 |
||
|
||
| ||
|
||
|
||
| ||
R[V]5XX Specifications
Specifications of reference cards based on R[V]5XX GPUs
Details: R520, RADEON X1800R520 Specifications
Details: RV530, RADEON X1600RV530 Specifications
Details: RV515, RADEON X1300RV515 Specifications
R520/RV530/RV515 ArchitectureWe are not going to publish our own diagram this time. Instead, we'll publish the scheme provided by ATI — it offers a praiseworthy detailing level and shows all necessary issues. 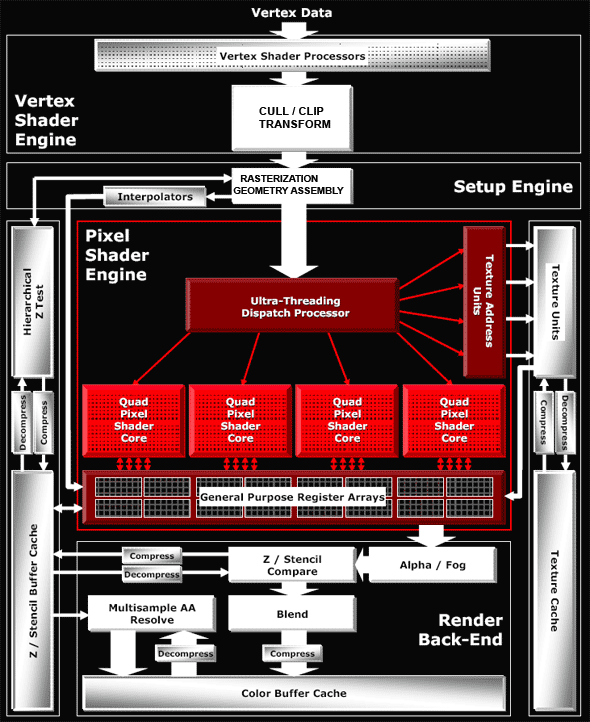 Architecture of vertex processorsThere are eight identical vertex processors (they are inside the Vertex Shader Processors unit on the diagram). They comply with SM3 requirements and are based on ATI's standard 3+1 scheme (ALU of each vertex processor can execute two different operations simultaneously over three vector components and the fourth component or a scalar). In fact, vertex processors have become similar to what we saw in NV4X and G7X, but without texture fetching. There is another exception — NVIDIA offers the 4+1 scheme (a four-component vector and scalar are processed per clock), while this solution is based on the 3+1 scheme. The G70 scheme can potentially offer higher performance. But the real difference may be practically unnoticeable, especially now that vertex processors rarely act as a rendering bottleneck. Architecture of the pixel partThat's the most interesting part. Have a look at the diagram — unlike NVIDIA, the texture units are outside the common pipeline. This architecture may be called distributed. There is no common long pipeline to run quads through, as in case of NVIDIA. The texture part exists separately — texture address units and TMUs. The same concerns pixel processors responsible for math and other operations, and data registers. This scheme has its pros and cons. The main disadvantage — it suits well the phase mechanism, when active texture sampling precedes texture calculations (Shaders 1.X and old programs with stages). But it is fraught with unjustified latencies in dependent texture sampling, which can be often found in modern Shaders 2.X and 3.0. Think about it — one texture fetch command actually calls a lengthy operation for many cycles and the shader processor should stand idle all this time? Nothing of the sort — ATI settles the point smartly! Moreover, it's a universal solution. Not only does it effectively execute dependent samples, it also increases efficiency of the pixel part in shaders with conditions and branches (compared to NVIDIA's approach). ATI calls this technology Hyper-Threading. Let's see how it works... The magic box (Ultra Threading Dispatch Processor) directs the execution process — it processes 512 quads simultaneously, each of them can be at a different shader execution stage. Each quad is stored together with its current status, current shader command, values of previously checked conditions (information on the current branch of a conditional jump). NVIDIA chips run quads in circle, one after another. The best they can do is to skip quads that don't fall under the current branch of a condition. The R520 operates differently — our magic box constantly monitors free resources (be it texture or pixel units) and directs queued quads into free devices. If a quad fails a condition and should not be processed by this or that shader part, it will not hang about in circles, taking up room and time, together with the other quads, which need to be processed. It will just skip unnecessary commands and will not load a texture or pixel unit. If a quad waits for data from a texture unit — it will let other quads forward, which will load pixel units. This approach kills two birds with one stone — it hides texture access latency and allows efficient usage of computing and texturing resources when shaders with conditions and branches are executed. Efficiency of both issues depends directly on the number of quads that our magic box can process. 512 looks like an imposing set, we can get textures for four quads and process four quads in pixel processors per cycle; thus up to 8 quads are processed each cycle, while the rest of the quads wait for their turn or wait for data from texture units. Out of doubt, this unit is complex and the dispatching logic for this quad set takes up a considerable part of the chip, probably comparable with texture and pixel processors. Especially as register arrays actually belong to this unit as well — there must be lots of them to store efficiently all preliminary calculations for the 512 quads in queue. And now let's examine changes in pixel processors and ALUs. As we have already seen, pixel processors are grouped in four — that is we actually have four quad processors processing four pixels per cycle rather than 16 separate processors. Each quad processor consists of the following units: 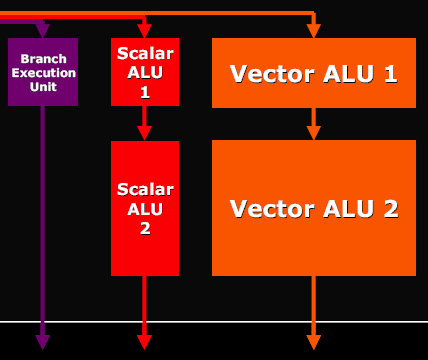 and can execute the following operations over four pixels per cycle:
Besides, don't forget that texture addressing (requesting data from TMU) can be done simultaneously with these five operations. Thus, in case of optimal shader code we get peak performance of six operations per cycle - it's similar to G70, if we take into account the difference in architectural approaches to branch execution. But as we have already mentioned above, the scheme from ATI is better at branching. Interestingly, ATI is true to its approach — 3+1 (two different operations can be executed, one - over three components of a vector, the other - over a scalar, being the fourth component). In the majority of cases, the approach taken by NVIDIA (an option of 2+2 or 3+1) can be considered more efficient, but this difference will have a little effect on typical graphics tasks. Another major issue of the new architecture — caching compressed data — Z / Frame buffer data as well as texture data are stored in caches in compressed form. They are decompressed on the fly, when they are accessed from the corresponding units. Thus caching efficiency grows higher. You can say that the cache sizes are virtually increased several-fold. It would be logical to assume that such an architecture with separated texture and pixel units will be easily scalable: 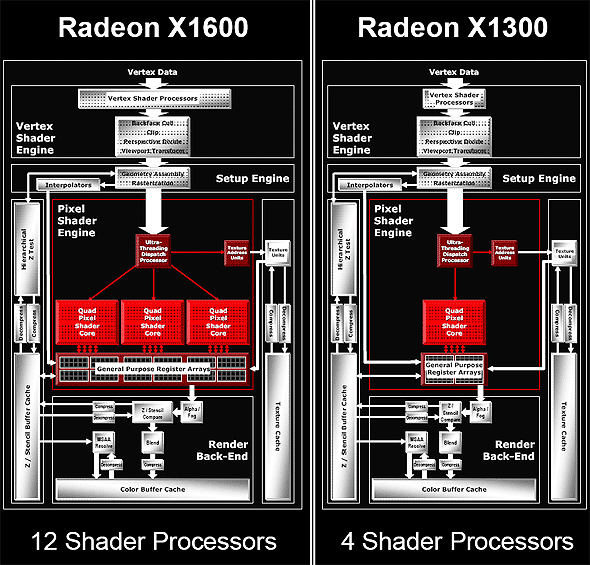 As we can see, RV530 and RV515 are built on the same scheme. There is only one quad left in the RV515 — it simplifies many aspects, including the magic box of the dispatcher. The situation with the RV530 is more complex — it has three pixel quad processors, but only one texture unit. That is we have 12 pixel processors and 4 TMUs, even if used in the optimal way, nearly without downtime. Of course, in case of simple shaders without complex calculations, pixel processors will be idle waiting for texture data. But modern shaders, for which this GPU is intended, are often up to much computing (5-8 commands) per one texture access, justifying this scheme. To all appearances, the number of transistors spent on the texture part of the chip is greater than in case of pixel ALUs. That's why this disbalance is justified from the point of view of ATI engineers. In fact, giving up 6-8 texture units allows to have 12 (instead of 8 or 4) pixel processors, sticking to the same GPU complexity. How justified it is in practice depends on efficiency of ATI texture units, on efficiency of the dispatcher, and on the ratio of various commands in executed shaders. Output interfacesAll new graphics cards support HDCP format for both DVI interfaces. Top R520-based models are capable of outputting HDMI (High Definition Media Interface, the interface for outputting video and audio to digital theatres and other audio-video playback devices of the new generation) to DVI connectors. You can read about popular interfaces in our R520 preview. Conclusions on the R520/RV530/RV515 Architecture
Details: R580, RADEON X1900R580 Specifications
The R580 is sort of a refined modification of the R520. It's the fastest modification with an increased number of pixel processors (a number of texture units remains the same). The only significant difference from the previous ATI flagship is three times as many pixel processors. But the number of texture units was not increased. That is this situation resembles what we had with RV530, where the 3:1 ratio was already obtained, even if with fewer pipelines. Our article analyzes how well this architectural solution performs versus its competitor. It also publishes performance analysis, caused by those additional 32 pixel processors in the R580. You should read about the R520 architecture above, because it's similar to R580, and it's described in more detail. 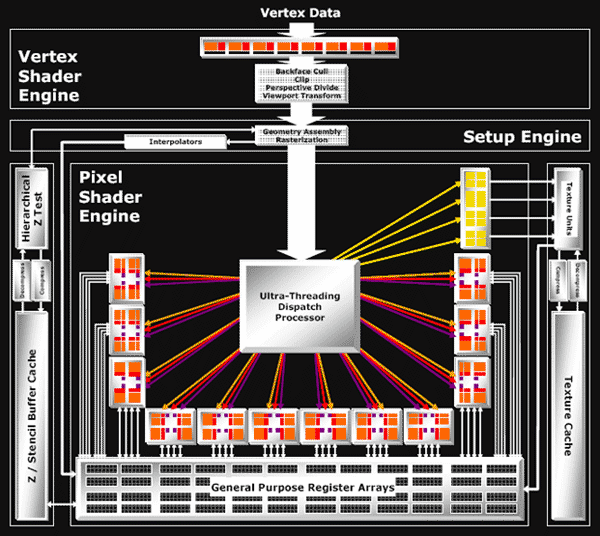 We can see on the diagram more pixel processors. But the number of texture processors remains the same - 4 quads (that is 16 textures fetched per cycle). There is direct evidence of disbalance, which was examined in our reviews by the RV530 example. ATI engineers are of the opinion that it's a reasonable compromise - computing/texturing ratio in modern games may reach 7-to-1 already. It's not easy to say how well this architecture is justified. We check it up in our articles with tests, both synthetic and gaming. We published a unique comparison of R520 and R580 operating at identical frequencies - they differ only in the number of pixel processors. This comparison shows where the additional computing power gives us an advantage, and where it's wasted. It goes without saying that only programmers of future applications will decide whether to prefer computing or no. But it will evidently happen sooner or later. Details: R580+, RADEON X1950R580+ Specifications
Specifications of the reference RADEON X1950 XTX
Specifications of the reference RADEON X1950 CrossFire Edition
It's a modification of the R580. There are few changes this time, none of them significant. The main and only significant difference consists in a modified memory controller and some GDDR4 bug fixes. Now the updated memory controller in the R580+ supports three memory types: DDR2, GDDR3, and GDDR4. According to ATI, the R580+ also has some minor changes: some caches were enlarged, HyperZ now works in up to 2560×1600. The other features remain the same: the number of transistors, pixel/texture/vertex processors, fabrication process. Some time ago many sources assumed that R580+ would be manufactured by the 80 nm fabrication process to cheapen its production costs, reduce its power consumption, and probably to increase its frequency in new products. But these expectations did not come true. Perhaps, the 80 nm fabrication process will be used in the next-gen GPUs (R600) and chips from the other price segments between R580+ and the next generation. As R580+ is almost an exact copy of the R580, which in its turn was a modified R520 solution, we recommend you read the corresponding reviews: RADEON X1800 (R520) and RADEON X1900 (R580). A CrossFire modification of the card has more differences