 |
||
|
||
| ||
|
||
|
||
| ||
320 Shader Processors and 256-bit Memory BusPart 1: Theory and architectureWe've recently reviewed the the GeForce 8800 GT - an excellent Mid-End solution from NVIDIA. Now it's time to review a similar product from AMD. Remember how bad the previous Mid-End solutions from AMD and NVIDIA were (based on RV630 and G84)? Their performance suffered because too many features were cut down compared to top solutions, they had too few execution units: ALUs, TMUs, and ROPs. