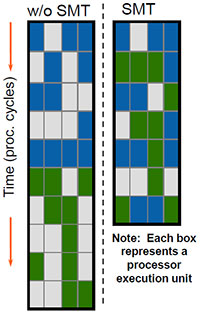
We actually deal with the Hyper-Threading technology again, once forgotten after discontinuing NetBurst processors. It emulates several logic cores based on one physical core. The diagram also seems to have migrated from the old presentation (they probably decided that no one remembered the old one anyway).
Just like Pentium 4, the new reincarnation of Hyper-Threading suffers from some of the "hereditary diseases", for example, load/store/reorder buffers are divided between two virtual cores strictly by half. So HT support may just as well reduce performance (but we should note that it rarely happens in practice). On the other hand, theoretically Nehalem's HT must work better than in Pentium 4 -- not because of cardinal improvements in its technology, but just because some units critical for this technology are much "wider" in Nehalem than in Pentium 4 (we'll cover this issue in the next chapters).
Besides, we come across information in Internet from time to time that Intel somehow split physical and logical cores in Nehalem and made them unequal to give programmers an opportunity to finetune their programs to multiprocessing with HT-enabled CPUs. Frankly speaking, we cannot imagine how it's possible -- when HT is enabled, all cores become virtual, and the first emulated core based on the physical core cannot be "more virtual" or "less virtual" than the second, lest all "honest" programs experience problems. What is probably meant here is an opportunity to find out (using assigned CPU numbers?..) whether threads are executed on virtual cores of the same physical processor or of different physical cores (the second situation is preferable from the point of view of providing maximum performance of a given process).
On the whole, Hyper-Threading support in quad-core desktop processors should be taken as an ideological move rather than concern for higher efficiency of CPU utilization: only 0.5% of desktop programs can use 8 (!) cores efficiently, and these programs are so specific that common users may have never heard of them.
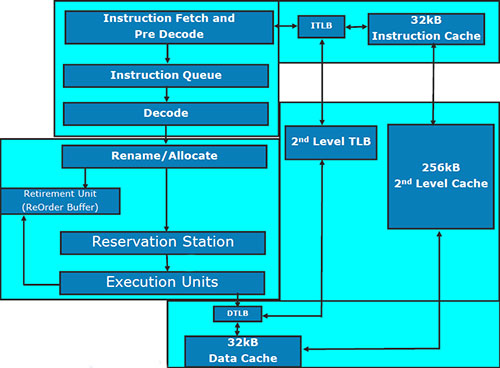
Execution core
We deliberately avoid the term "computing core", as "executing core" seems to be more accurate: this unit not only computes, but also decodes instructions. Besides, not all commands in x86 code are computational.
Most part of the changes in Core i7 versus Core 2 can be described like this: "something added, something expanded". Such improvements are usually easy to explain: the new fabrication process provides more transistors, so there is no need to save on them. And now we recap the most relevant changes.
Decoder
The main changes in the decoder have to do with further improvement of the macrofusion technology: it used to work only in 32-bit mode, but now it supports all CPU modes, including 64-bit ones. The number of command pairs decoded by this technology per cycle has also been increased. Theoretically, Core i7 decoder will demonstrate full efficiency (five instructions per cycle) more often than in Core 2.
Cycle processing
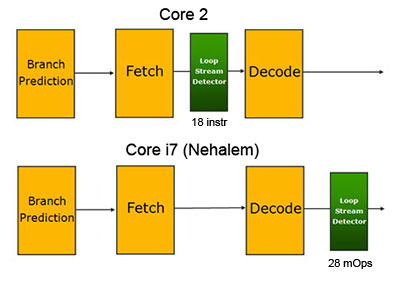
Loop Stream Detector, designed to store short cycles instead of reloading them from L1/L2, first appeared in Core 2 processors. In Nehalem this unit goes after the decoder, so it holds already decoded commands. This idea came from Pentium 4, Trace Cache.
Branch prediction
The branch unit has been doubled: it's now divided into two parts, one of which works with fast branch prediction (it probably copies the corresponding unit from Core 2), while the second part is slower, but it employs deep analysis and a capacious buffer to predict those branches that are missed by the fast unit.
Intel also promises that Return Stack Buffer (responsible for function return addresses) was expanded to Renamed RSB even back in Penryn. It might have made mistakes from time to time with complex algorithms, but it won't anymore.
Instruction execution
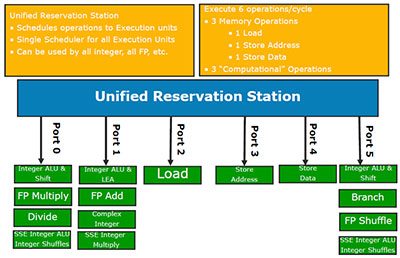
Units responsible for execution of instructions are almost unchanged in Nehalem. By the way, this suggests one simple, but not obvious conclusion: in those cases when Core 2 copes with prefetching instructions and data, decoding, and branch prediction, the above-mentioned improvements of Core i7 won't give it any advantages, and it will perform on a par with Core 2.
However, there are still some improvements that have to do with Hyper-Threading support. They are obvious: Reorder Buffer is expanded to 128 microoperations, Reservation Station -- to 36 instructions (from 32). And data buffers: Load from 32 to 48, Store -- from 20 to 32. The reasons are also clear: it's done to increase the number of commands and data in the execution queue, thus raising chances of executing them in parallel.
New instructions (SSE4.2)
As we have already determined above that Intel offers no global innovations in execution units of Nehalem, this small addition to the instruction set looks consistent: unlike SSE4.1 in Penryn, SSE4.2 contains only seven new instructions. Intel calls two of them "Application Targeted Accelerators", that is instructions intended to accelerate applications rather than algorithms. One of them calculates CRC32 to accelerate the iSCSI protocol. The second instruction calculates the number of non-zero bits in an operand, it's used in generic engineering and voice recognition programs. The remaining five instructions have a common assignment: they are all used to accelerate algorithms of syntactic XML analysis. As you can see, it's all peace and quiet, no sensations…
Write a comment below. No registration needed!