 |
||
|
||
| ||
|
||
|
||
| ||

Warning: The article deals with new technologies (either developing or developed but not yet announced) and hence, is mostly based on unofficial information. The general picture is compiled from various more or less official sources (such as ATI and NVIDIA published presentations in GDC for developers), as well as from Internet media rumours. It should be borne in mind that any ATI or NVIDIA information on the coming version of API DirectX is not ultimate as it is still being developed. Thus, any parameters can be changed, even in the last days before the release.
So read the article at your own risk, here and now, and any coincidence with future events is to be regarded as just a lucky accident. Although, "luck favours the most prepared ones", as they say, and I tried to compile this article basing on the most reasonable and trustworthy bits of information.
It's only the beginningIt is known that new-generation products are about to be announced. ATI and NVIDIA officials repeatedly stated that, vaguely hinting at possible deadlines. Some sites, such as Anandtech, even publish rumours about concrete names and dates:
Well, time will show if these rumours have any grounds. And now we're going straight to the article issues.
Bus issueTo begin with, let us speak about graphic platforms' rapid transition to a new bus, named PCI Express (further referred to as PCX). This is about what we'll see in the next generation of NVIDIA and ATI graphic chips. ATI have come up with two chip versions, R420 and R423. The former supports the AGP 8x bus, the latter supports PCX (word has it that this version will be announced somewhat later than early summer). There are no other fundamental differencies between them. As we have previously mentioned, the first generation of desktop PCX will have one slot for graphics (16x) and a number of peripheral slots (1x). The 16x PCX slot's throughput is 4 GBps for each of the two simultaneous directions (the so-called "full duplex"). The AGP 8x throughput is 2.1 GBps for the system-to-accelerator path, and much lower (~200 MB) for the opposite direction.
NVIDIA counts on a separate chip (bridge) that makes a PCX->AGP transformation. This bridge can be used with both future chips and the current NV3X series. But it's not so simple as that — we find out that the throughput of such scheme (AGP chip + PCX bridge) is not limited by values typical of AGP 8x. How can that be? Here's the scheme:
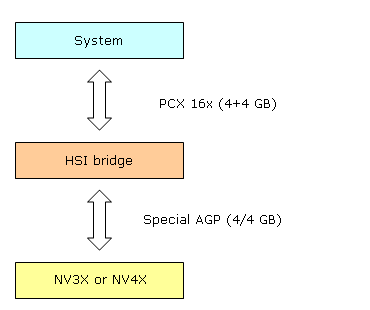 First comes the system, then the 16x PCX slot, and the chip of the HSI (High Speed Interconnect) bridge. The chip connects to either a graphic NV3X chip or a future-generation chip via its standard AGP pins. But in case the graphic chip works with the HSI bridge allocated at a minimal distance from it, we can reach a twofold increase of the speed at which the graphic chip's AGP 8x bus interface functions. Thus, we get a throughput analog of a virtual AGP 16x bus, and the throughput rises to 4GBps. But that's not all — in contrast to a typical AGP-standard system capable of only one-way maximum data-transmission speed, the modified AGP interface between the HSI bridge and an NVIDIA accelerator transmits data at 4 GBps both ways. But the transmission is not simultaneous: at any moment of time, data will only be sent one way, with a peak speed of 4 GBps. And besides, it takes some time to switch the status from data transmission to data reception. Interestingly, the bridge chip works two ways: if placed the other way round, it can serve as a bridge for creating AGP 8x cards based on PCX chips. These are the chips that NVIDIA plans to start producing in a while (some rumours say it will be no sooner than in a year). Here are the theoretical drawbacks of the solution:
On the other hand, practical advantages are evident. The approach enables NVIDIA not to put into production two accelerator versions (a rather expensive process). Besides, the company can execute a flexible regulation of PCX-AGP cards ratio, basing on a particular market situation. A possible loss in performance is not so important, in our opinion — at least for the current API (DX9) version and the NV4X generation. API and most applications are made (and will be made for at least another two years) considering AGP features and a maximum-density data arrangement in the local memory of the accelerator. So, the main problem for NVIDIA is the card's complexity resulting from an additional bridge chip and hence, additional responsibility for card manufacturers. ATI's prime concern is delivery (a potential deficit or overproduction of PCX or AGP versions). Only time can tell whose approach is more suitable.
Issue of 3.x shadersConcerning the coming generation of NVIDIA products, the future seems quite predictable to us. NVIDIA materials for developers and the latest GDC clearly gave us to understand that new NVIDIA products would provide a hardware support for vertex and pixel shaders 3.0. Let us begin with vertex shaders. According to the actual standard, version 3.0 needs the option to select texture values from both pixel and vertex shaders. This option shouldn't be underestimated. It can be applied for a lot of techniques, from DM (Displacement Mapping) on the vertex level to various distortion degrees or even generation of new geometry (though, only with a known number of vertices for now). It is undisputably convenient. But what about its practical realisation? The two main questions that arise here are: will filtration of texture values be supported at selection, and what texture formats will be possible to use (in particular, will the floating-point format be supported). There's nothing definite we can say about it at the moment, but evidently, the current approach to the pixel pipeline architecture almost totally excludes the use of the same TMUs for both pixel and vertex pipelines. A more probable situation is that next-generation accelerators will use separate TMUs for vertex processors. As a result, the TMUs will have a somewhat narrower functionality (for instance, filtration may be cut out). But as soon as new products are officially announced, we'll study this aspect in details. Another important feature of both vertex and pixel shaders 3.0 is a dynamic control of instruction execution, that is, real dynamic conditions and branchings like in CPUs. While everything is quite clear with vertex shaders (NV3X chips enabled to use dynamic branchings as early as in shaders 2.x and certainly in OpenGL), practical realisation of pixel shaders is a much more complicated thing. First comes the performance issue. If you have read the DX Current article you probably remember the scheme of a pixel 3X pipeline and its detailed analysis we made. If you don't, then you'd better brush up this aspect of NV3X architecture. So, to remind you, pixels in pixel pipelines are processed in fours (in quads). And there are various possible solutions concerning dynamic jumps and conditions in this case:
The second and the third approaches are more probable (also possible to use both in various proportions, depending on the shader code). While the first one will surely require too much of transistor resources, as it is too early to give up quads. Especially considering the fact that truly dynamic shader branchings won't be frequent in real applications, and will be even more rare as long as this generation of accelerators holds leading positions. The most probable compromising solution seems to be like this: fast shaders 2.0, quite fast shaders 3.0 with insignificant branchings, rather slow shaders 3.0 with intensive dynamic jumps and branchings (but with no flexibility restrictions). This solution seems optimal for the future generation, while the approach to the next architectures (R5XX è NV5X) may and must be somewhat different, but we'll speak about it later. The tendency is only natural: sacrifice performance for flexibility. The more we digress from a specific similarity of graphic algorithms (one-type interchangeable primitive sets and one-typr operations with them), the less profit we get from massively parallel solutions, so widely realised in different accelerator units. Moreover, digression from similarity of data and instructions results in an increasingly chaotic access to initial memory data, which, in turn, makes caching far less effective (remember small caches in graphic processors). However, it is not at all so gloomy. The second approach allows for certain optimizations: for instance, if all pixels of the quad belong to one condition branch, there is no need to put them through instructions of another branch. This condition will be observed in many algorithms, and neighbouring pixels have every chance to get the same condition values, and thus, performance decrease will be significantly hampered. On the other hand, storing predicates and condition parameters requires temporary registers for each quad pixel, and evidently, it will take bits from temporary general-purpose registers. Thus, if branchings are too complex, we get a yet another performance-decreasing factor. Anyway, as soon as new products appear, we'll study thouroughly all performance aspects of shaders 3.0 and try to make certain conclusions about their realisation. According to some wide-spread Internet rumours, pixel processors of next-generation ATI accelerators (R420 and its architecture-based variants) won't support dynamic branchings in pixel shaders. Only static conditions, cycles and branchings (that is, specified by the vertex shader)will be accessible, and their use will still decrease performance substantially. It is unclear whether there are enough static branchings to declare pixel shaders 3.0-corresponding. It all depends on the Microsoft company that can either introduce a new profile for 2.x shaders (say, 2.B, using the 2.X pattern), or set mild requirements for a product to be admitted compatible with pixel shaders 3.0. All these innovations will appear in DirectX 9.0c, expected to be released soon after new ATI and NVIDIA announcements. Another possible compromising solution for ATI is the variant where vertex processors will have a support for hardware execution of shaders 3.0, while pixel processors — only an extended version of shaders 2.0 (2.B or 2.X). In principle, there are no hindrances to that, but the current DX SDK version doesn't support such option. But we are happy with another aspect: that pixel calculation precision in R420 has reached the standard 32 bits. So, NVIDIA will support shaders 3.0 wherever possible, whereas ATI strategy is absolutely unpredictable: they can come up with support of anything from base 2.x shaders in vertex and pixel processors, a tandem of more advanced vertex ones and compromising pixel ones, to 3.0 in both, perhaps with substantial restrictions on shader length or without dynamic jumps in pixel shaders. It can be said the the situation repeats that with pixel shaders 1.4, when one manufacturer supported the innovation and the other one ignored it. As a result, many application developers chose 1.1. Now the situation is more copmplicated and there can be several possible developments. But anyway, absence of standard pixel shaders 3.0 may diminish ATI cards' popularity with developers and rethrone NVIDIA. Whereas real applications developed on NV4X will only come out by the time next-generation architectures appear (in 18 months or more). But because those architectures will be made for shaders 4.0, they'll obviously execute any 3.0 code without restrictions. As for standard games, in the coming two years they'll have pixel shaders as an additional option at best (we must say, an option not obligatory and not liked very much). But that, in fact, does not minimize their importance for DCC applications and various systems of realistic graphics. To sum up the prognosed situation:
Soon, as the cards are announced, we'll put into practice all the suppositions. Other DX9 features to expect in the next GPU generationFor now we can only guess about new anisotropy and AA algorithms we might see in the new GPU generation. Still some other features are already forecastable on the base of GDC presentations. NVIDIA's new architecture will finally obtain the long-anticipated MRT feature allowing writing several color values from a single pixel shader to different buffers. Besides, they mention good support of floating-point frame buffer (both write and blending.) Thus exactly this generation will enable us to speak of the fully-fledged floating-point color values in both calculations, and frame buffer. We are also likely to see some new floating-point texture features in pixel shaders, e.g. bilinear filtering. It's not clear how ATI is going to implement these, but, most likely, floating-point frame buffer blending will be realized anyway. Besides, it will already be the second GPU generation with gamma correction in pixel calculations. It's not long before other details follow, and we'll sadly state that the first innovative generation is always spoiled before it spins. And only the second floating-point pixel architectures will finally provide us with a more or less smooth (orthogonal) FP features image projected from products of both market leaders. DX Next, the matter of time and placeWe don't know the official name of the next DirectX version, so we'll call it "DX Next" (don't consider it an official name, I repeat, we don't know it yet.) But we can point to its approximate release date - the early 2006. Yes, the good old DirectX 9 will have been living for a long time, that's why it already features the ahead-of-time Shaders 3.0 support. Early in 2006 we should also see Longhorn OS, seemingly the most revolutionary and innovative since Windows NT 4. In many respects these innovations are required by the new concept of device support, including graphics cards. Therefore the release of the next DX version is a part and parcel of the new OS core, so we might not even see this API on the previous operating systems (XP, 2000 and older.) Why? Let's discuss it in detail below. Virtual memory and software-hardware interfaceToday the location of data, be it card's memory or RAM, and method of its update generally depends on the programmer. You can offload it to DX, but it often knows nothing on data usage (often or rare updates and rewrites), so programmers provide various flags defining the location of vertex buffers, textures, etc. However the paradox is that programmers themselves can't always determine an optimal location for the above. Especially considering that local memory varies from card to card and resource popularity changes from level to level and is even more variable in every single frame, while some game settings might radically change the picture in general. It's not wise to confide in man in such situations, but to avoid this we'll need well thought-out continuous data loading and performance (resource access frequency) monitoring algorithms. Looks familiar? Right you are, it's virtual memory based on paging considering access frequency. It's a widely known CPU technology. 3dlabs already tried to create a hardware supported virtual memory mechanism that would have its local memory and PC RAM unified into a single whole from the angle of accelerator internals (outside memory controller.) But this effort couldn't be considered complete, as a really transparent mechanism will require not only API DirectX (or OpenGL, realized by at least one vendor) support, but also OS support, yet unavailable. So, the new OS codenamed Longhorn will offer all necessary mechanisms, while DX Next will be primarily designed for this new approach to resource management. DX Next GPUs (most likely, R5XX, NV5X, etc.) will support hardware data paging into local memory from RAM and hardware data offload to RAM that will base on independent (background) data usage analysis:
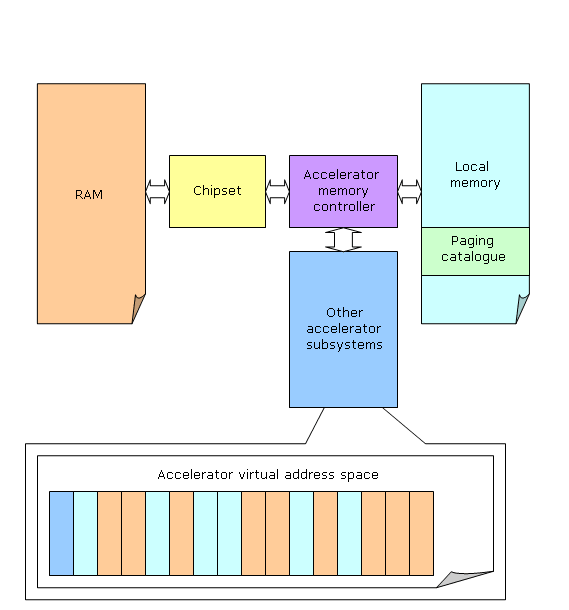 As a result, from the shaders' angle, applications and in many respects APIs will have data located in a single linear virtual address space, and their physical location will be determined by GPU hardware considering data usage statistics. To do this, they will likely use classical approach to page catalogue familiar from CPUs. Of course, there are some nuances. E.g. freeing memory won't require offloading data unchanged since loading. Besides, some data types, like Z-buffer, will be tied to card's local memory. It would be irrational to drive Z-buffer data to RAM and back again, as it's too expensive for acceptable fill rate. It's clear that many data types, like textures, are better stored as tiles or either size that meets optimal paging granularity. According to some information, minimal page (1st level page) size will be equal to a typical OS page size of 4KB. Another problem of modern APIs that also has to be solved is the low performance of state changing (texture mapping, shaders and their parameters switching, and, in particular, active frame buffer update). Developers make new hardware-API interfaces that get closer to modern reality and accelerate creation and selection of new DirectX objects, in particular, shaders, textures and active frame buffers. The policy is simple: to preprocess everything preprocessable to offload frame building. New API priority is a considerable increase in small triangle array processing performance that is the worst bottleneck of modern accelerators often preventing programmers from expanding their fantasy and simultaneously realizing lots of various effects in a single scene without at least noticeable performance falloffs. Everything offloadable from CPU to GPU is to be offloaded, including