 |
||
|
||
| ||
|
||
|
||
| ||
Time has come to announce a new version of a universal RightMark Memory Analyzer benchmark. The trend that we noted in RMMA 3.0 continues here and hopefully, will also continue in the future. Namely, there are more innovations than just corrections in this version. Of course, some changes have been introduced too, but they are mostly focused on making the tests more convenient in use. Changes in RMMA tests
The first change concerns the D-Cache Latency test
that initially had a large number of settings.
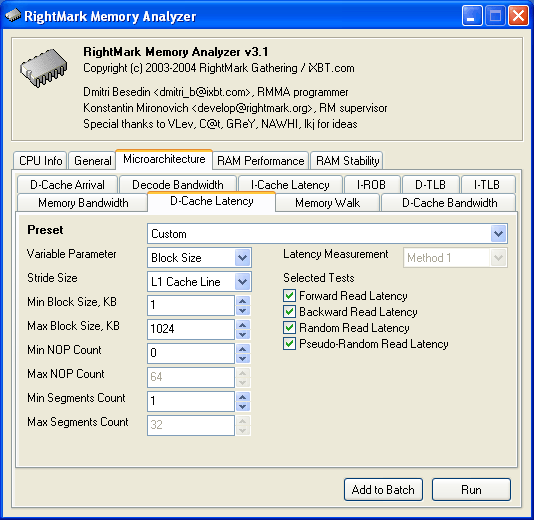 You can see that Mininal Walk Step Size and Maximal Walk Step Size parameters and consequently, the test variant Variable Parameter = Walk Step Size have disappeared. But we didn't remove anything, we just realised this function as a separate subtest described further.
The second change concerns the I-Cache Latency test.
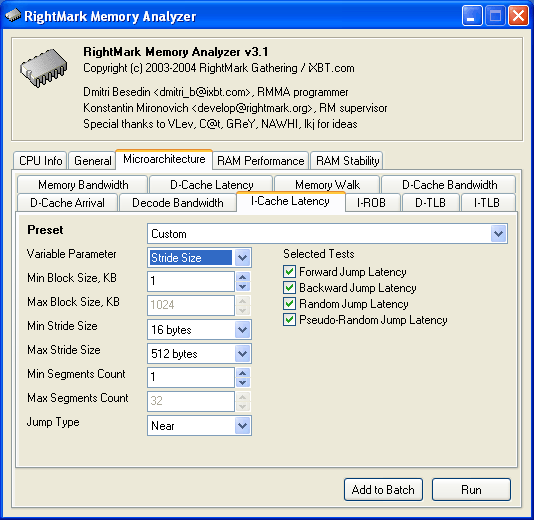 This test, on the contrary, has been enlarged by a new variant: Variable Parameter = Stride Size, that enables to form a dependence of jump instruction execution latency from the stride size between two successive jumps. The option may be useful for measuring the "effective" size of the I-cache line. New RMMA testsAnd that's about all for the changes. Now it's high time we examined new tests realised in RMMA 3.1. Memory Walk test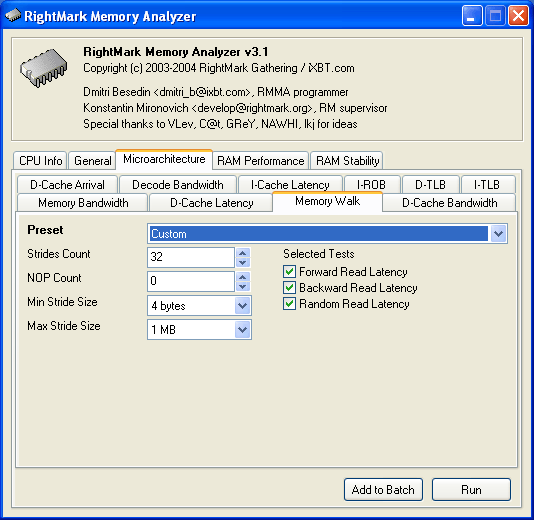 As has been mentioned above, this test is, in fact, a variant of the D-Cache Latency test. It was placed into a seaprate tap in order to simplify the settings. The test has the following parameters: Strides CountStrides Count — the number of strides in the dependent access chain. Because the stride size itself varies within a wide range in this test, it is much more sensible here to specify this parameter proper instead of the block size as it was in all other tests. NOP CountNOP Count — the number of voids (operations not related to the cache/memory access) inserted between each successive accesses to the cache/memory. Minimal Stride SizeMin Stride Size, bytes, in the dependent access chain. Maximal Stride SizeMax Stride Size, bytes, in the dependent access chain. Selected TestsSelected Tests define reading modes when testing latency:
So, the Memory Walk test reads a fixed number of chain elements that are separated by an offset with the value between Minimal Stride Size and Maximal Stride Size. The procedure allows to estimate the size of the segment belonging to the data cache level we're dealing with. And that, in turn, increases significantly latency of the access to this level. Evidently, if you want to know the size of a segment belonging to a particular data cache level you have to select the Strides Count that would exceed at least by one the associativity of the level. I-ROB test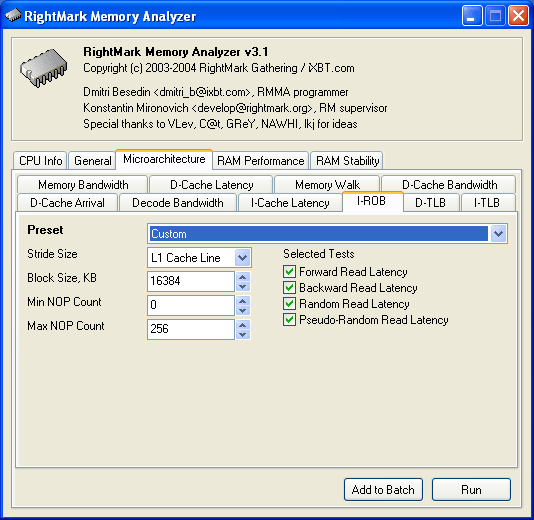 The next microarchitecture test is designed to identify the size of the instruction reorganisation buffer. This buffer is installed in all modern CPUs that execute the code in an out-of-order way. The test is based on the following principle. If we want to make a CPU reorganise an instruction execution, we only have to load some very slow but simple operation that wouldn't occupy the CPU's executive resources. And then we give the CPU a long chain of other simple instructions that wouldn't depend on each other or the result