 |
||
|
||
| ||
|
||
|
||
| ||
 As usual, before we proceed to analysis of the new accelerator we recommend that you read the analytic article scrutinizing the architecture and specifications of the NVIDIA GeForce FX (NV30) CONTENTS
3D graphics, 3DMark2001 SE synthetic testsAll measurements in 3D are carried out at 32bit color depth. Fillrate
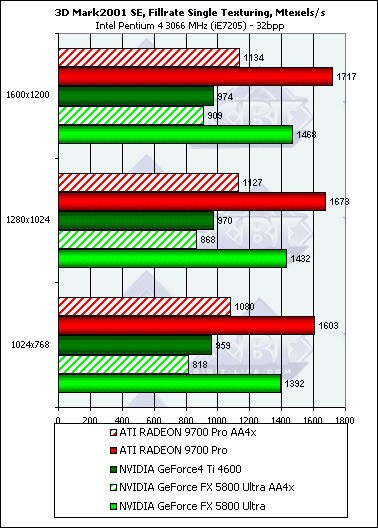 The dependence is very similar to the Pixel Filling from RightMark 3D, but here it is weaker - the test quality is lower and the figures are farther from the maximum. Multitexturing:
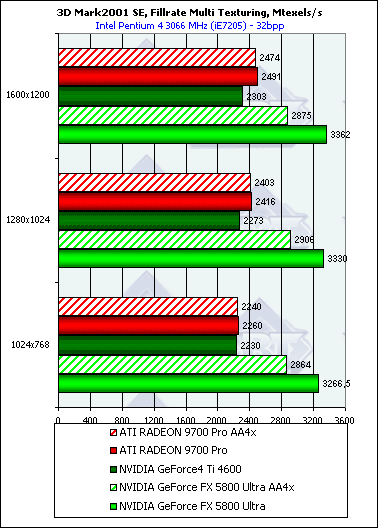 The results also remind those obtained in the RightMark 3D tests. The AA mode has a much greater effect on the NV30 than on the R300 - in spite of the frame buffer compression in MSAA which takes place both in R300 and in NV30, the NVIDIA's solution has the narrower memory bus of 128 bits. Scene with a large number of polygons
  NV30 leads, and the gap grows up as the number of light sources increases. It tallies with the data from the Geometry Speed Test from RightMark 3D. Pixel ShaderSimple variant:
 The NV30 thrives here as well. This test actively samples textures but makes minimal calculations; besides, all calculations are made in the integer format (shaders 1.1); the NV30 deals with integer instructions twice faster than with floating-point ones. Let's see if the picture will change with more intensive calculations
of the pixel shaders:
 Now the R300 is ahead, proving that the NV30 has a weaker computational performance and a higher texture one. Vertex Shaders
 The VS test provides strange results. All above tests show the opposite. Probably, it's caused either by the too short shader or by the great dependence on the fillrate (the hgiher the resolution, the lower the scores; and in case of the NV30 the scores fall down faster). However that may be, but we are inclined to trust the synthetic tests of RightMark 3D which do not show such strong dependence on a resolution. Sprites
Nothing new. Bump mappingLook at the synthetic EMBM scene:
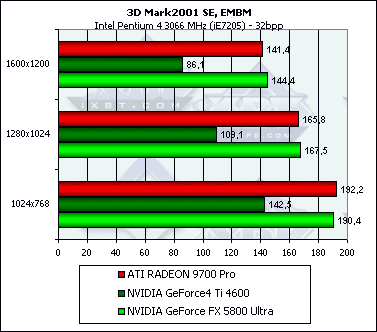 DP3 relief:
 Here the NV30 just slightly outscores the other. In general, the results of the 3D Mark 2001 conform to the RightMark 3D though they carry less information because the parameters of the synthetic tests are not changeable. Additional theoretical information and Summary on the synthetic testsAnisotropic filteringImplementation of the anisotropy of the NV30 in comparison with the R300
will be estimated with the Xmas program meant for visual studying of the
filtering quality:
 The program draws a cylindrical tunnel with a changeable number of planes
which helps to observe different angles of inclination relative to the
