 |
||
|
||
| ||
|
||
|
||
| ||
We've been waiting for it.
And finally, here is the new architecture: a correction of past mistakes and a solid foundation for the future. But is it really so? We are going to probe into both aspects.  CONTENTS
The article is mainly devoted to issues of architecture and synthetic limiting tests. In a while, an article on performance and quality of game applications will appear, and then, after a new ATI architecture has been announced, we'll conduct and publish a detailed comparative research of quality and speed issues of AA and anisotropic filtering in the new-generation accelerators. Before reading this article make sure you have thoroughly studied DX Current and DX Next, materials on various aspects of today's hardware graphic accelerators, and on architectural features of NVIDIA and ATI products, in particular. GeForce 6800 official specs
GeForce 6800 Ultra reference card specs
General scheme of the chip At the current detalisation level, no significant architectural differences from the previous generation are seen. And it is no surprise, as the scheme has survived several generations and is optimal in many aspects. We would like to note that there are six vertex processors and four separate pixel processors each working with one quad (a 2x2 pixel fragment). Also noteworthy are two levels of these textures' caching (a general cache and a personal cache for each group of 4 TMUs in the pixel processor), and, as a result, the new ratio of 16 TMUs per 16 pixels. And now we'll increase detalisation in the most interesting places: Vertex processors and data selectionAn interesting innovation has been introduced: a support of various scalers for the flows of the vertices' source data. Let us remind you how data are generally selected for the vertices in modern accelerators:  The structure consists of several predefined parameteres: scalars and vectors up to 4D, floating-point or integer formats, including such special data types as vertex coordinates or normal vector, colour value, texture coordinates, etc. Interestingly, they can only be called "special" from the point of view of API, as hardware itself allows an optional parameter commutation in the microcode of the vertex shader. But the programmer needs to specify the source registers of the vertex processor, where these data will be after selection, in order not to make redundant data moves in the shader. Vertex data stored in the memory must not necessarily be a single fragment, they can be divided into a number of flows (up to 16 in NV40) each having one or several parameters. Some of the flows may be in the AGP address range (that is, will be selected from the system memory), other may be placed in the local memory of the accelerator. Such approach allows to use twice the same data sets for different objects. For instance, we can separate geometrical and textural information into different flows, and having one geometrical model use different sets of textural coordinates and other surface parameters, thus ensuring an external difference. Besides, we can use a separate flow only for the parameters that have really changed. Others can be loaded just once into the local memory of the accelerator. A current index, single for all flows, is used to access the parameters of this or that vertex. This index either changes in a chaotic way (source data are represented as an index buffer) or gradually increases (separate triangles, stripes and fans). What is new about the vertex data selection in NV40 is that it's not necessary for all the flows to have the same number of data sets. Each flow can have its own index value divider (a so-called Frequency Stream Divider). Thus, we avoid data duplication in some cases and save some size and bandwidth of the local memory and the system memory addressed through AGP:  Apart from that, the flow can now be represented as a buffer smaller in size than the maximal index value (even including the divider), and the index will just turn round the flow's buffer border. This novelty can be applied for many operations, for instance, to compress geometry using hierarchic representations or to copy features onto the array of objects (information common for each tree in the forest is only stored once, etc.). And now take a look at the schematic of the NV40 vertex processor:  The processor itself is represented as a yellow bar, and the blocks surrounding it are only shown to make the picture more complete. NV40 is announced to have six independent processors (multiply the yellow bar by six) each executing its own instructions and having its own control logic. That is, separate processors can simultaneously execute different condition branches on different vertices. Per one clock, an NV40 vertex processor is able to execute one vector operation (up to four FP32 components), one scalar FP32 operation, and make one access to the texture. It supports integer and float-point texture formats and mipmapping. Up to four different textures can be used in one vertex shader, but there's no filtering as only the simplest access (a discrete one) to the nearest value by specified coordinates is possible. This enabled a considerable simplification of the TMU and consequently, of the whole vertex processor (the simpler the TMU - the shorter the pipeline - the fewer transistors). In case of urgency, you can execute filtering in the shader yourself. But of course, it will require several texture value selections and further calculations, and as a result, it will take many more clocks. There are no rigid restrictions as to the length of the shader's microcord: it is selected from the local memory of the accelerator during execution. But some specific APIs (namely, DX) may impose such restrictions. Given below is a summary table of the NV40 vertex processor's parameters concerning DX9 vertex shaders, compared to families R3XX and NV3X:
In fact, if we look back on the NV3X architecture, it becomes clear that NVIDIA developers only had to increase the number of temporary registers and add a TMU module. Well, now we are going to see synthetic test results and find out how close NV40 and NV3X architectures are in terms of performance. And another interesting aspect we will dwell on is performance of the FFP emulation (of the fixed T&L). We would like to know if NV40 hardware still has the special units that gave NV3X such a visible increase on the FFP geometry. Pixel processors and filling organisationLet's examine the NV40 pixel architecture in the order of data sequence. So, this is what comes after the triangle parameters are set:  Now we are going to touch upon the most interesting facts. First, in contrast to earlier NV3Xs that only had one quad processor taking a block of four pixels (2x2) per clock, we now have four such processors. They are absolutely independent of one another, and each of them can be excluded from work (for instance, to create a lighter chip version with three processors in case of them has a defect). Then, each processor still has its own quad round queue (see DX Curent). Consequently, they also execute pixel shaders similarly to the way it's done in NV3X: more than a hundred quads are run through one setting (operation) followed by a setting change according to the shader code. But there are major differences too. First of all, it concerns the number of TMUs: now we only have one TMU per each quad pixel. And as we have 4 quad processors with 4 TMUs in each, it makes the total of 16 TMUs. The new TMUs support anisotropic filtering with the maximal ratio of 16:1 (the so-called 16x, against 8x in NV3X). And they are they first to be able to execute all kinds of filtering with floating-point texture formats. Although, providing the components have a 16-bit precision (FP16). As for FP32, filtering still remains impossible. But the fact that the FP16 level has been reached is already visible progress. From now on, floating-point textures will be a viable alternative to integer ones in any applications. Especially as FP16 textures are filtered with no speed degradation. (However, an increased data flow may and probably will impact on performance of real applications.) Also noteworthy is a two-level texture caching: each quad processor has its own first-level texture cache. It is necessary to have one for two following reasons: the number of quads processed simultaneously has increased fourfold (quad queues haven't become longer, but the number of processors has risen to four), and there is another access to the texture cache from vertex processors. A pixel has two ALUs each capable of executing two different operations on different numbers of randomly selected vector components (up to four). Thus, the following schemes are possible: 4, 1+1, 2+1, 3+1 (as in R3XX), and also the new 2+2 configuration, not possible before (see article DX Current for details). Optional masking and post-operational component replacements are supported too. Besides, ALUs can normalise a vector in one operation, which can have a considerable influence on performance of some algorithms. Hardware calculation of SIN and COS values was extracted from the new NVIDIA architecture: it was proved that transistors used for these operations were spent in vain. All the same, better results in terms of speed can be achieved when accessing by an elementary table (1D texture), especailly considering that ATI doesn't support the mentioned operations. Thus, depending on the code, from one to four different FP32 operations on scalars and vectors can be made per clock. As you can see in the schematic, the first ALU is used for service operations during texture value selection. So, within one clock we can either select one texture value and use the second ALU for one or two operations, or to use both ALUs if we're not selecting any texture. Performance is directly related to the compiler and the code, but we definitely have the following variants: Minimum: one texture selection per clock According to certain information, the number of temporary registers for quad has been doubled, so now we have four temporary FP32 registers per pixel or eight temporary FP16 registers. This fact must incerase dramatically performance of complex shaders. Moreover, all hardware restrictions as to the pixel shaders' size and the number of texture selections have been removed, and now everything depends on API only. The most important modification is that execution can now be controlled dynamically. Later, when the new SDK and the next DirectX 9 (9.0c) version appear, we'll conduct a thorough study of realisation and performance of pixel shaders 3.0 and dynamic branches. And now take a look at a summary table of capabilities:
Evidently, the soon-to-be-announced ATI (R420) architecture will support the 2.b profile present in the shader compiler. Not willing to make hasty conclusions, we'll say however, that NV40's flexibility and programming capabilities are beyond comparison. And now let's go back to our schematic and look at its lower part. It contains a unit responsible for comparison and modification of colour values, transparency, depth, and stencil buffer. All in all, we have 16 such units. Considering the fact that comparison and modification task is executed quite similarly in every case, we can use this unit in two following modes. Standard mode (executes per one clock):
Turbo mode (executes per one clock):
Certainly, the latter mode is only possible if there's no calculated and writable colour value. That is why the specs say that in case there's no colour, the chip can fill 32 pixels per clock, estimating the values of depth and stencil buffer. Such turbo mode is mainly useful for a quicker shadow building basing on the stencil buffer (the algorithm from Doom III) and for a preliminary rendering pass that only estimates the Z buffer. (Such technique often allows to save time on long shaders as overlap factor will be reduced to one). Luckily, the NV3X family now supports MRT (Multiple Render Targets - rendering into several buffers), that is, up to four different colour values can be calculated and written in one pixel shader and then placed into different buffers (of the same size). The fact that NV3X had no such function used to play into the hands of R3XX, but now NV40 has turned the tables. It is also different from the previous generations in an intensive support of floating-point arithmetics. All comparison, blending and colour-writing operations can now be made in the FP16 format. So we finally have a full (orthogonal) support of operations with a 16-bit floating point both for texture filtering and selection and stencil buffer handling. Well, FP32 is next, but that will be an issue for the future generation. Another interesting fact is the MSAA support. Like its NV 2X and NV 3X predecessors, NV40 can execute 2x MSAA with no speed degradation (two depth values per pixel are generated and compared), and it takes one penalty clock to execute 4x MSAA. (In practice, however, there's no need to calculate all four values within one clock, as a limited memory bandwidth will make it difficult to write so much information per clock into the depth and frame buffers). More than 4x MSAA are not supported, and like in the previous family, all more complex modes are hybrids of 4x MSAA and the following SSAA of this or that size. But at least it supports RGMS: 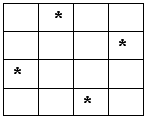 And that can visibly increase the smoothing quality of slanting lines. At this point we finish our description of the NV40 pixel processor and proceed to the next chapter. 2D and the GPUThis is the separate programmed NV40 unit that is charged with processing video flows:  The processor contains four functional units (integer ALU, vector integer ALU with 16 components, data loading and unloading unit, and a unit controlling jumps and conditions) and thus can execute up to four different operations per clock. The data format is integers of 16-bit or 32-bit precision (it is not known more exactly which, but 8 bits wouldn't be enough for some algorithms). For more convenience, the processor includes special possibilities of data flow selection, commutation, and writing. Such classical tasks as video decoding and coding (IDCT, deinterlacing, colour model transformations, etc.) can be executed without the CPU. But still, a certain amount of CPU control is required: it is the CPU that has to prepare data and transform parameters, especially in complex algorithms of compression that include unpacking as one of the interim steps. Such processor can relieve the CPU of many operations, especially in the case of hi-res videos, such as increasingly popular HDTV formats. Unfortunately, it is not known if the processor's capabilities are used for 2D graphic acceleration, especially for some really complex GDI+ functions. But anyway, NV40 meets the requirements for hardware 2D acceleration: all necessary computive intensive GDI and GDI+ functions are executed hardwarily. OpenGL extensions and D3D featuresHere's the list of extensions supported by OpenGL (Drivers 60.72):
D3D parameters can be ssen here: D3D RightMark: NV40, NV38, R360 Attention! Be advised that the current DirectX version with the current NVIDIA (60.72) drivers does not yet support the capabilities of pixel and vertex shaders 3.0. Perhaps the release of DirectX 9.0c will solve the problem, or perhaps, the current DirectX will be suitable, but only after programs are recompiled using new SDK version libraries. This recompilation will be available soon.
[ Next part (2) ]
Alexander Medvedev (unclesam@ixbt.com)
Kirill Budankov (budankov@ixbt.com) 27.04.2004
Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. |