of the first operation. In our case, a dependent data loading from memory will suit perfectly for the "simple but slow" operation; and NOPs (xchg eax, eax) could serve as the "simple independent" instructions. Thus, the succession of instructions executed by this test looks as follows: // a simple but slow operation dealing with the memory access Because the first instruction will be executed in at least hundreds of CPU clocks in the right conditions (a large size of the data chain, random reading mode), such load will be enough to reorganise the execution (i.e. — to launch it simultaneously with the memory access) of at least two or three hundred NOPs (considering that modern CPUs execute them at 2-3 operations/clock). This number will exceed the size of any existing I-ROB. And I-ROB exhaustion will manifest itself in an increasing latency of the memory access starting from a certain numbre of NOPs, as it will entail a consecutive execution of other NOPs that haven't found room in the buffer. This test has parameters mostly similar to typical settings of cache/memory latency tests. Stride SizeStride Size, bytes, in the dependent access chain. Block SizeBlock Size, KB — the memory size used for building and reading the chain. Minimal NOP CountMin NOP Count — the minimal number of voids executed by the CPU. Maximal NOP CountMax NOP Count — the maximal number of voids executed by the CPU. Selected TestsSelected Tests define reading modes:
The latter two modes are preferrable for this test because memory access latency is usually higher in these conditions than in the case of forward/backward reading that enables an effective activity of the Hardware Prefetch algorithm. Memory performance tests
The following tests realised in RMMA 3.1 are competitive and serve for comparative testing of memory performance.
It is essential to note that the tests have strict requirements for both the real memory bandwith and for the CPU's computing power. Thus, they can rather be refered to a mixed type that measures performance of CPU/RAM as a whole.
The first test (Checksum) estimates the CRC32 and Adler32 checksums using algorithms that were realised by Mark Adler in
zlib. It has the following parameters: Min Block Size (KB), Max Block Size (KB), Selected Tests — CRC32 Checksum and Adler32 Checksum.
By default, the test uses large data volumes that exceed the CPU data cache size.
The other test (Substring Search) simply realises a search for the substring of a text of a given size (parameter Substring Length, bytes) in a large-size text array (limited by parameters Min Block Size, KB and Max Block Size, KB).
In this test version, the text array is made of random symbols within the range (0x20 — 0x7F). That is, the symbols are common for a text that contains figures, capital and small Latin letters, punctuation marks, etc., while the substring is represented by a text fragment made of the program title. For exapmle, a substring 64 symbols long will look like this:
The test supports two searching modes specified by Selected Tests: Case-Sensitive (considers the case of the symbols) and Case-Insensitive. The latter mode requires that the case of each symbol of the text array be transformed and thus, this test is executed at a much lower speed than the first one devoid of such transformations.
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. |














