|
||
|
||
| ||
|
||
|
||
| ||
The method and results of K7/K8 L2 cache latency and bus bandwidth testingThe need in this material arose because AMD documents are too concise and inconsistent. The respective sections are taken from older Athlon manuals with minimal changes with K8 bus width left untouched. However, the latest Athlons have been working in our systems for some time already and the first K8 models are available already. This allows us to check some aspects directly, i.e. by testing. So, let's begin... L2 cache latency examination in a dependent chainIn order to do this, let's create a dependent chain (or a singly linked list in terms of C) in a fixed RAM array (block). Each array element contains an address of another element (a pointer in terms of C), and the address chain is designed so that if we move from the first element, we'll traverse all other once to return to the first one again. Let's examine two chain types corresponding to different array elements traversal:


When a dependent chain is created and initialized according to either of above types, the address of the 1st element is loaded into EAX register and the assembler traversal code is very simple:
mov eax,[eax]
Now if we measure the chain traversal time and divide it by the element number, we'll obtain the average load-use latency. To get the CPU cache access latency we should equalize the array element size with the cache string size, i.e. 64 bytes (then a single element access will mean a single string access), and also make the array smaller than or equal to cache. Then after the first several traversals the entire array will fit into cache, so during the precise time measurements data will be loaded from cache only. Thus in case of Opteron <64Kb chain traversal will provide L1 latency, while 96-1088 Kb chain traversal will provide L2 latency. In the table below you can see the results in clocks for K7/K8 architectures and different arrays. The first value stands for the sequential access, the second - for random.
You can see that L1 latency is 3 clocks, while L2 latency for this chain is higher than 11 clocks provided in AMD documents. Let's suppose that latency increases because load and evict stages overlap. We'll try to shed more light on this in the next test. It's also evident that sequential latency is higher than random in case of Athlon XP, in particular, it's 24 clocks higher than provided for maximum latency (20 clocks). These additional 4 clocks are required for hardware prefetch that operates in case of the sequential access. Not to clutter up results with these resource expenses (that are required in seldom cases of strong bus load), further we'll provide random access results if not stated otherwise. L2 latency cache examination in a dependent chain with nopsTo avoid overlapping of load and evict stages, let's add instructions not related to cache access, but injecting pauses between adjacent instructions. Let's call these nops for short.
Now the assembler code for chains with different nop amounts (considering EDX always contains 0) will look like:
In K7/K8 architectures each nop instruction like "add eax,edx" will be pausing the chain execution by a single clock. So now to obtain the correct latency value we'll have to subtract nop amount from the average access time. Below are K7/Palomino latencies for different nop amounts and three arrays (64Kb, 112Kb and 256Kb): 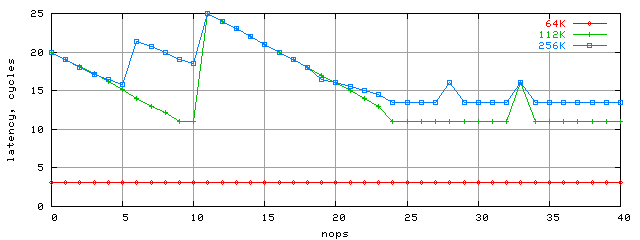
L1 cache latency remained the same 3 clocks. But L2 latency became the promised 11 clocks (for 112Kb block; 9, 10 nop; >24 nops). For bigger blocks this number increases only by 2 clocks related to L1D TLB cache limits that's enough for 128Kb random access (32 strings) only. In real apps with higher data locality (within 4K virtual memory pages) this effect won't be strong, so the 112K block is indicative enough. However, we believe the most interesting result is the graph behavior - regular, but with occasional jumps to 25 latency clocks. In the future we'll try to explain this. We should also note that these latency pictures vary for different Athlon cores. This speaks for AMD's constant search for better (still hasn't reflected in the docs.) In particular, L2 latency for K7/Thoroughbred is worse than K7/Palomino's. You can see this on the next graph that includes K8 results as well (112Kb block size): 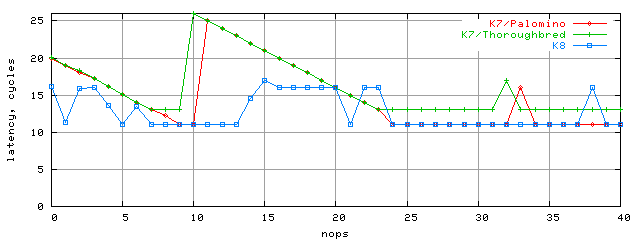
Well, the general latency picture has changed significantly in K8. It's nice that values have reduced almost for every case. We believe that K7's L2 latency increase is related to the limited L1-L2 bus bandwidth. If it's so, than the bandwidth have increased. For more details on this see the next section. And here, you can finally see the K8 latency graph for a dependent chain and different block size and access modes (Rnd - random, Seq - sequential). 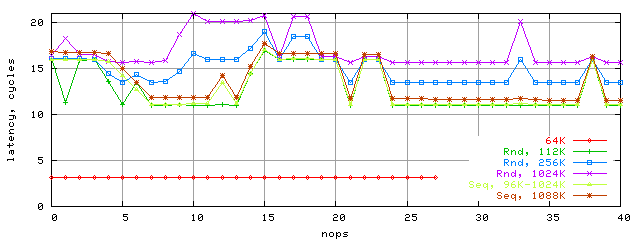
L1-L2 bus bandwidth testFirst, let's use above results to calculate the corresponding L1-L2 bus bandwidth. At that we'll consider that each L2 access (i.e. loading a single L2 string into L1) is accompanied by backward transfer of L1 string into L2 in the exclusive cache architecture. I.e. a single access results in 64+64 = 128 bytes transfer via L1-L2 bus. Using this algorithm, let's recalculate this latency into the corresponding bandwidth: 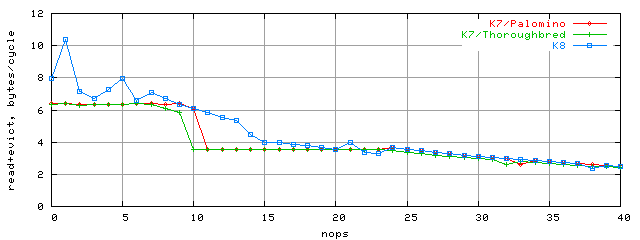
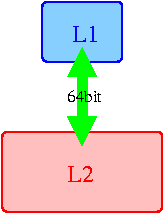
You can see that K7's access to L2 is limited by L1-L2 bandwidth of 6.4 bytes/clock that fully corresponds to a single duplex bus 64-bit wide (considering turnaround losses, 6.4 = (64+64) / (8+2+8+2)). At the same time K8 doesn't have this limit, so in our case it provides 10 bytes/clock bandwidth. Again, we bandwidth calculated bandwidth on the condition of full L1-L2 cache exclusiveness for our case (whether there are any modes in which K8 is not fully exclusive, or not we'll leave for the future). And now it's high time to check this thesis. But first let's extend the described method a bit and create several (1, 2, 4, or 8) dependent chains instead of the one to traverse them in parallel. The assembler code for dual-nop chains looks like:
And now let's build the graph of bandwidth dependence on block size for different amounts of parallel access chains: 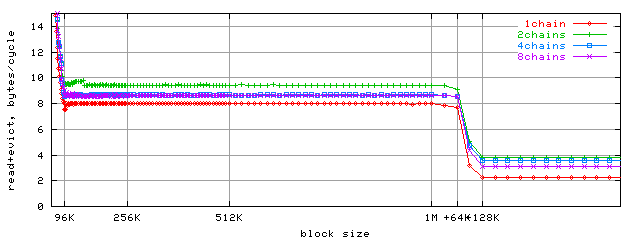
As the bandwidth stays high up to L2+L1D block size (1088K = 1M + 64K), the cache exclusiveness should be considered proven.
Below you can see the bandwidth comparison graph sequential and random access to 96K block: 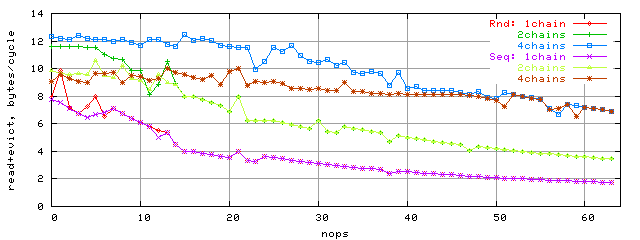
We just have to try and get the maximum L2 bandwidth that should be on the conditions above. To do this, we'll build bandwidth dependence on nop amount for 2 and 4 access chains: 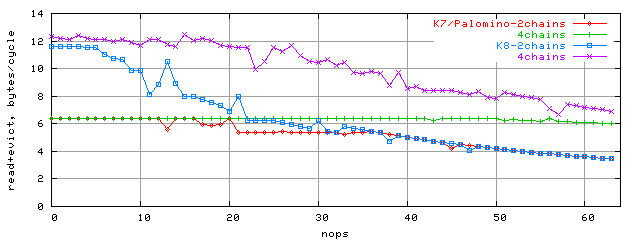
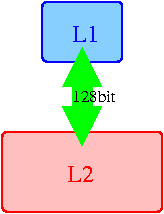
Exactly here you can note the maximum L1-L2 difference between K7 and K8 architectures. The bandwidth has grown almost twice, up to 12 bytes/clock. Of course, it would be impossible to pump that much data through the old 64-bit bus in a single clock. It should now be clear that effective bus width of K8 architecture is 128 bit. And the bus design itself is described in the next section. Checking the 128-bit bus width hypothesisSo the effective L1-L2 bus width has been doubled in K8 comparing to K7 to make 128 bits. Let's check if its architecture has remained the same (single duplex bus). If it's so, we should be able to load each cache string in 4 clocks (64 bytes / 128 bits = 4 clocks). If not, the only sensible alternative is two 64-bit unidirectional buses. All these variants are shown below:
To understand if the middle variant is correct, let's change our dependent chain method again to consider a single chain as we have done before. If you remember, each chain element was to be passed only once each chain traversal (element size = 64 bytes = cache string size). At that each clock we were reading a single 4-byte word with 0 offset from the element beginning. 
Now in each element we'll be reading words with O1 offset first and words with O2 offset inside the element next. 
We'll also add fixed time lapses (nops) before new cache string access (red arrows above) as well as additional fixed lapses (let's call them sync-nops) between two words in the same cache strings (before green arrows). This will enable us to avoid penalties for untimely access to data that hasn't arrived yet (at strictly fixed amount of sync-nops) and avoid sequential loads interference (at large enough amount of nops). Considering all of the above the assembler code (for 2 sync-nops and 3 nops)
mov eax,[eax] ; initial cache string access (red arrow)
And now let's look at latency results for loading two words located in the same string depending on the relative offset (offset = O2 - O1) in this string. At that nops = 64 and sync-nop amount was chosen to minimize the average latency. On the graph below you can see latency in clocks for the 1st word and 2nd word as well as the delay between. Also note that in this test all K7/Palomino and K8 results have turned out to be identical. Besides, they haven't depended on 1st word's O1 offset in the string (at that the relative offset is chosen considering the string size). 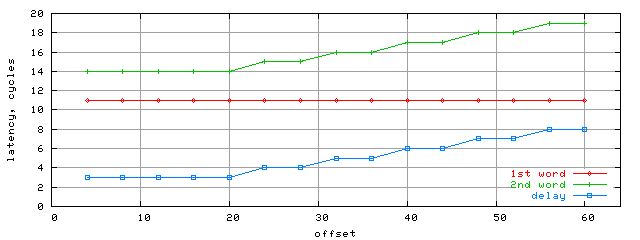
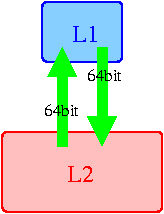
The last test results prove that the read width of L1-L2 bus is 64-bit. Considering the results from the previous section, where we proved that effective width of L1-L2 bus in K8 architecture is 128 bits, which means the remaining 64 bits are used for evict operations. Therefore the correct bus variant is shown on the right. Test conclusionsIn general we can say that comparing to K7, K8 has some changes implemented into L2 access engine. Still they are not principal, but mostly evolutional used to widen the bottlenecks. However, our estimations of this separated into two alternative groups, so we publish them both:
|
|
Article navigation: |
| blog comments powered by Disqus |
| Most Popular Reviews | More RSS |
 |
Comparing old, cheap solutions from AMD with new, budget offerings from Intel.
February 1, 2013 · Processor Roundups |
 |
Inno3D GeForce GTX 670 iChill, Inno3D GeForce GTX 660 Ti Graphics Cards A couple of mid-range adapters with original cooling systems.
January 30, 2013 · Video cards: NVIDIA GPUs |
 |
Creative Sound Blaster X-Fi Surround 5.1 An external X-Fi solution in tests.
September 9, 2008 · Sound Cards |
 |
The first worthwhile Piledriver CPU.
September 11, 2012 · Processors: AMD |
 |
Consumed Power, Energy Consumption: Ivy Bridge vs. Sandy Bridge Trying out the new method.
September 18, 2012 · Processors: Intel |
| Latest Reviews | More RSS |
 |
Retested all graphics cards with the new drivers.
Oct 18, 2013 · 3Digests
|
|
Added new benchmarks: BioShock Infinite and Metro: Last Light.
Sep 06, 2013 · 3Digests
|
|
Added the test results of NVIDIA GeForce GTX 760 and AMD Radeon HD 7730.
Aug 05, 2013 · 3Digests
|
 |
Gainward GeForce GTX 650 Ti BOOST 2GB Golden Sample Graphics Card An excellent hybrid of GeForce GTX 650 Ti and GeForce GTX 660.
Jun 24, 2013 · Video cards: NVIDIA GPUs
|
|
Added the test results of NVIDIA GeForce GTX 770/780.
Jun 03, 2013 · 3Digests
|
| Latest News | More RSS |
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook
Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved.