|
||
|
||
| ||
|
||
|
||
| ||

CONTENTS
April is over, as is our trip to Toronto (Canada) where we first saw the ATI novelty (codenamed R420 then). For those willing to know more details about ATI Technology Days, here are the links to the first and the second days of the forum. Today we'll take a closer look at the new products. Why do we say it in plural? The thing is, there are several R420-based cards. Today we'll take two of them, RADEON X800 XT and X800 PRO. Not long ago we issued an article on NVIDIA GeForce 6800 Ultra, and its announcement contained a certain doubt: will NV40 be a long-term 3D-king or will the powerful R420 oust it? Well, today we'll try to answer this question.

Radeon X800 official specs
Specs of the actual R420-based cards:
General chip scheme

Observant readers will immediately see that the scheme virtually coincides with NV40. But that comes as no surprise: both companies seeking to create an optimal solution have been sticking to an effective time-proved organisation of the general structure of graphic pipeline for several generations. The differences are inside the units and first of all, in pixel and vertex processors. R420 as well as NV40 has six vertex processors and four separate pixel processors each working with one quad (a 2x2-pixel fragment). Evidently, there's only one level of data texture caching here, in contrast to NV40. Each of four quad processors can be excluded from work. Due to market demands or defected chips, one can exclude one, two, or even three processors thus producing cards that can process 4, 8, 12, or 16 pixels per clock. And now we'll traditionally increase detalisation level in the most interesting parts:
Vertex processors and data selection
Here's a schematic of an R420 vertex processor:

The processor itself is represented as a yellow bar, and the blocks surrounding it are only shown to make the picture more complete. R420 is announced to have six independent processors (multiply the yellow bar by six). According to some sources, R420 vertex processors support dynamic execution control, but this information needs checking. Anyway, this option is not available in API for the moment. But if it exists, it will be used in OpenGL and probably to the full. Although it will hardly appear in DX9, as its vertex unit fit neither VS 3.0 full specs (no access to the textures), nor NVIDIA's extended 2.0 specification (the so-called 2.0.a). In respect of the arithmetic performance per clock, an R420 vertex processor (like an NV40 one) can simultaneously execute one vector operation (up to four FP32 components) and one scalar operation. Let us remind you a summary table of modern vertex processors' parameters concerning DX9 vertex shaders:
There's one more interesting aspect that we'll dwell on a bit later, namely, FFP (T&L) emulation performance. It will be recalled that R3XX's lag from NVIDIA chips was largely caused by the absence of special hardware lighting calculation units that were used in three NVIDIA generations to speed up T&L emulation. Hopefully, ATI developers have analysed the number of applications that make a partial or a full use of T&L, made certain conclusions, and improved the situation.
Pixel processors and filling organisation Let's examine the R420 pixel architecture in the order of data sequence. This
is what comes after the triangle parameters are set: 
Now we are going to touch upon the most interesting facts. First, in contrast to earlier R3XXs that only had one quad processor taking a block of four pixels (2x2) per clock, we now have four such processors. They are absolutely independent of one another, and each of them can be excluded from work (for instance, to create a lighter chip version with three processors in case of them has a defect). The scheme looks a lot like that of NV40, but there are also fundamental differences which will now constitute the subject of our discussion. To begin with, a triangle is divided into first-level blocks (8x8 or 4x4 depending on rendering resolution) and the first stage of discarding of invisible blocks takes place basing on the data of mini Z buffer allocated fully on the chip. The buffer's size is not announced, but to all appearance, it is a little below 200 KB in R420. All in all, this stage can discard up to four blocks per clock, i.e. up to 256 invisible pixels. The second stage divides blocks into 2x2 quads, and fully invisible quads are discarded basing on L2 Z buffer (2x2 granularity) stored in the video memory. Depending on the MSAA mode, an element of the buffer can correspond to 4 (no), 8(MSAA 2x), 16 (MSAA 4x), or even 24 (MSAA 6x) pixels in the frame buffer. Hence its classification as a separate borderline structure between a mini Z buffer allocated fully on the chip and an ultimate base-level Z buffer. Thus, NVIDIA products have a two-level organisation of HSR and Z buffer, while ATI products have a three-level one. Later on, when we deal with synthetic tests we'll pay attention to the infuence this factor has on performance. Then quads are selected and distributed among active pixel processors. And this is where dramatic differences between R420 and NV40 appear: Algorithm of an NVIDIA pixel processor:
Shader instructions loop
Algorithm of an ATI pixel processor
4-phase loop
Thus, NVIDIA executes the instructions gradually, running all the quads in processing through each of them. ATI, on the contrary, divides the shader in four phases, each of which selects the data of the necessary textures and then makes calculations with the data. It's impossible to say which approach is better. ATI is worse for complex shaders, but on the other hand, calculations within each of the four phases are executed on a scheme similar to CPU. During calculations, a full-value pool of temporary registers can be used with no loss in performance or penalty for using more than four registers, as is the case with NV40. Besides, ATI requires pipelines with less stages, and consequently, less transistors are expended and potentially higher clock frequencies can be reached. It's easy to predict a shader's performance and to write the code (no need to worry about equal grouping of texture and computation instructions or expenditure of temporary registers). However, there are a lot of restrictions. They concern the number of dependent selections, the number of instructions within one phase, the need to keep "at hand" (that is, right in the pixel processor) the whole shader microcode for four phases. And there can be potential delays in case intensive dependent selections follow each other. ATI approach is, in fact, optimal for shaders 2.0 that have a rather limited length and no dynamic execution control. We will face problems if we try to fit such architecture with an unlimited shader length or an unlimited flexibility in texture selections. The scheme of the pixel processor contains the F buffer logic (mechanism for writing and restoring parameters of shader's temporary variables). This trick allows to execute shaders that exceed pixel processor restrictions in the length or the number of dependent (and standard too, in fact) texture selections. But the payment comes in the form of additional passes, which makes the solution not so ideal. The more complex the shaders will become, the more passes and data temporarily stored in the video memory there will be. As a result, ATI will have a higher penalty compared to NVIDIA-like architectures that are not limited by the length or the complexity of the shader. Well, real game applications will show which approach is better. And don't forget about energy consumption: flexibility of NV40 shaders comes at the expense of 220 million transistors which can prove to be too high for the 0.13 technology. Now we're getting back to the features of the R420 architecture. Processors have the FP24 data format in calculations, but TMUs have higher precision in operations with texture coordinates at texture selection. In this respect, the situation is the same as in the case with R3XX: there are two ALUs for each pixel, and each ALU can execute two different operations on the 3+1 scheme (R3XX had only one ALU). See DX Current for more details. Random masking and post-operational component rearrangement are not supported, everything is within shaders 2.0 and a bit longer 2.0.b shaders. Thus, depending on the shader code, R420 can execute (per clock) one to four different FP24 operations on vectors (up to 3D) and scalars and one access to the data already selected from the texture in the given phase. Such performance is directly related to the compiler and the code, but it's evident that we have: Minimum: one access to the selected texture data per clock The peak variant exceeds NV40 capabilities. But we should also consider that in reality, this solution is not so flexible (always 3+1 scheme) in terms of compiling the instructions into superscalar clusters. Tests will show real effectiveness. Computation effectiveness of the new pipelines has increased twofold against R3XX. And together with a twofold increase of their number and a gain in clock frequency, we get a solid theoretical advantage comparing to the previous generation. All new modifications will be available in the new version of shaders 2.0.b when the new SDK and the new DirectX 9 version appear (9.0c). Here's a summary table of capabilities:
NV40's flexibility and programming capabilities in DX9 are unrivalled for now. Now let's get back to our scheme and look at its lower part. It contains units responsible for comparison and modification of colour values, transparency, depth, stencil buffer, and also MSAA. In contrast to NV40 that supports generation of up to four MSAA samplings basing on one pixel, R420 generated up to six of them. And Z and stencil buffers have performance twice higher than the base filling rate of 32 values per clock (the same as in NV40). Thus, 2x MSAA is given with no speed penalty, and 4x and 6x take two and three clocks, respectively. However, if we use pixel shaders at least several instructions long, this penalty ceases to play any crucial role. Memory bandwidth is much more important here. Of course, MSAA modes compress both colour and depth data, and in the best-case scenario compression coefficient is close to the number of MSAA samples and makes 6:1 in the MSAA 6x mode. In contrast to NV40 that uses RGMS, R420 (as well as all R3XX chips) supports pseudostochastic MSAA patterns on the 8x8 base grid. As a result, the smoothing quality of edges and slanting lines becomes better. New drivers have the so-called Temporal AA that changes patterns from one frame to another. Thus, if the picture of the neighbouring frames is easily averaged by our eye (or by an LCD), we'll get an improved smoothing quality. Performance will not fall, but the effect can manifest itself in different ways, depending on the display and frame calculation frequency in the application.
Technological innovations

Boards
We can see that R420 looks very much like his predecessor R360 in terms of design. Only arrangement has been changed a bit because of the GDDR3 memory. Evidently, R420 pins are fully compatible with R360. Also noteworthy, there's still only one external power connector, and the cards consume far less energy than NV40.
Now let's take a look at the cooling system and see what has been changed here.
Thus, X800 has taken on all positive aspects of its predecessor, such as low power consumption and one-slot cooling system.
Interestingly, the X800 family already supports VIVO with the help of the good old RAGE THEATER, while 9800XT
was made for the new Theater 200, although we have seen no cards with it. ASUS was the only one to make 9800XT with VIVO.

Now let's look at the chip. First of all, we'll compare the sizes of R360, R420, and NV40 dies:

It is clearly seen that R420 has a larger die comparing to R360 (180 against 115 mln transistors), but NV40 has the largest one (222 mln transistors).
Now the chip itself with the case:
R360 R420 XT
R420 PRO
The dies were made late in March or early in April. There are no visible differences between the chips' resistors, both in marking and arrangement. Which makes us think that pipelines were cut softwarily, through drivers. But this idea needs checking.
Now for the overclocking. Due to Alexei Nikolaichuk, the author of RivaTuner, this utility can already estimate frequencies in R420.
Here's what X800 XT gives us:
 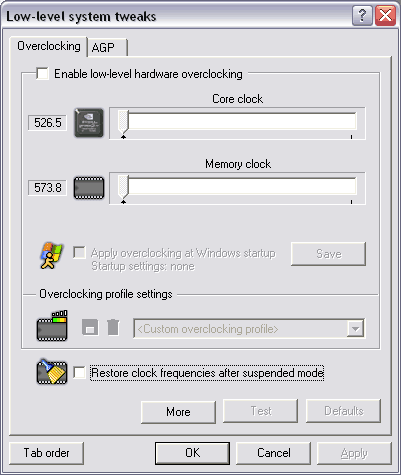 Unfortunately, the card is hard to overclock, and even minute frequency changes result the driver bringing the frequency back to the initial level.
And here are X800 PRO frequencies:
 Here, overclocking is possible: it was 540 MHz for the chip and 580 (1180) MHz for the memory. To check how the card works at X800 XT frequency, we fixed 525/575 (1150) MHz overclocking frequencies and tested X800 PRO at them. Installation and driversTestbeds:
VSync was turned off, S3TC was turned off in games.

There's no sense in describing beta drivers, as they offer the same features as usual CATALYST 4.4.
But the access to the so-called Temporal AA is available only via Registry:

Note the TemporalAAMultipler variable. It's the one responsible for this AA mode. 0 and 1 mean Temporal AA is off, while 2 and 3 mean vice versa. The latter differ only by pattern swap frequency (3 is the highest.) The TemporalAAFrameThreshold variable contains threshold FPS over which Temporal AA is enabled. 0 stands for permanent enable. E.g. if you set it 60, there won't be Temporal AA if fps is below 60. As the very essence of thie feature bases on eye perception and luminophor or LCD operation, it's impossible to make screenshots of Temporal AA. I can just state that if fps differs much from refresh rate, slight flickering becomes noticeable on edges of adjoining objects. I tried to record a movie of this with my digital camera. The result (7MB) is avaiable via this link. AA can be seen on the thick beam edge, and is not applicable to the grating as it's based on a semi-transparent texture. Test resultsBefore we briefly comment the 2D quality I'll repeat that there's currently NO fully-fledged methods to evaluate this feature objectively because:
Still the samples tested with Mitsubishi Diamond Pro 2070sb
demonstrated excellent quality at the following resolutions and refresh
rates:
D3D RightMark synthetic testsWe used D3D RightMark Beta 4 (1050) available at http://3d.rightmark.org One more time I'll state that all RightMark results were obtained on the Pentium4 system. D3D settings were:
D3D RightMark: NV40, NV38, R360, R420 Attention! Note that the current DirectX version coupled with current drivers doesn't offer 2.0.b features. They are to become available in DirectX 9.0c and the new SDK. All tests include results from NV40 review, so we'll just comment differences and behaviour of R420 (Radeon X800 XT) and 12-pipeline R420 (Radeon X800 PRO). Pixel Filling testPeak texelrate, FFP, measured for various amount of textures applied to a single
pixel: 
R420's theoretical maximum is 8.4 gigatexels/s. Actually we reached 7.5 gigatexels/s that unambiguously witnesses for 16 texture units. Single textures are applied better by NVIDIA due to pixel processor architecture. And this isn't optimal mode for R420 due to expenses related to the single phase of this test. Two and three textures allow R420 spread wings and beat NV40. Higher clock rate (125MHz clock rate difference x 16 pipelines is no joke.) Neither card's results jumped switching between odd and even digits (that is usual for TMUs-per-pixel configurations. The next test is fillrate / pixelrate, FFP, measured for various amount of
textures applied to a single pixel: NV40 wins over R420 with single textures or constant colors and loses in all other modes. NVIDIA shows higher peak frame buffer performance (0 textures - flood fill and single texture), but ATI does better with texture sampling as their number grows. The higher clock rate does help. Let's see how fillrate depends on shaders: 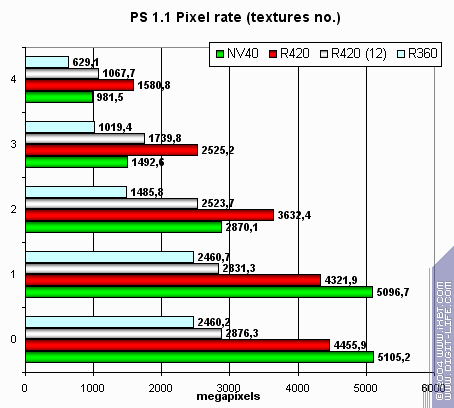
The same as with FFP All is the same again So, without any or with one texture NV40 looks better despite lower clock rate. This speaks for good frame buffer performance. But real tasks have not been limited by these frames for a long time already. Also note that now different shader versions have almost no effect on performance, so NV3X peculiarities are the past now, and the results are foreseeable and linear.
The following preferences emerge:
And now let's see how texture units perform caching and bilinear filtering
of real variably sized textures: 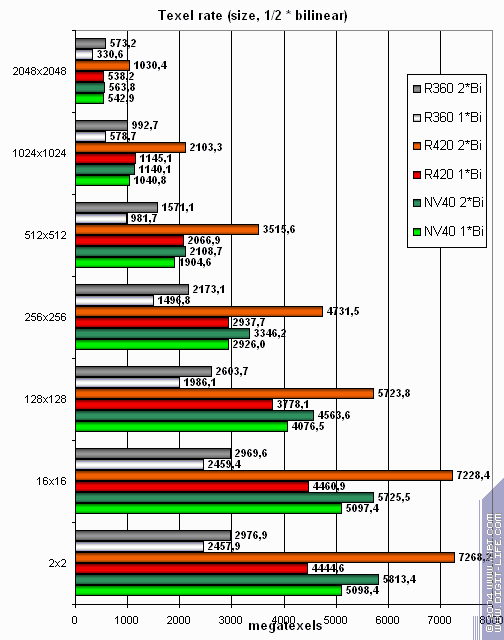
The results are given for various texture sizes; one and two textures per pixel. It's interesting that ATI hates single textures even if they are rather large! Very strange it is. Looks like some time expenses at phase switching and shader finishing. Or it's a product of texture module pipeline latency? Anyway, two textures change the situation to better. NVIDIA looks all right in this test, especially the bigger the texture is. Even ATI's higher clock rate doesn't enable R420 to dominate in all situations. Texture sampling has always been NVIDIA's advantage. Still NV40 doesn't win over R420. As >= is better than <= R420 is the winner. :-) Let's see if trilinear filtering changes this: 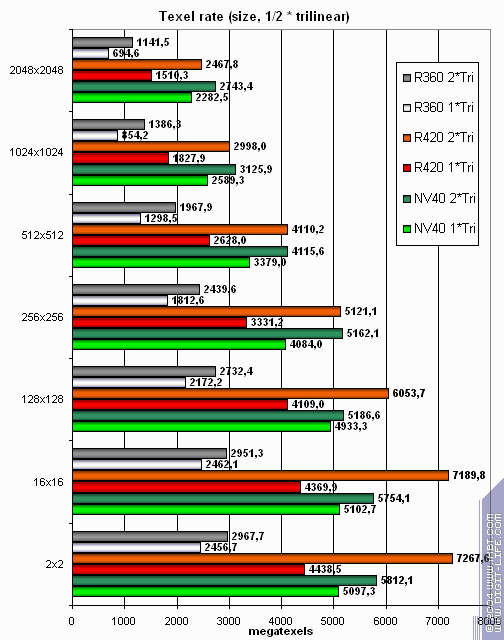
Wow! NV40 gets even closer to R420. MIP levels enable it to cache textures effectively. NV40's dual-level cache is of great help here. As a result, we can't say R420 is either winner, or loser. It's a wavering parity. Finally, the ultimate eight trilinear filtered textures: 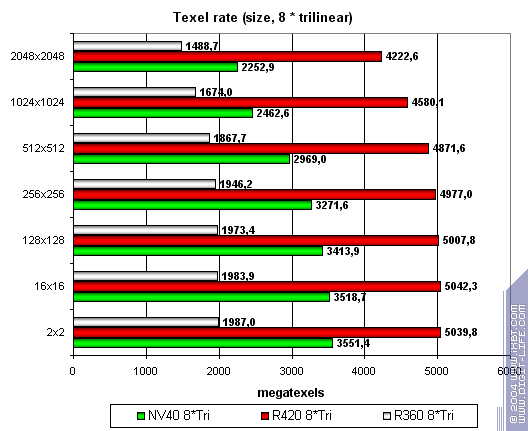
Everything's according to clock rate and pipeline amount, so ATI is the leader: And now let's look at texture unit performance dependence on texture format:
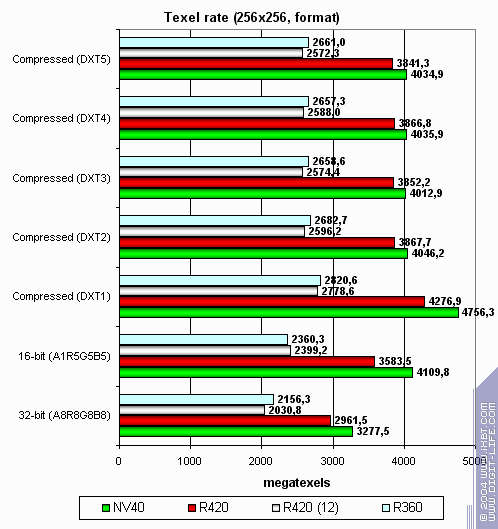
Larger size: 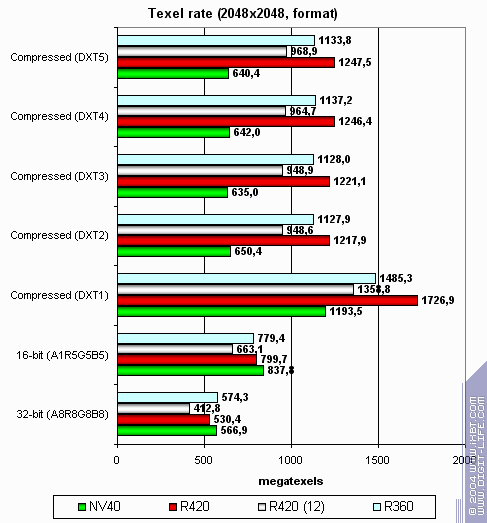
The picture is interesting. NV40 caches textures more effectively and its two-level cache rules. R420 works about the same with large textures (here memory is the bottleneck, while bandwidth is about the same) and does considerably better with compressed textures. Why ATI wins this much over NV40 with large compressed textures? It's simple: NVIDIA's texture texture cache keeps uncompressed textures converted to 32-bit format, while ATI has textures still compressed in the cache. On the one hand, NVIDIA will provide higher texture sampling performance due to fewer uncompression delays and lower latencies. On the other hand, large textures make ATI a leader as NV40 rests on memory bandwidth that even 16 TMUs can't help. You can clearly see this on the second chart. Depending on shaders, texture amount and size, etc. scale might incline to either side. In general, there are two facts to state:
Geometry Processing Speed test The simplest shader to measure peak triangle bandwidth: 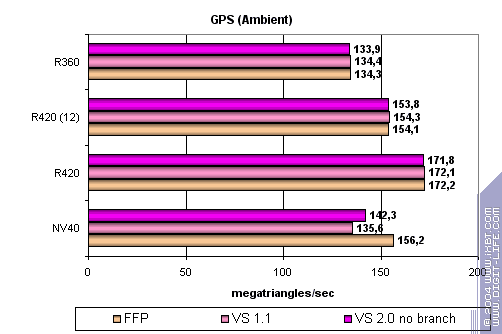
R420 is a leader with peak bandwidth perfectly scaled along with core clock. Why NV40 results are almost on the level of the previous generation. Hard to say. It seems its vertex processors just can't perform at full in this simple task. We'll check this later on more complex tasks. And now we'll state that the dependence of R420 performance on shader version is very close to that of R3XX: there's no dependencies at all :-) A more complex shader with a simple point light source: 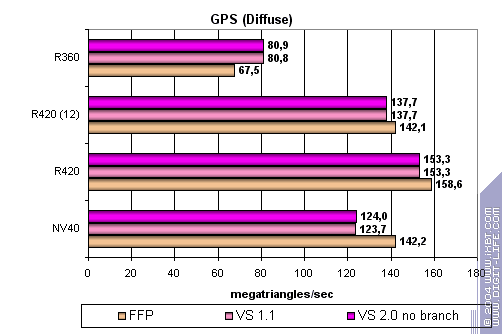
At last! ATI has finally provided effective T&L emulation, so now the performance is slightly higher, but not lower. The same 6 vertex units of NV40 don't do the thing at the lower clock rate. Increasing task complexity: 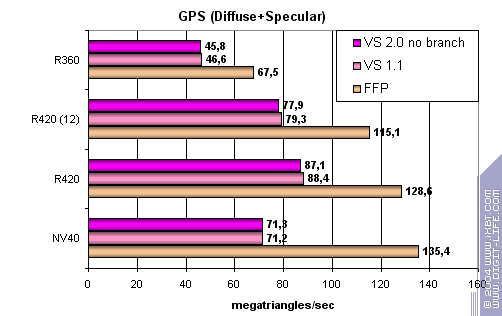
NV40 FFP is a leader here despite ATI's clock rate. FFP outruns shaders and we again find confirmations to our thesis of R420's additional hardware units. Though NVIDIA's are more effective, ATI wins in general. And now the most complex task with three light sources, in static and dynamic
transition variants: 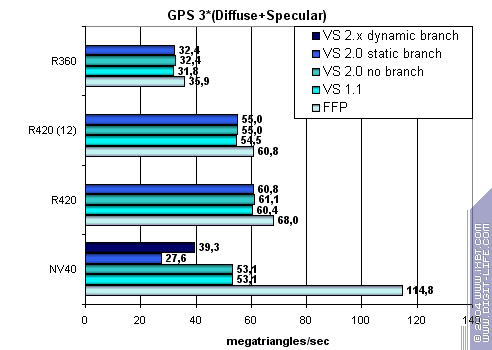
FFP performs good, while static transitions noticeable strike NVIDIA. The paradox is that NVIDIA's dynamic transitions are more beneficial than static. ATI performs smoothly and FFP is almost on the shader level. R420 is a general winner again. So:
Pixel Shaders test The first group includes 1.1, 1.4, 2.0 shaders rather simple for real time:
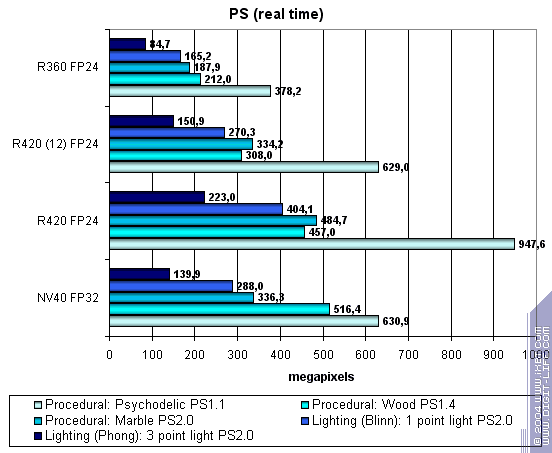
R420 is a general leader, though sometimes NV40 catches up (and even outruns with 1.4 shaders.) It's such a paradox that ATI's brainchild performs on NVIDIA products with more comfort. R3XX's good old pixel pipelines are well overclocked and optimized, while shaders 1.1 performance is just astonishing. The phase pixel pipeline described above is very close to 1.1 source architectures. Let's see if 16-bit FP precision helps NV40: 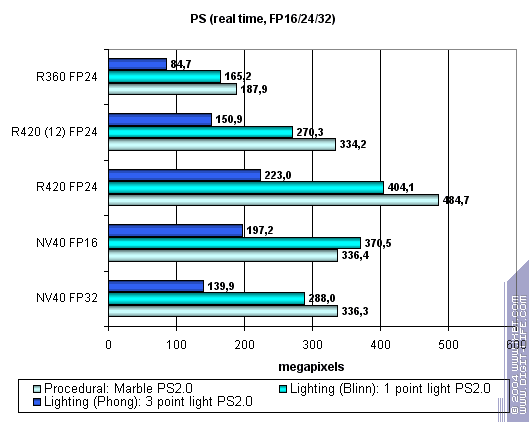
16-bit FP precision is an actual advantage of NV40, but R420's higher clock rate still doesn't give it a chance. And now let's try a really complex cinematic shader 2.a confined to R420 pixel
pipelines limits due to few dependent samples. 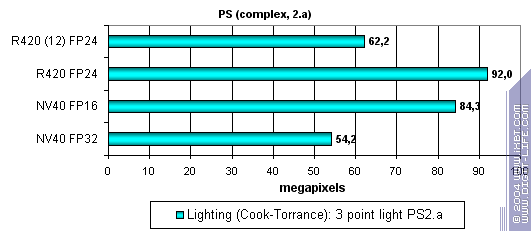
NV40 is more confident here, because its architecture is well adapted to long and complex shaders. However is can't win over R420 even using 16-bit FP precision. But there's place to expand - many texture samples and time variables, rather complex code. That's why 16-bit and 32-bit FP precision difference is that noticeable. Finally, let's examine the dependence of each GPU performance on arithmetic
and tabular sin and pow procedures and vector normalization: 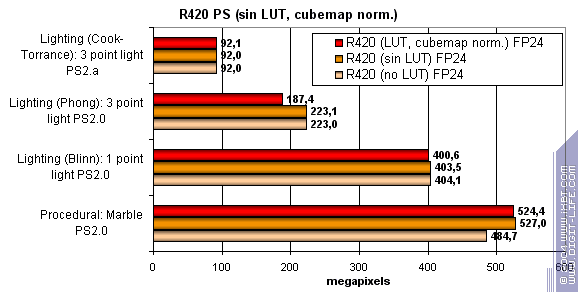
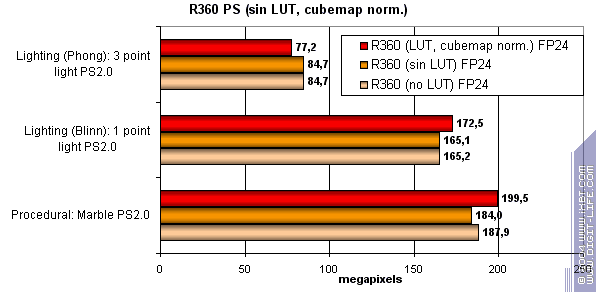
So, R420 depends on various procedures even less than R3XX. ATI's pride is a predictable and smooth architecture for any shaders 2.0. In both arithmetic and tabular procedures ATI performs as said above and thus leads clearly. Pixel shaders summary:
HSR testFirst, let it be peak efficiency (with and without textures) depending on geometry complexity: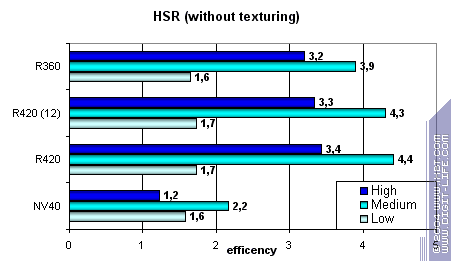
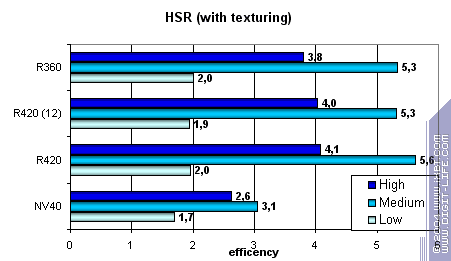
You can see that ATI performs in average and complex scenes better due to
two additional Z buffer levels (plus the basic.) NVIDIA traditionally
has one additional level, so its HSR efficiency is lower in an optimally
balanced scene of average complexity. You can see that HSR algorithm
itself hasn't changed and R350 and R420 efficiency is almost identical.
Therefore the culled/coloured pixels per clock ratio hasn't changed.
But the absolute values grew significantly: 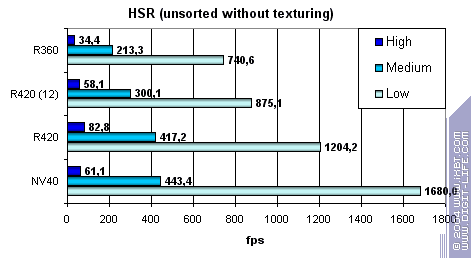
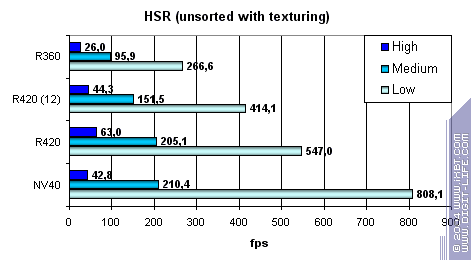
However they are not as good as NV40 is in low and mid-detailed scenes! However they strike back in high details and overlay factor. NVIDIA has very effective simple pixel colouring and HSR despite only one additional Z buffer level. Conclusion:
Point Sprites testSprites ceased to be popular innovation and often lose to triangles in the performance field. ATI performs better in this task, because NV40 rests on some strange limit, while R420 scales well. MSAA test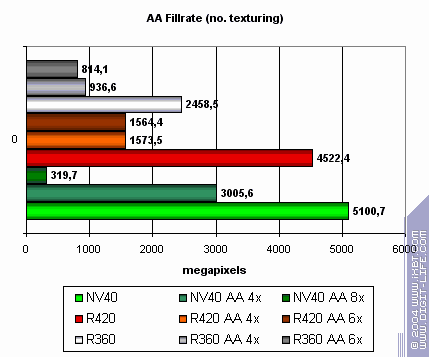
NVIDIA's MSAA is more effective in peak situations and performance drop at 4x is not that deep. But note that NVIDIA's AA is of some worse quality. You can clearly see that 8x of NV40 is a hybrid set with SSAA at which the performance drops below the allowed threshold. But 6x of R420 almost doesn't differ from 4x and that's good. Synthetic tests summary:
Trilinear and anisotropic filtering (High Quality)
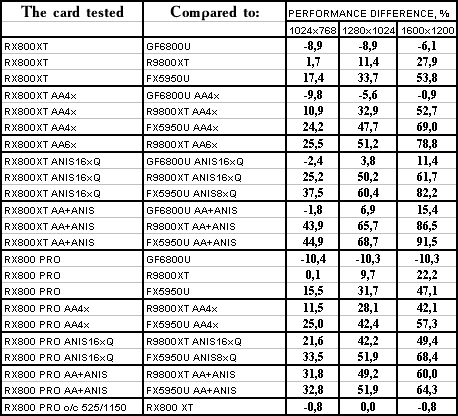
Test results: performance comparison
Note that all game test results were obtained on Athlon64-based system. We used:
If you need benchmark demos please write me an email. Note that we used both new, and old games in this test section. The reason was to show gamers that in such games a bottleneck IS NOT a powerful graphics card, but a CPU. More gaming test results will be provided in the next article. Quake3 Arena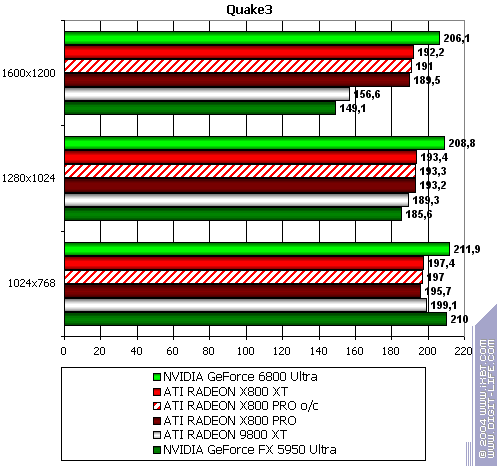 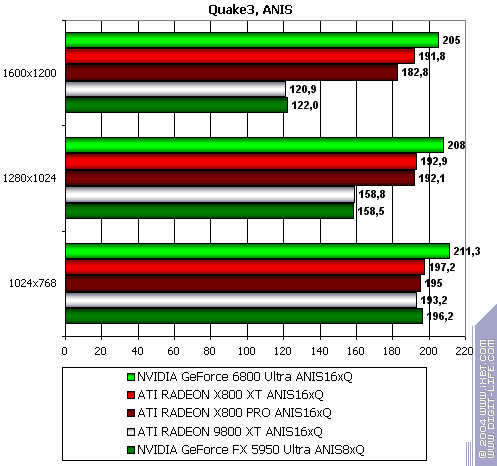 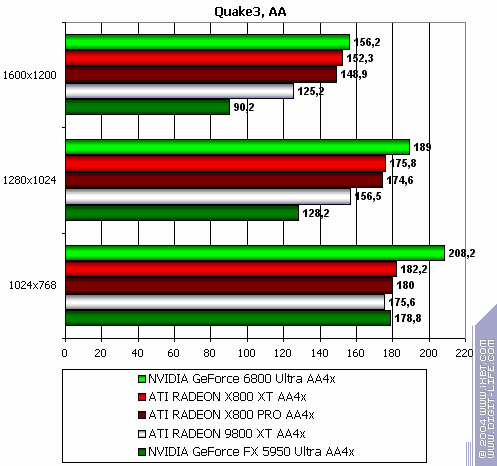 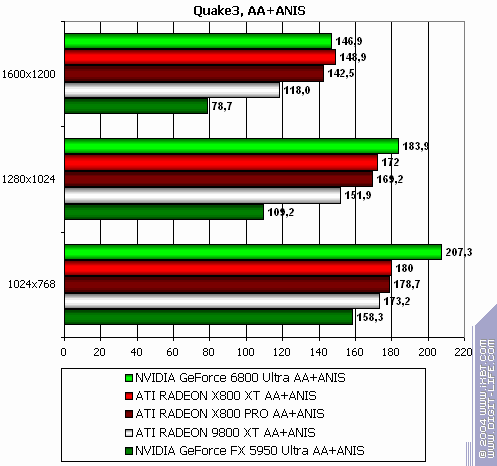 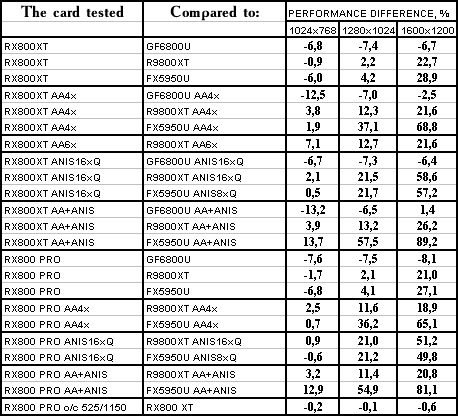
The lightest mode without AA and anisotropy: slight loss (due to CPU) The same with AA enabled The same with anisotropy enabled The hardest load, AA + anisotropy: almost equal, loses only in 1024x. Summary:
Of course, NVIDIA has the most debugged drivers for this game, so the result is rather predictable.
Serious Sam: The Second Encounter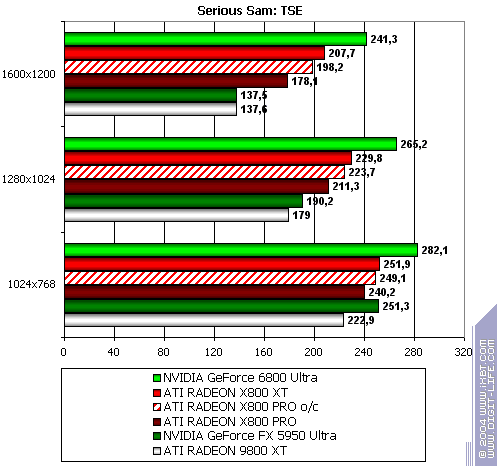 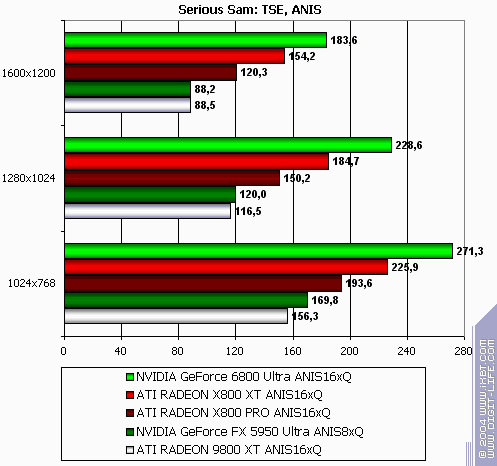 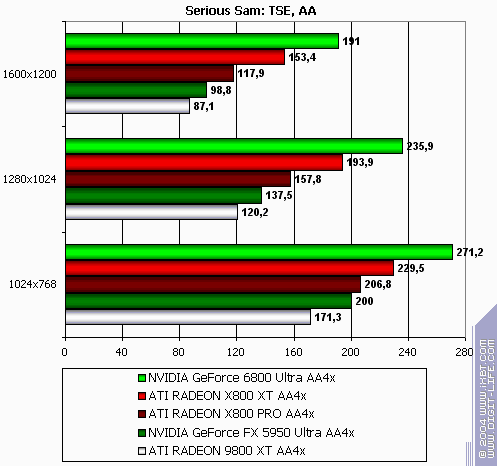 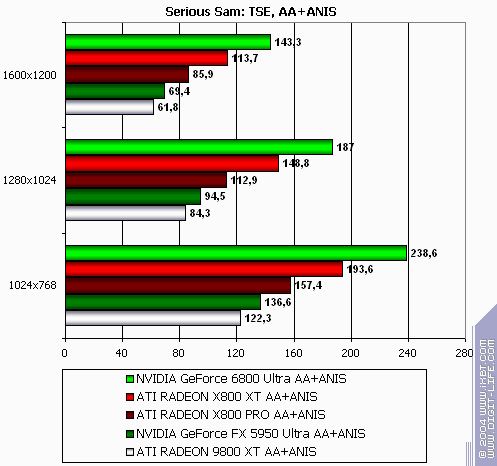 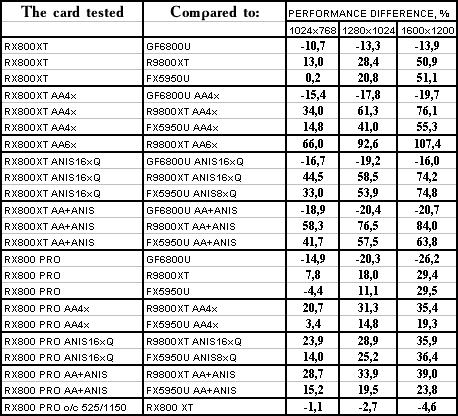
R420XT lost all modes. Resembles the situation above. Summary:
Return to Castle Wolfenstein (Multiplayer)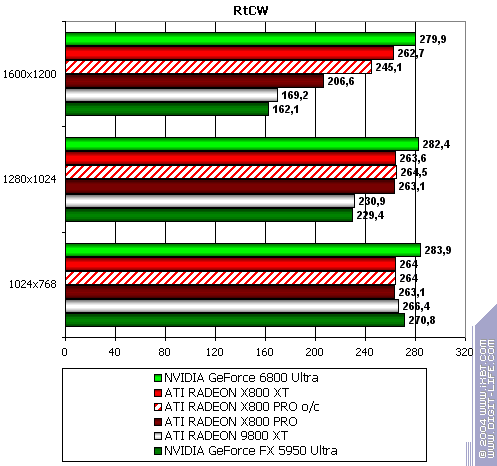 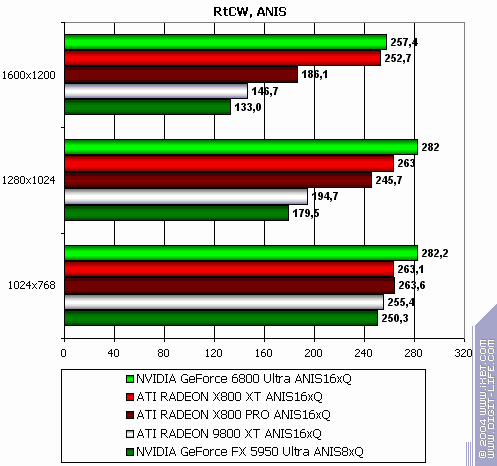 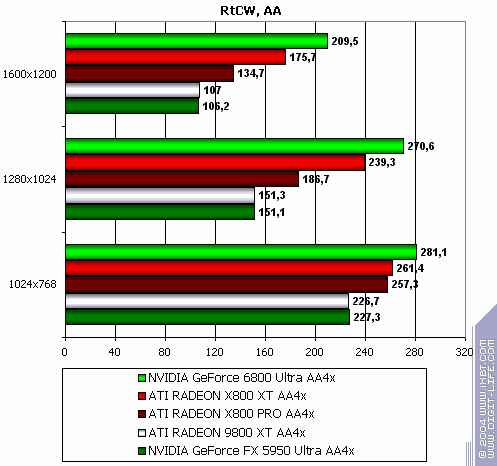 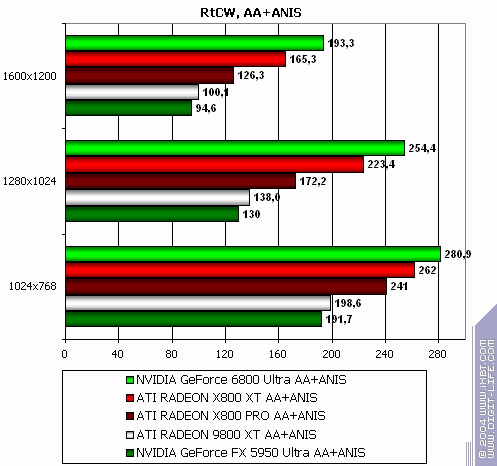 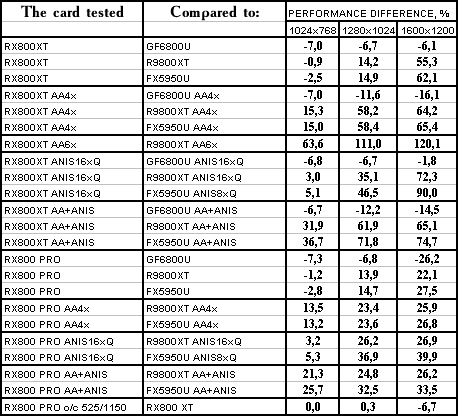
Code Creatures 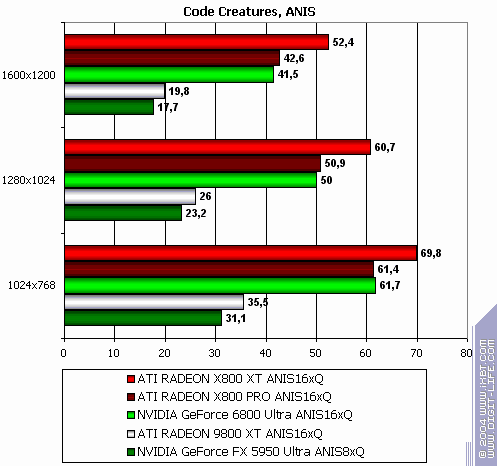 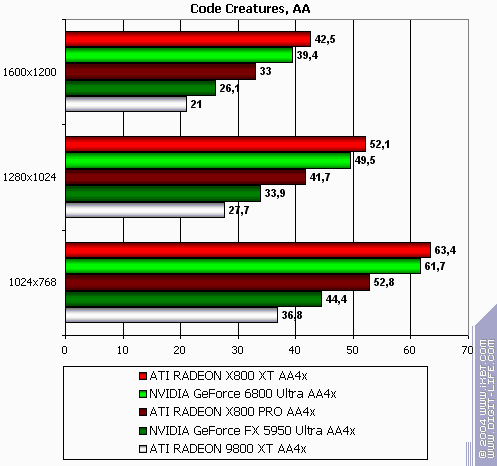 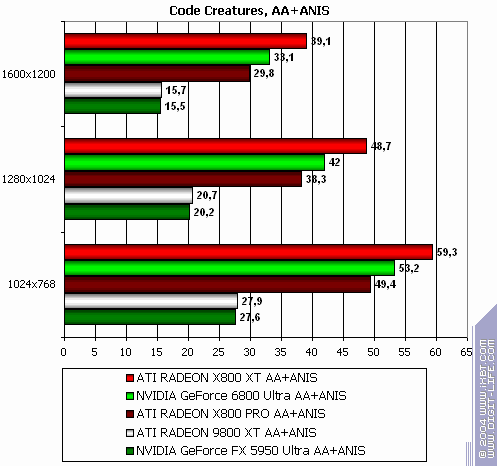 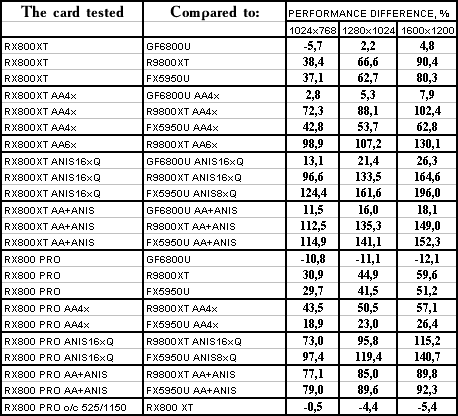
The lightest modes without AA and anisotropy: almost parity. AA enabled: ATI wins a little Anisotropy enabled: wins even more The hardest mode, AA + anisotropy: victory. Summary:
The modern and "shadery" the game is, the more chances there are that R420 will win.
Unreal Tournament 2003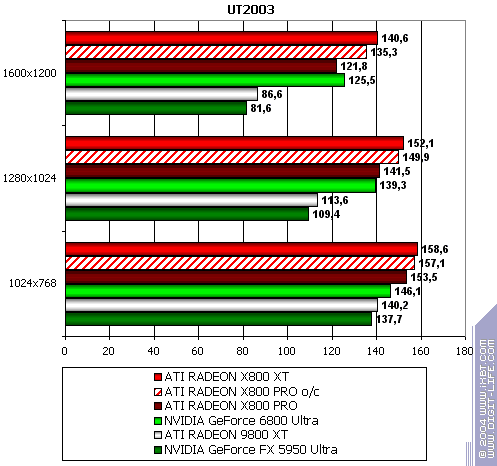 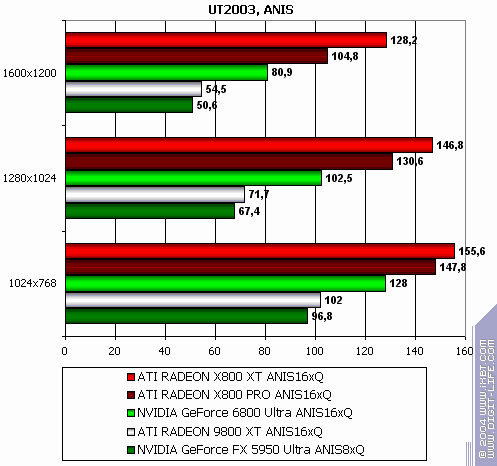  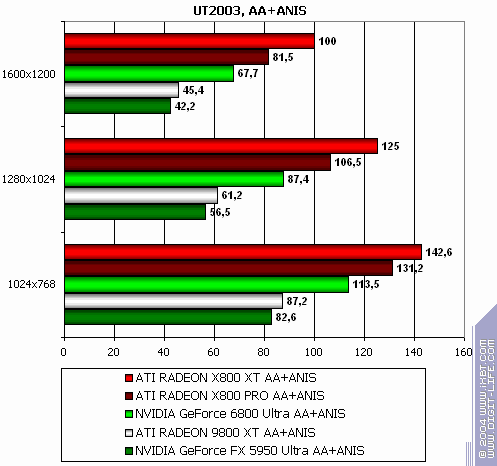 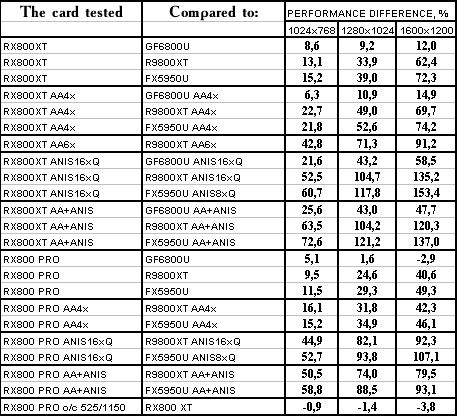
The lightest mode without AA and anisotropy: victory. AA enabled: victory. Anisotropy enabled: excellent. The hardest mode, AA + anisotropy: up to 47% win in 1600x1200! Summary:
Unreal II: The Awakening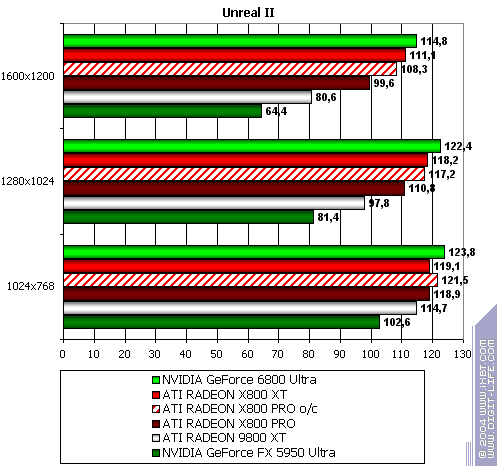 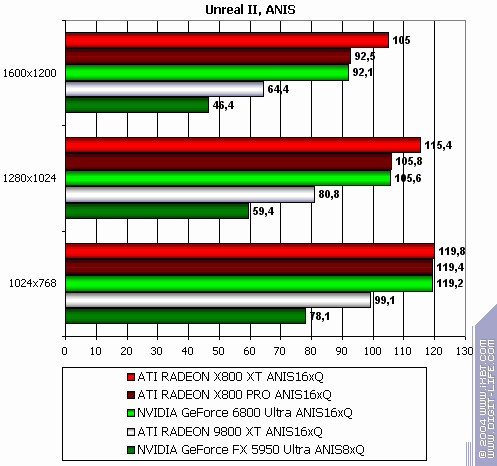  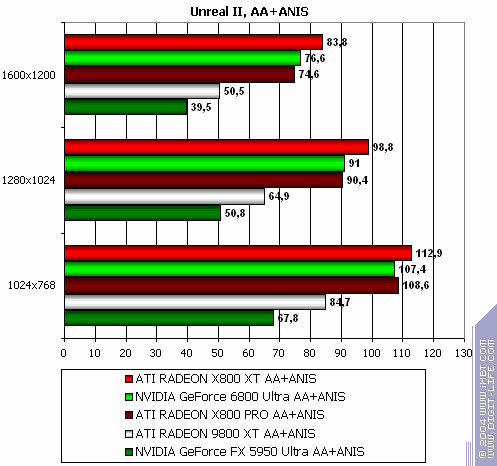 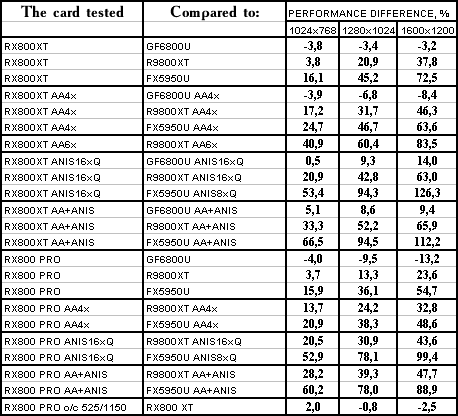
The lightest mode without AA and anisotropy: slight loss (it's interesting that all RADEONs have been winning this test before.) AA enabled: the same. Anisotropy enabled: and here X800 XT is victorious. The hardest mode, AA + anisotropy: general victory due to anisotropy. Summary:
RightMark 3D
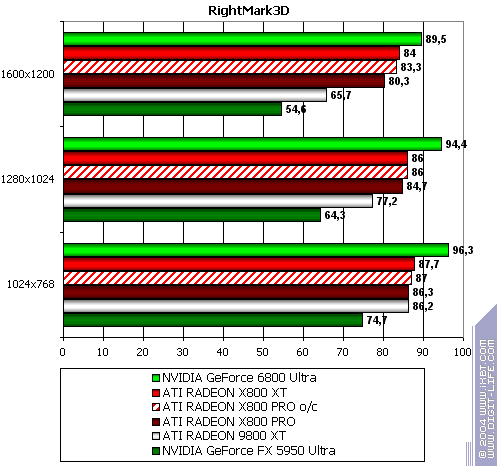  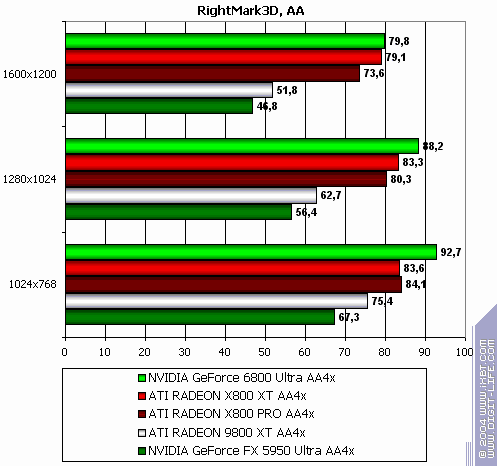 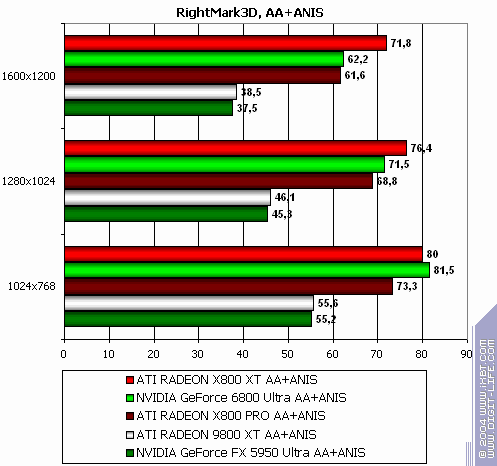 
The lightest mode without AA and anisotropy: loss AA enabled: the same Anisotropy enabled: almost parity in 1600x1200 The hardest mode, AA + anisotropy: victory. Summary:
Note this previously favourite RADEON test already demonstrates NVIDIA's advantages.
TR:AoD, Paris5_4 DEMO
 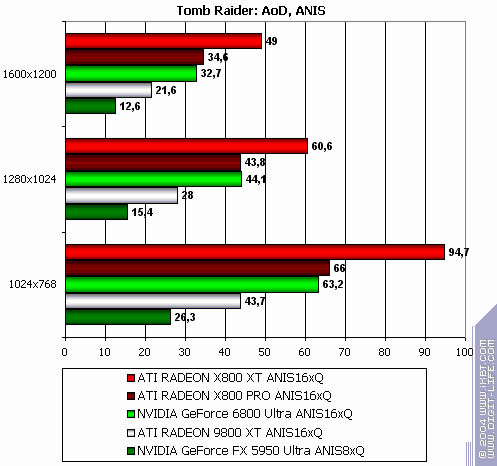 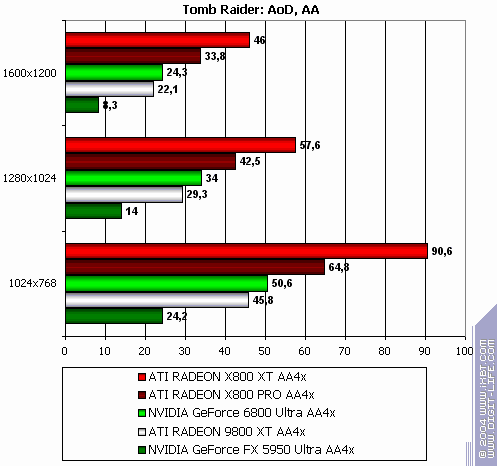 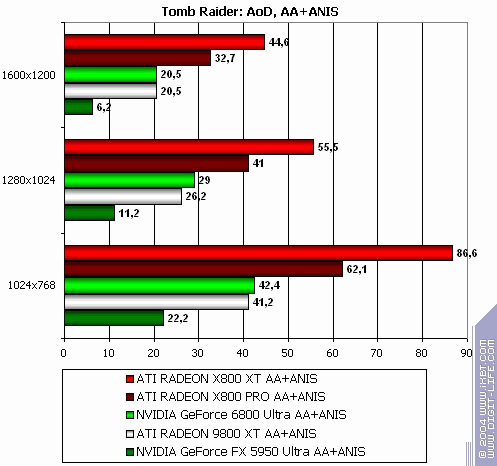 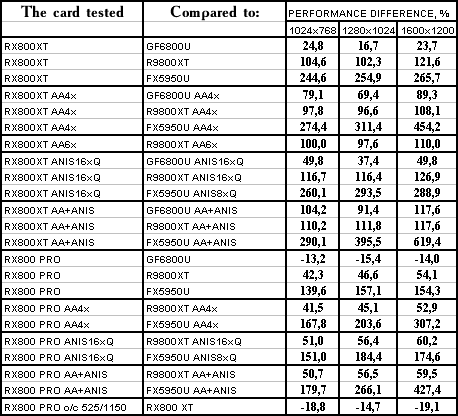
The lightest mode without AA and anisotropy: excellent results and flawless victory! AA enabled: 89% advantage! Anisotropy enabled: excellent as well! The hardest mode, AA + anisotropy: Point-blank. Double domination. :-) Summary:
As stated above, the more modern the test is...
FarCry, demo01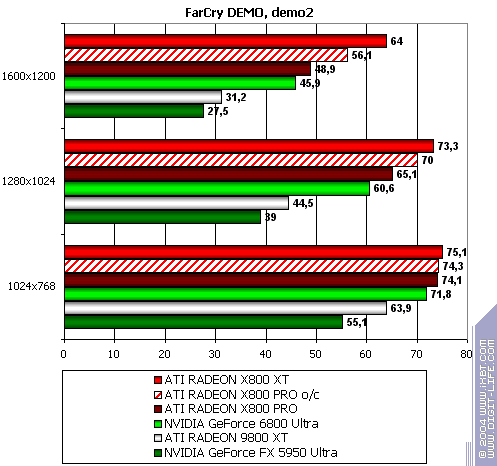   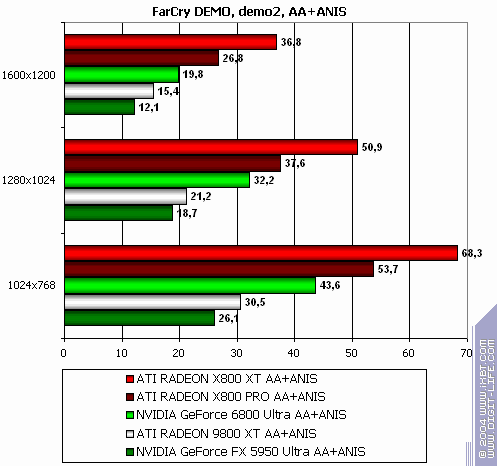 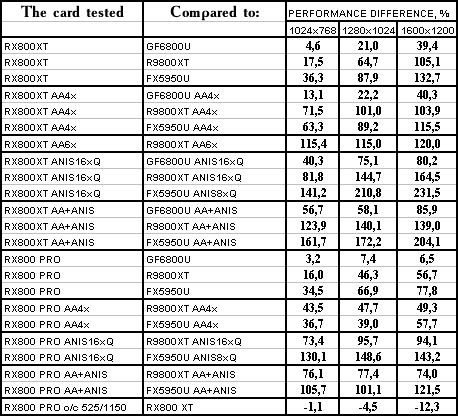
The lightest mode without AA and anisotropy: victory. AA enabled: victory! Anisotropy enabled: 80% advantage. The hardest mode, AA + anisotropy: up to 85% advantage. Summary:
Of course, there have been no performance-boosting patches for NV40 for this game or final drivers yet, so the situation may change. But will it be a turning point? The time will tell. NVIDIA still has very good reserves.
Call of Duty, ixbt04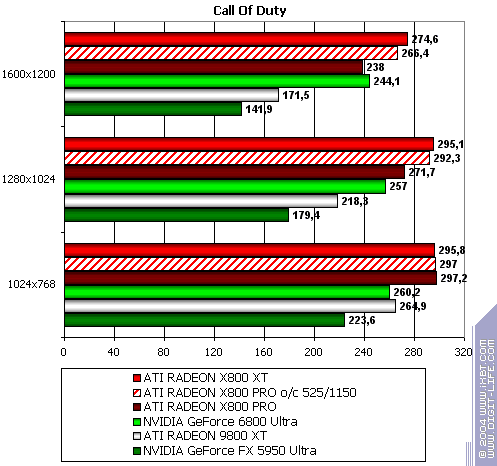 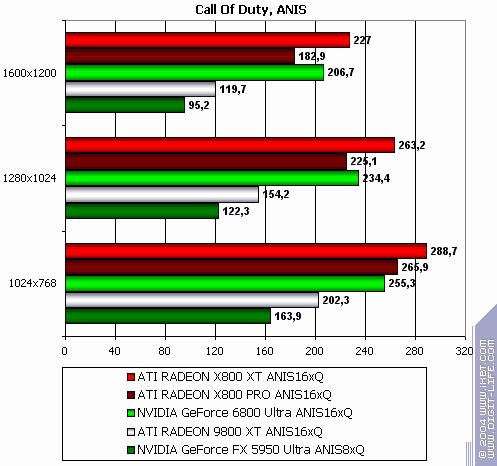 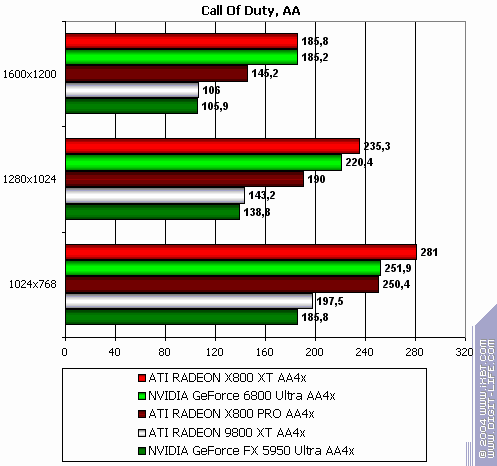 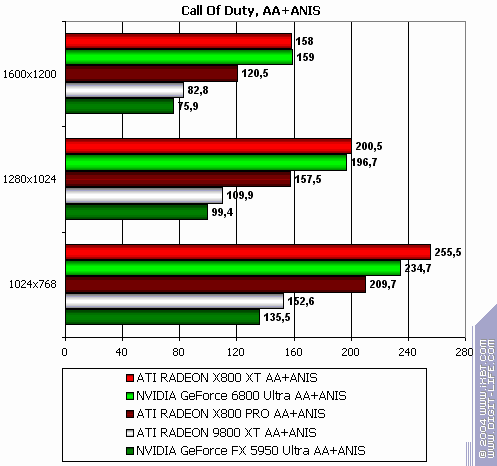 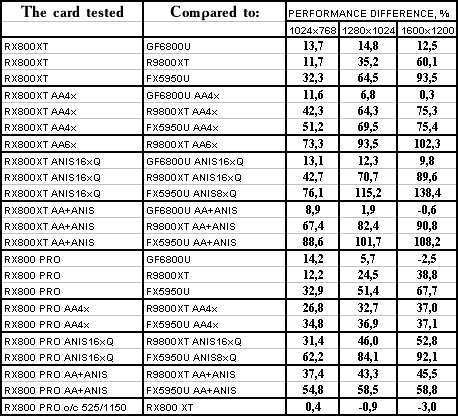
The lightest mode without AA and anisotropy: victory! Despite "OpenGL". :-) AA enabled: the same. Anisotropy enabled: the same! The hardest mode, AA + anisotropy: and the same (parity only in 1600x1200) Summary:
HALO: Combat Evolved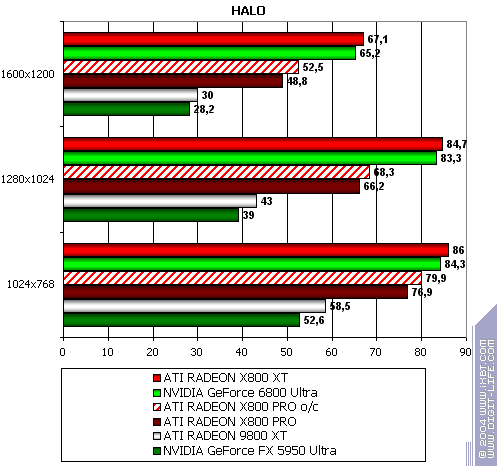  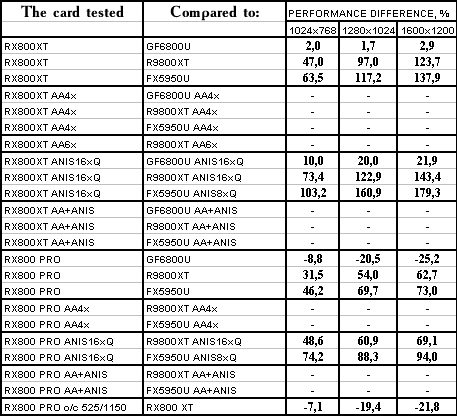
The lightest mode without AA and anisotropy: parity (due to CPU bottleneck). AA enabled: not supported ingame. Anisotropy enabled: good victory! Summary:
Half-Life2 (beta): ixbt07 demo
 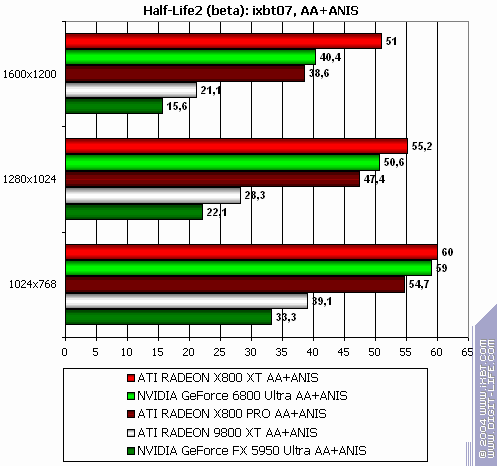 
Anisotropy enabled: almost parity with slight R420XT advantage. The hardest mode, AA + anisotropy: victory! Summary:
Splinter Cell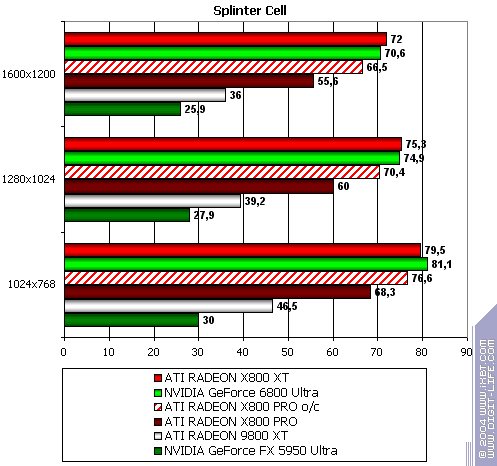  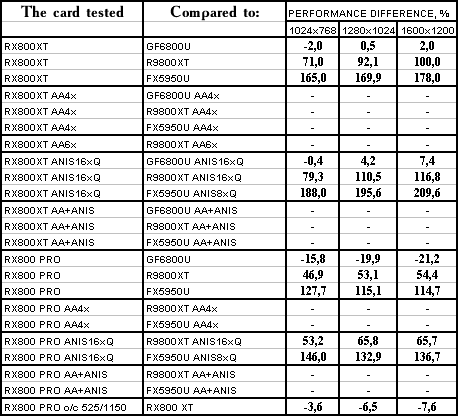
The lightest mode without AA and anisotropy: parity. AA enabled: not supported ingame. Anisotropy enabled: parity as well. Summary:
Conclusions:We tested the new R420 (in two products) in various tests, some of which are used by other testers, while some are already not. We proved that in old games both newest and previous-generation graphics cards rest on CPU as a main bottleneck. This should be considered by gamers who like old games, but also like newest hardware. In the next article we'll conduct a big test only in new games and benchmarks. Still there's enough of them in this article as well. So we can draw an objective conclusion regarding the 3D king if there's one. In the previous review of NV40 we asked for how long it would be the top. It's time for an answer:
So, if we don't consider NV40's support of shaders 3.0, R420 XT is a clear leader. But we must remember GeForce 6800 in serial production might have higher clock rates (but prices may be above). Besides, 61.11 drivers have already been released claimed to provide 5% to 20% performance boosts. Adding synthetic tests to games, we can see that R420 leads in pure performance, but loses in flexibility. Still this won't affect modern (and the near-future) games anyway. Again we'll mention R420 energy consumption that remained on the level of previous generation, while the GPU became twice and even more powerful. It seems R420 yield may be higher than that of NV40 affecting dates of R420's actual arrival to stores (despite the later announcement) and price reduction dynamics. There's certain industry where NVIDIA's NV40 would be considerably more beneficial - DCC. Shaders 3.0 and excellent OpenGL may very positively affect the promotion of Quadro 4000 (on NV40GL). ATI has considerably less to be proud of in this field. We are looking forward to junior models based on NV40/R420 innovations. What a battle it will be! More comparatives and charts of both graphics cards will be provided in our
3Digest. 
Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||