now. GPU and memory clocks are identical in these cards. The only difference consists in one DVI and CrossFire connector instead of two DVIs and one TV-out. Recommended prices for these two models are also the same, both will come at $449. As we can see, specifications of R580+ and RADEON X1950 XTX are almost a complete copy of R580 and the RADEON X1900 XTX. The only difference from ATI's previous top model is GDDR4 memory. The core clock remains the same. The RADEON X1950 XTX and the RADEON X1900 XTX operate at the same clock - 650 MHz. But memory clock has been changed to 1000(2000) MHz, which seemed unattainable not long ago. Such a high operating frequency has become possible owing to the new memory type. The reference card RADEON X1950 XTX uses GDDR4 memory chips with 0.9 ns access time, which corresponds to 1100(2200) MHz. It's a tad higher than the operating frequency in our model. GDDR4 (Graphics Double Data Rate, Version 4) - a new generation of graphics memory, designed for 3D graphics cards. It's almost twice as fast as GDDR3. The main differences between GDDR4 and GDDR3 are increased operating frequencies (consequently, higher bandwidth) and reduced power consumption. Technically, GDDR4 memory does not differ much from GDDR3. It's just another evolutional step, which simplifies adaptation of the existing chips and development of future products supporting this new memory type. The RADEON X1950 XTX has become the first graphics card with GDDR4 chips. NVIDIA is planning to launch such products a tad later. They will most likely be graphics cards based on NVIDIA G80. The new memory type has been developed by Samsung and Hynix in cooperation with ATI, which orchestrated the process within the bounds of JEDEC. GDDR4 chips are currently manufactured by these two companies. But only Samsung has started their production on a mass scale. Big memory shipments to graphics card manufacturers started not long ago. Production of 1.2(2.4) GHz modules has been commenced in June. The company also announced its successful development of (1.6)3.2 GHz chips, twice as fast as GDDR3 can offer. Samsung currently manufactures three types of GDDR4 memory: 0.71 ns, 0.83 ns, and 0.91 ns ones, with operating frequencies varying from 1100(2200) to 1400(2800) MHz. We can only hope that problems with availability of GDDR4 memory (it's manufactured in limited volumes) will be solved. Advantages of the new memory modules over GDDR3 include not only performance - their power consumption is approximately 30-40% as low as the one demonstrated by GDDR3. Lower power consumption of GDDR4 memory allows to relieve requirements to power supply and cooling, or to increase power consumption of a GPU and retain the overall power consumption of the card. Power consumption can be reduced owing to lower nominal voltage VDD for GDDR4 - 1.5 V. So we can speak of power saving compared to GDDR3. But early chips installed on the RADEON X1950 cards use 1.8 V, just like GDDR3 memory. The most powerful solutions may use 1.9 V. That's why the X1950 XTX now consumes no less than the X1900 XTX, even though GDDR4 potentially consumes less power than the previous version of graphics memory. Increased memory frequency resulted in higher bandwidth. It's 64 GB/s for the RADEON X1950 XTX, higher than in any other single-GPU graphics card. For comparison, memory bandwidth of the NVIDIA GeForce 7800 GTX is 51.2 GB/s, the GeForce 7800 GTX 512Mb - 54.4 GB/s (the latter is equipped with the fastest GDDR3 memory). GDDR4 memory installed on the RADEON X1950 XTX has almost a 30% advantage in memory bandwidth over the previous flagship from ATI. It allows the new solution to enjoy a 15% advantage over the X1900 XTX under a heavy video memory load, such as high resolutions with antialiasing. Details: RV570, RADEON X1950 PRORV570 Specifications
