 |
||
|
||
| ||
|
||
|
||
| ||
 CONTENTS
General informationWe are starting probably the most complicated material in the history of our 3D-Video section. Why is it so? - The answer will be given a little later and it consists of a couple of words. What is XGI? Officially the company was founded in 2003 by the employees of Trident's graphics department bought by SIS and by SIS's own graphics department. It means that Trident sold its business to SIS which in its turn left it for new-founded XGI. XGI is actually created by SIS, but unlike S3 Graphics, which is not independent and belongs to VIA, XGI is an independent firm. Moreover, SIS didn't even provide its graphics trade mark (Xabre and others). But it doesn't mean that all new products from XGI are developed from the very beginning. Look at the collage above. It clearly shows that Volari is identical to Xabre II. When SIS tried to promote its Xabre its roadmap targeted the release of that product for 2003. But it turned out that the Xabre made no good, and the card makers refused to use it because the Xabre had a lot of weak sides. Chaintech brought out a lot of cards based on this processor, and it still tries to empty its overfilled stocks. Many companies had to suffer losses in the attempt to sell them for any possible price (hence Xabre400 cards priced at $35 by retail). SIS had to decide either to close the graphics department or let it exist independently. Well, they decided on the second option. It takes at least 1.5..2 years to develop a new graphics product from nothing provided that the developers have a good experience and previous generations at hand (like in ATI and NVIDIA). In this case the company launched its product half a year after the company was founded. Moreover, it was a dual-chip DirectX 9 product! No doubt that they used previous solutions from SIS. And it looks like that the changes in the software and hardware section were minimal. If you look at the drivers' screenshots below, you will notice traces of SIS Xabre - even the control panels didn't change their look. The worst problem of all second-echelon manufacturers (Trident, SIS, XGI) is that they do not properly interact with game developers until games are released! They make gaming products, and it implies that their 3D power must be fully realized in games! At the same time, the game developers rarely test their products on such cards. That is why the programmers (from companies producing cards) have to debug such products after such applications are released. In most cases they simply reduce a quality degree or disable certain functions. Maybe it could be acceptable in 1998, but not in 2003-2004! Users do not need such blurry images these days. The second problem is that they are too naive regarding latest technologies, in particular, effective memory access, memory optimization, caching and calculation optimization. ATI and NVIDIA produce very complicated chips containing 110-130 M transistors, and the technologies mentioned are widely used there; most of them were polished during several chip generations. Unfortunately, Trident's slogan (after which the company sold its graphics department) - "30M transistors in our products yield the same performance as 100M of NVIDIA and ATI" - gave no rest to Trident, SIS and evidently VIA. But there are no wonders. It's not enough to provide the core with 4-8 rendering pipelines, 8 texture units... They must make them work correctly, eliminate downtime, think about caching, tile technologies of calculation optimization, create drivers and shader compilers which could optimally use all hardware capabilities. It takes time and resources, dozens of years of thousands of experts. Besides, if shaders are used all 8 rendering pipelines promised become a fiction because there are twice (or maybe 4 times) fewer shader pipelines. That is why SIS's products in shader applications fall far behind their competitors! The effect from SIS solutions is noticeable here. XGI's products have twice fewer shader pipelines. Let's see what XGI offers (from the weakest solution to the top one):
This solution looks more advanced compared to Xabre; at least, it features hardware support of vertex shaders in contrast to Xabre (the latest drivers got the software support). But it's only specification. Let's see what the tests will show. Have a look at the block diagram of the single V8:  See how the memory bus is organized: 4-channel (32bit each) memory controller. This is a positive effect, though it's not 256 bits typical of latest solutions from ATI and NVIDIA. Now look at the Duo:  Obviously, dual-processing is based on the old principle of master and save processors. They have a special internal bus between them marked as X-Link (also known as BitFluent). This is actually the internal AGP2x, 32 bits wide and working at 133 MHz. The processors work similarly to those in the ATI RAGE MAXX - everyone renders its own frame, but unlike to ATI's product, the chips do not wait for each other to sync when rendering is completed. The disadvantage is a low throughput of the internal bus which transfers data from applications and the slave processor which also constantly reports its results to the master one. Besides, in such configuration most data duplicate in both memory buffers, and each chips fulfills caching separately and less efficiently compared to one chip with the 256bit memory bus. Dual-processor video cards were tested a lot of times already, and every had its own peculiarities. The 3dfx Voodoo5 had excellent realization of the chips' combined operation but the product's cost price was too high. It's clear that in case of ordinary gaming applications which do not exceed the bounds of modern games and top solutions from ATI or NVIDIA the dual-chip configuration with 128bit memory buses will always be less efficient (especially regarding its price/performance ratio) than an advanced single-chip solution with a 256bit memory bus and a more complicated higher-frequency core. That is why the only explanation of a dual-chip configuration is that the developers couldn't create a chip of similar efficiency and/or complexity which would be adequate to the best products from ATI and NVIDIA. Below are the comparison features of the XGI Volari Duo V8 Ultra. We
took NVIDIA GeForce FX 5900 Ultra and ATI RADEON 9800 PRO 128MB for comparison
as they have a similar price of $400. The RADEON 9800 PRO can be currently
bought at $320-330, but there are no other products from this company priced
at $400.