initial texture and geometry buffers processing. They should also optimize and pipe small primitive array processing. Such innovations should shift many optimization accents in future applications and, perhaps, make other imaging approaches more beneficial. Only the time will tell! All this is to bring new opportunities to programmers, but you must understand that DX Next applications are not a matter of the nearest future. We can hope that in some three years the first games balanced by the new API will reach official stores and pirate shacks :). The most important issue of Shaders 4.0, primitive generation and random accessThe key power of DX Next is Shaders 4.0 and everything architectural related. It's interesting that in many respects today the vision of this coincides with my year-ago thoughts. Still, it's pretty logical and graphics evolution ways do not introduce any global surprises. So, here's what should (is likely) to happen to this industry:
So, let's describe the above in more detail. A typical accelerator will turn into an array of identical vector processors of a rather general purpose that will support both floating-point and integer formats, branching, new data generation, and either random access methods. Of course, these processors will still have lots of specific units (texture prefetch and filtering, parameter interpolator, various HSR optimizators for primitives screening before processing, etc.). But they'll be much more universal. Perhaps, these processors will still be organized as quads, but each quad will be capable of processing not only pixel, but also other (geometry) data. At such high level of shader unification (unified architecture) there's no fundamental difference. Moreover, unification will allow creating rather complex chains for data streams processing:
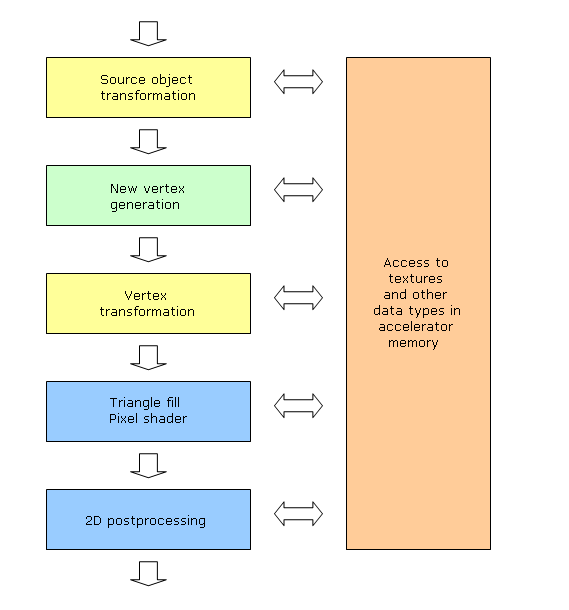 The amount of shaders in such a chain can be rather high, each belonging to the above type. So data structures buffered in-between will have flexible formats. Actually DX Next will significantly limit this scheme, but at least it will provide the following:
At that items 0, 4, and 6 will be realized by non-programmable hardware blocks, while all other - by standard shader processor. Of course, other APIs (like OpenGL) might have other configurations, perhaps, more flexible or branched. It's just a matter of logical representation of a very flexible hardware structure featuring a switched processor array. Such architecture will finally solve the problem of erratic shader subsystems load. You will be able to dynamically (and even automatically!) redistribute resources by hardware means. This will have granularity of up to a single object (vertex or pixel), so accelerator processors are always 100% loaded (of course, if no special hardware units are bottlenecks). This approach will again make it simpler for programmers wasting much time in search for bottlenecks. It's interesting that from the angle of programmer, such accelerator configuration can be scribed as a shader set with specified inputs and outputs. Everything else will be done by compiler and API. All this heavenly flexibility invokes lots of hardware realization issues. Random memory access requires significantly larger caches. Lots of shaders require significantly larger intermediate buffers and instruction cache. Textures accessible by all processors will require latency issue to be solved (we'll still be able to use the "one instruction over many primitives" method, though efficiency will drop due to branching and random memory access.) So, there are problems to be solved all around. But we don't doubt they are all solvable in DX Next in 2006. There's another interesting thing: CPU and GPU are irreversibly converging. CPU's SIMD and MIMD (i.e. VLIW) features, HT and multi-core chips, and GPU's random memory access and still more common instruction sets and data types. These are bound to collide some time. Will it happen in ten years? I guess more likely in 7-8. Anyway, only the time will tell! I like this industry because I can always say, "We'll see." Everything develops in such a pace, so sometimes we, high-tech specialists, seem to grow old slower than other people :)
Alexander Medvedev (unclesam@ixbt.com)
Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. |