Specifications of the reference RADEON X1950 PRO
Details: RV560, RADEON X1650 XT
Specifications of the RADEON X1650 XT
Both GPUs belong to the new generation, they are manufactured by the 0.08 µm fabrication process. The core is absolutely the same in size and the number of transistors. Physically, RV560 and RV570 are the same GPUs in different packages. The RV560 uses a 128-bit package for X1600 PCBs (these chips are cut down - one third of pixel and texture units). And the RV570 is packaged for 256 bit with a protective frame, for simplified X1900 PCBs. The new Mid-End GPUs from ATI were delayed several times. Perhaps it had to do with the new fabrication process - in other respects they have nothing new. The RV570 is almost identical to the existing RADEON X1900 GT, which is based on the cut-down R580. Now it's replaced with the RV570 with its 36 pixel and 12 texture units, that is featuring the same ratio of pixel/texture shaders used in the latest ATI solutions. But the chip has become much smaller, and its manufacturing is now much cheaper. The core clock remains the same, while the memory frequency has grown from 1200 MHz to 1400 MHz. The X1950 PRO has a similar PCB design to the one used in expensive X1900 cards. But the PCB was significantly simplified. Memory chips were rotated by 90°. The power supply unit is also simplified - it now has fewer analog elements. As the new GPUs are cheaper, and their PCB design is simplified, we get a good solution with the recommended price of $199. The RADEON X1650 XT takes up the place of the X1600 XT, which was renamed into the X1650 PRO. That is, the X1650 PRO and the X1650 XT are not based on the same chip operating at different frequencies, as we had thought, but they are two absolutely different GPUs. The X1650 PRO is based on RV530 with 12 pixel, 5 vertex, and 4 texture units. And the new card is based on RV560 with 24 pixel, 8 vertex, and 8 texture units. Some characteristics have grown almost twofold, but memory frequency and memory bus width are the same. So the computing power has grown much, while memory bandwidth may hamper performance significantly. If we take into account the recommended price of $149, this solution will be interesting anyway. The X1650 XT PCB differs from the board used in the X1600 and X1650 cards only in the layout of CrossFire connectors, because RV560 does not require a master card to support this mode. The other elements of design are not modified, except for a number of power line nuances. It should be mentioned that designs of both PCBs (for RV560 and RV570) now have connectors for special CrossFire cables. Support for CrossFire without master cards and GPUs is integrated into the GPU. There has finally appeared an option to join two usual ATI cards into CrossFire, as NVIDIA SLI has allowed from the very beginning. PCB designs allow to plug two adapters or a single wide adapter. The matter is that SLI can transmit signals only one way at a time, while the new CrossFire is able to send them both ways simultaneously. Besides, adapters will be actually flexible cables. So the distance between graphics cards doesn't matter. And SLI usually uses rigid adapters of fixed length. Reference Information on RADEON R[V]4XX Graphics Cards Reference Information on RADEON R[V]5XX Graphics Cards Reference Information on RADEON R[V]6XX Graphics Cards
Alexander Medvedev (unclesam@ixbt.com)
Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||