For more detailed list of the chip features supported by the DirectX drivers see: Card
It's obvious that the PCB itself is very complicated. Although it supports only a 128-bit memory bus for each chip, here we have a 256bit bus with DDR-II support, which requires a 10-layer design:  Here are the processors:   They are built on the 0.13 micron technology at UMC's factories. The package is expensive - FCBGA, but it's impossible to produce so complicated chips in other packages. Each chip officially consumes 20W, but the main power consumer is DDR-II memory. The card consumes around 120W(!), which is greater that power consumption of fastest cards from ATI and NVIDIA. That s why it needs additional power supply through two connectors (the power supply unit is not simple).  By the way, the coolers have pleasant lighting.
It's interesting to compare this card's length with the widely known dual-processor Voodoo5 5500:  As you can see the newer product is shorter than the older one :). The Volari Duo V8 Ultra supports VIVO. While the TV-out is based on SIS 301,  Video-In is realized with the Conexant BT835:  Our colleague Alexey Samsonov who studies VIVO and TV tuners has already seen this codec and looks forward to testing it :) Finally I must say that the card doesn't lock any PCI slots though it's not small.  Accessories:
Retail package:
OverclockingIt's not easy to overclock such a complicated device, but the card was able to work at 370/1000 MHz. Setup and driversTestbed:
Video cards used for comparison:
Driver settings
       The driver settings have the panels identical to the Xabre. Test results2D graphicsUp to 1600x1200@75Hz there are no complains about 2D quality. Remember that quality depends on a sample and a card-display "cooperation". First of all one should pay attention to display's and cable's quality. Remember that 2D quality is tested on the ViewSonic P817-E monitor together with the Barco BNC cable. D3D RightMark Synthetic Tests (DirectX 9)In this review we will show the test results obtained with the flexibly configurable synthetic tests for API DX9. The synthetic suite from the RightMark 3D currently includes the following tests:
The philosophy of the synthetic benchmarks and their descriptions are given in the NV30 review. If you want to try the synthetic tests of RightMark 3D or measure performance of your own accelerators please download the latest version of our test available at D3D RightMark Beta 3. They have a common shell and a flexible export of scores. Besides, you can download all test settings used in this review. If you have any comments, ideas or reports on errors please e-mail to unclesam@ixbt.com. Pixel Filling
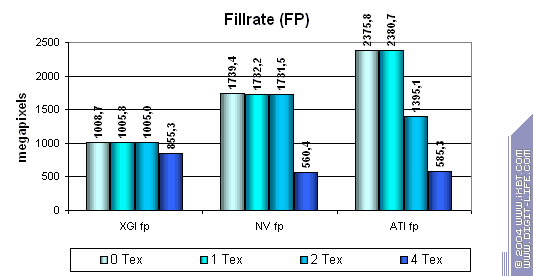 In case of textures 0 and 1 the scores are almost equal . It means that the benchmark runs well and texture sampling doesn't affect the process - we measure only the fillrate and frame buffering. We can see that NVIDIA has two texture units per one pixel pipelines while ATI has one unit but a greater number of pipelines. Volari's effective fillrate seems to be limited by some factor (presumably, by the memory write speed). In fact, until the number of textures reaches 4 per pixel the