normal to the screen plane. With 15 planes we will get a clear set of planes
with 5 angles from 0 to 90 degrees. So, the highest anisotropy level, R300
on the left, NV30 on the right:
At any angle the NV30 shows the same picture which depends only on the plane's inclination. The R300 copes only with the angles of 0 and 90 degrees and angles close to 45. At all intermediate angles (20, 30, 60, 70 etc.) the ATI's algorithm works much worse. Later we will explain it. If you remember, the R200 could cope only with 0 and 90 degrees. MIP levels depending on the anisotropy degree. R300 on the left, NV30 on the right: |
| ANISOTROPIC | RADEON 9700 PRO | GeForce FX 5800 Ultra |
| No |  |
 |
| ANISO 2 | 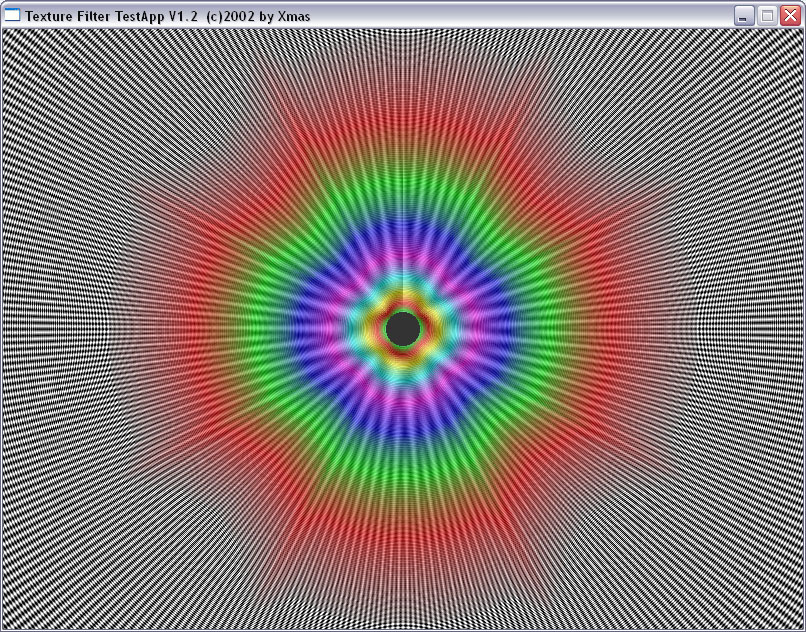 |
 |
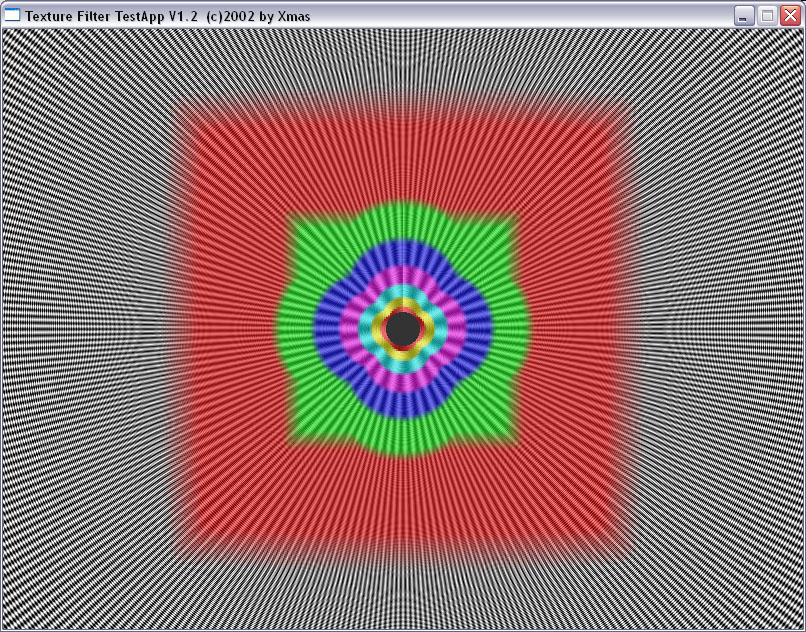
| ANISO 4 | 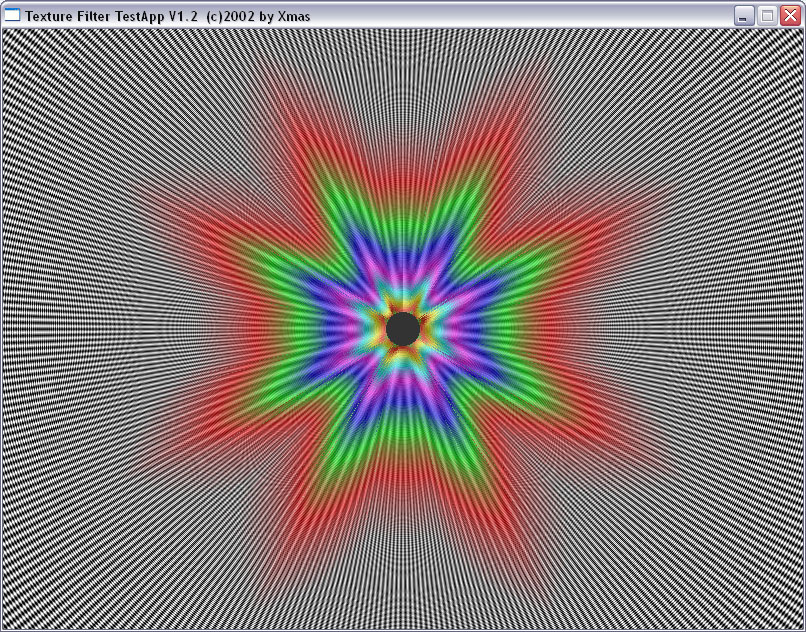 |
 |
| ANISO 8 |  |
 |
| ANISO 16 | 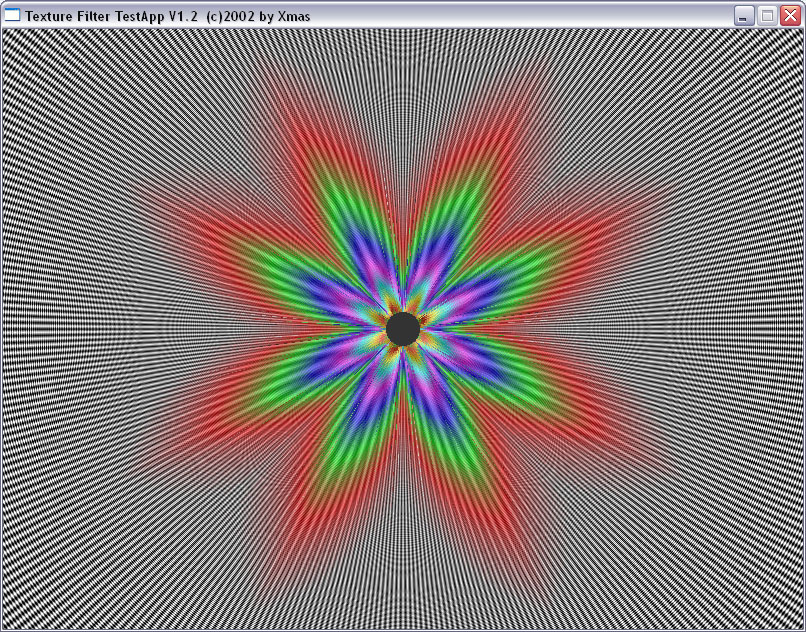 |
- |
At a low anisotropy degree the ATI's algorithm behaves similarly to
the NVIDIA's one selecting MIP levels correctly according to the real distance
(an ideal picture must represent circles), but at a higher anisotropy level
the NVIDIA's and ATI's methods use different approaches. I must say that
the NV30 works more correctly in case of longer distances (far tunnel end)
and a high anisotropy level.
Only Today and Only Now. Anisotropic filtering algorithms of NVIDIA and ATI.NV30
 Here is a texture plane. We can see this texture under a certain angle. The black arrow indicates the anisotropy direction - a projection of our look's direction on the texture through the screen plane. The thin lines show the edges of the screen pixel to be filled, namely, its projections on the texture plane. The stars show the samples each of which is selected with the bilinear filtering. The samples' positions are chosen with a pseudo-random algorithm which tries to cover the whole figure's plane onto which the screen pixel is projected with samples more or less uniformly. The number of samples depends on the texture's angle - the greater the angle we look at it, the lengthier the pixel's projection and the more samples which should be taken for high-quality filtering. It also depends on the anisotropy degree - the higher the degree, the more there are samples at the same inclination angle. This algorithm doesn't depend on the plane's degree of rotation (we saw it above). The weak point of the algorithm is honestly chosen bilinear samples. A MIP level of a texture the samples are taken from is defined only once for the whole pixel. R300
 First of all, I want to destroy the myth that ATI uses a variation of the RIP mapping and additional narrowed texture versions. Nothing of the kind - the anisotropic filtering works with the same source textures as the NVIDIA's one does, and no extra space or extra calculations are used. They have entirely different filtering algorithms. Firstly, the samples are selected one by one, without preliminary bilinear filtering. The filtering is indirect here - the algorithm decides from what MIP level it should take a sample; on the picture above small squares refer to samples from a more detailed MIP level, and bigger squares are from a rougher one. So, we can take much more samples using same computational resources and bandwidths, but the samples won't be originally filtered which may result in inferior quality. But the difference is not very noticeable, and a right choice of a MIP level for each sample makes it even smaller (it's possible to use some stochastic algorithm which would alternate different levels for higher-quality anisotropy and smoother transitions between MIP levels, i.e. simultaneous trilinear filtering). The second red arrow on the diagram shows the direction in which samples are selected. There are only three possible directions - vertical, horizontal (dotted line) and under the angle of 45 degrees which is used in this case. That is why at the intermediate angles this method is not very effective (remember the Xmas?). But at these angles the algorithms works fast using less memory and cache at the same visual quality level. So, the NVIDIA' anisotropy is more uniform and theoretical, while the ATI's one is more practical and allows for more samples at the same limitations. Until recently the NVIDIA's algorithm lost to ATI in speed, but the NV30 chip and its drivers have optimizations for performance boost without quality losses. The performance gain is admitted (RightMark 3D), but it's not only because of the optimization in sampling but also because of the higher core's frequency. How the optimization tells upon quality will be shown later in screenshots of real applications. Full-Screen Anti-AliasingAs we said in the analytical review on the NV30, it has MSAA 4x and various hybrid modes (6xS and 8x). The most interesting feature of the GeForce FX is frame buffer compression. Both depth and color values are compressed. NVIDIA says that the compression algorithm is lossless. It uses the fact that in MSAA modes most AA blocks in the frame buffer are not on the triangle edges and therefore have identical color values. The frame buffer compression has a lot of advantages:
By the way, we saw that the R300 also supports the color information compression in a frame buffer. Remember how the MSAA is executed. No additional calculations are needed - all samples within the AA unit are formed from one value obtained by the pixel shader. The only cause of the performance drop is necessity to transfer a frame buffer which is increased several times (at 4x the frame buffer will be 4 times greater, at 2x - twice greater). But at 4x most AA units have two or more often one (!) unique color value. It's not easy to find units with three or four unique color values. It would be silly not to code information of such MSAA buffer effectively by recording only actual different colors. Thus, we almost fully make up for the increased buffer size in case of MSAA. Will the practice prove it? The GeForce FX includes the new hybrid MSAA mode named 8xS and one more named 6xS. These modes are a combination of SS and MS anti-aliasing - there are still two types of MSAA 2x2 blocks in the base, like in NV25, - 2x with diagonal arrangement of samples and 4x; samples are then averaged with one or another pattern like in the previous generation. That is, the chip like NV25 can record up to 4 MSAA samples from one value obtained with the pixel shader. Hence the compression factor of 4:1. For the FSAA modes based on MSAA 2x blocks this factor equals 1:2. So, the main idea of the GeForce FX is compression of the depth and
frame buffers, especially in FSAA modes. The fact that they use a 128bit
bus indicates that they count on the compression. Is it justified? The
preliminary results of the synthetic tests make me doubt that it's rational
to use such bus.
Andrey Vorobiev (anvakams@ixbt.com)
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. |
