fillrate does not fall down. It's possible in two cases - either the real V8 configuration is 4x2 instead of 8x1 or/and the effective memory bandwidth of each chip is not sufficient for recording data of all pipelines without lowering the speed. Both factors look sad as there are real applications where both factors may have a strong effect. For example, sky rendering in fly simulators or prerendering of depth data for shadows in the Doom III. It's possible that the chip is made as a super-pipeline with 8 texture units and several parallel ALUs which process a different number of pixels per clock depending on algorithm's complexity (hence a lower number of pipelines indicated in the specs for pixel shaders). So, the main conclusion is that the chip couldn't cope effectively with this simple task but for the case with 4 textures where it outscored its competitors at the expense of the total number of 16 texture units. So, the frame buffer doesn't work that effectively, the configuration of 16x1 yields to its competitors' 8x1 and 4x2 in most cases. The theoretical limit of 5600 M pixels is unreachable for two V8 because of the inefficient chip and memory system architecture. Earlier we used fixed functions (which are supported yet since DirectX 7) for estimating a fillrate. Let's see how it changes for different shader versions: 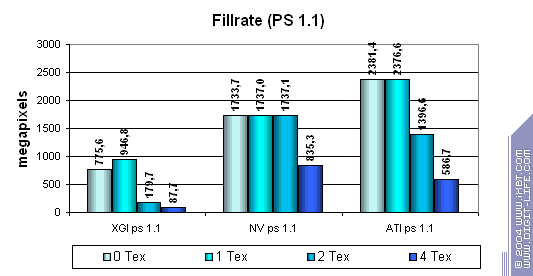
 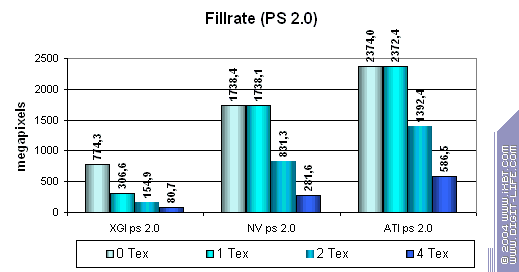 While the competitors process simple shaders without speed losses (except 2.0 on NVIDIA in case of 2 textures, though it's rather a useful anomaly of the optimization compiler rather than the architecture's downside), XGI loses to them making this specified feature only a line in the specs. Note that the fillrate drops with every additional texture used. The computational resources of the texture units and shader pipelines are probably shared (i.e. the same ALU array is used both for interpolation of coordinates and for shader calculations).  In case of small textures the Volari looks competitive, but as their size grows up the scores are getting lower probably because of ineffective caching and memory operation. This card falls behind its counterparts even at 128x128, not to mention 256x256 though they are the most popular sizes in real applications! The number of pipelines remains just a number if you can't feed all of them in time. 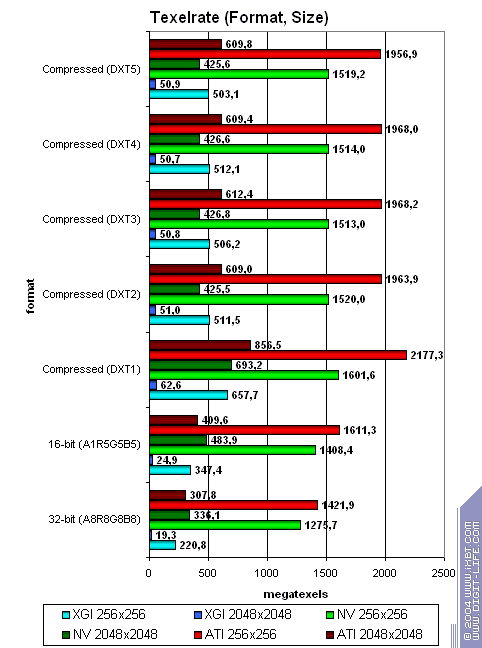 While Volari uses all its power to cope with a texture of 256x256, NVIDIA's and ATI's cards demonstrate excellent quality and detail level of 2048x2048(!) at the same speed, though the physical memory bandwidth is narrower. 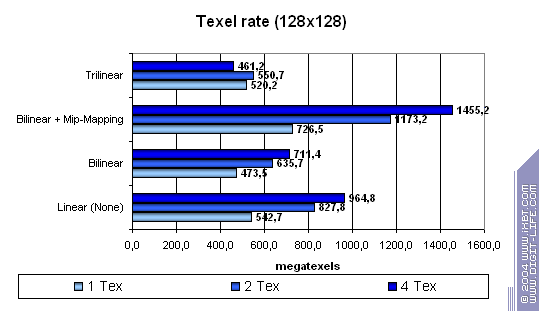 The bilinear filtering is almost "free of charge" for Volari (like of any proper modern chip), the mip levels make caching more effective which is especially beneficial for a large number of textures. The trilinear filtering is not free, the texture units get paired - the speed drops most of all in case of 4 textures. Earlier the difference was eliminated by the low effectiveness of the frame buffer operation. 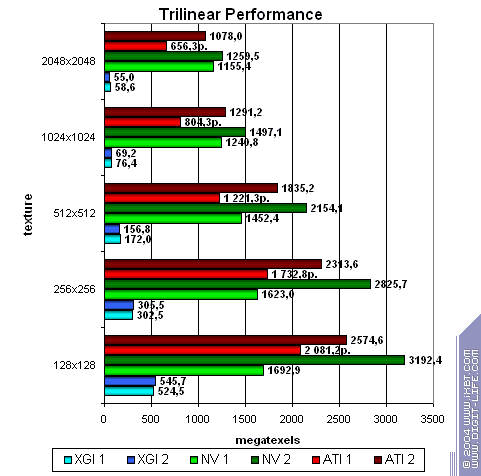 Terrible. Geometry Processing SpeedNow let's estimate the geometry processing speed.
 It's not that bad yet. As the complexity grows up ATI (which doesn't have special hardware support for quick emulation of the old fixed T&L) begins losing to Volari. But XGI's peak bandwidth is not that great and could look better in comparison with previous-generation cards. NVIDIA remains a leader in all tests, the fixed T&L remains its strong side thanks to special hardware units (a special additional instruction for a vertex shader) which quickly fulfills complex calculation of a lighting sources. Well, this is the first synthetic test where Volari doesn't look that awful! On the other hand, the limit of ~60M triangles and such a week dependence on the task complexity makes us think about software or soft hardware T&L emulation. Such dependence can be on account of the AGP bus and the resultant 60M triangles are not unachievable for modern SSE2 processors. 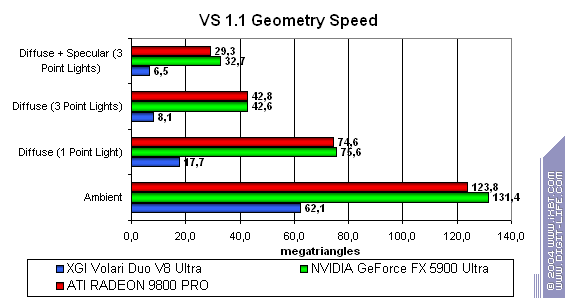 Volari is "beyond" any competition again.  This is NVIDIA's weak point (the indirect register indexing is not that fast and makes the loop speed pretty low in almost all popular algorithms) makes it close to the Volari. However, even with this well-known disadvantage XGI can't beat its competitor. It is twice as slower as NVIDIA (!), not to mention ATI. Hidden Surface RemovalMaximal HSR efficiency vs. scene complexity (HSR performance), and the averaged difference of processing of a chaotic scene and an optimally sorted one (HSR algorithm quality) on the texture-free scene. The results with texture sampling won't be shown as Volari's performance is very low in this case: the real HSR efficiency of this chip can be measured only without them: 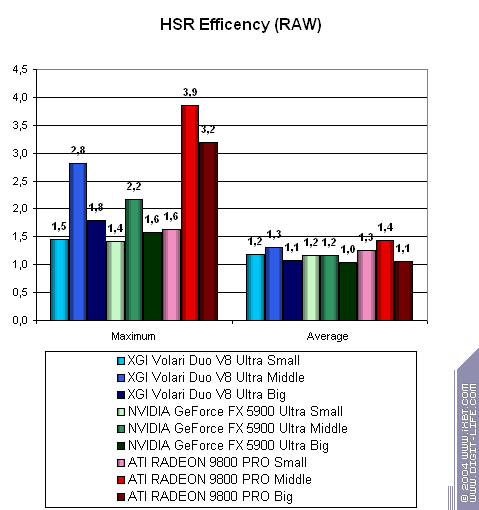 So, ATI has the highest maximal theoretical efficiency because of the hierarchical Z buffer. Besides, Volari has a kind of splash in this case on the scene of average complexity. NVIDIA takes the last place, but Volari's bottlenecks in other cases bring to nothing such potential advantage. Probably, the Volari's HSR has more than one clipping level. The chips look approximately equal regarding the algorithm efficiency. Most of them are well balanced for scenes of average complexity. Pixel ShadingPerformance of hardware processing of pixel shaders 2.0:
 This is a sad story especially in case of one shader. Volari loses to everyone. NVIDIA loses to ATI, the difference between 16 and 32 bits is not that noticeable on the latest drivers. ATI keeps ahead regarding pixel calculations (but not texture sampling). 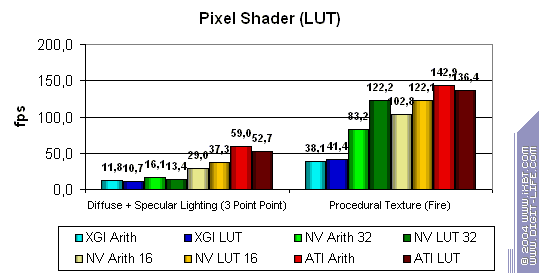 There are no great changes, NVIDIA got a small advantage. Volari is closer to ATI, though the absolute scores are incomparable - Volari drags far behind ATI. Point SpritesPoint Sprites vs. size: ATI and NVIDIA excellently cope with their tasks while in Volari this function has the minimal level of realization because of the inefficient frame buffer. 3D graphics, 3DMark03 v.3.40 - synthetic testsAll measurements in 3D tests were carried out at 32bit depth. Fillrate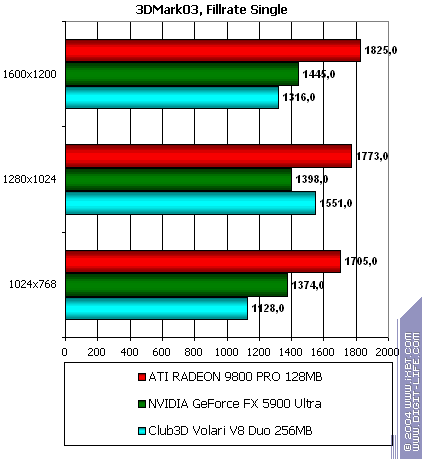  Multitexturing:   The data are close to the D3D RightMark, though this time Volari's scores look better in case of one texture (but they are still several times lower than its theoretical limit). ATI and NVIDIA demonstrate lower scores. They have different approaches to realization of these synthetic tests, but we are inclined to trust to our own fillrate measurement technique, which sources are available at D3D RightMark site. Pixel shader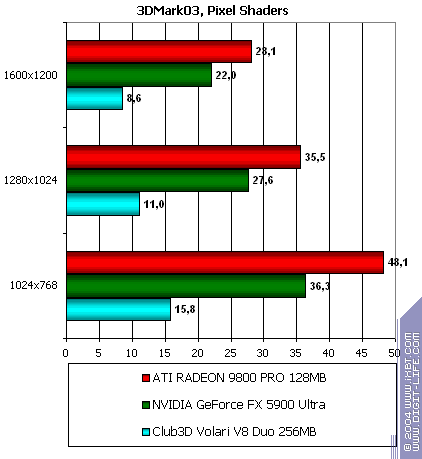  The scores well match the above ones. Vertex shaders
  The scores match those obtained before. Summary on the synthetic testsThe conclusion looks pretty sad:
These facts do not let us hope for an acceptable speed in real applications. Moreover, we can see that Volari's achievements are not comparable even to middle-end cards which are 2-3 times as cheap. The chip architecture is poorly designed, the developers do not have enough experience and expertise. 3D graphics, 3DMark03 - game tests3DMark03, Game1Wings of Fury:
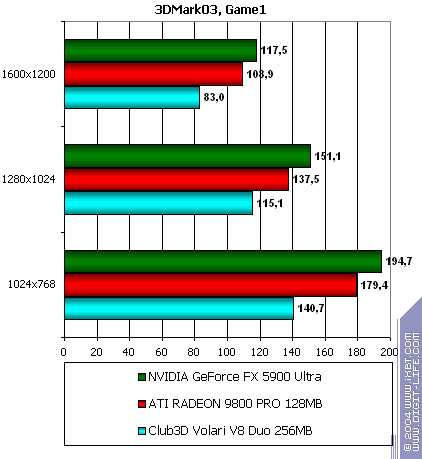
 3DMark03, Game2Battle of Proxycon:

 3DMark03, Game3Trolls' Lair:

 3DMark03, Game4Mother Nature:
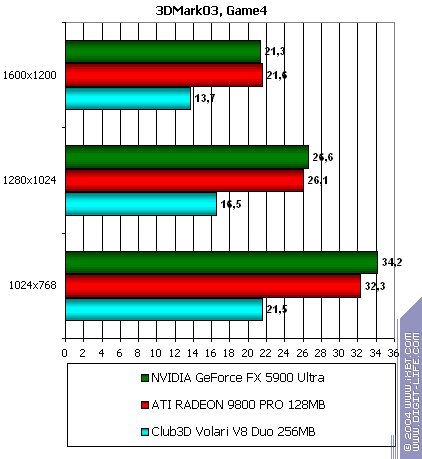
 Even the cheats do not help XGI's card. Below you will see quality demonstrated by this card. Look at the shader speed. Is it enough for a dual-processor accelerator
priced at $400? [ Part 2 ]
Andrey Vorobiev (anvakams@ixbt.com)
Alexander Medvedev (unclesam@ixbt.com)
Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


























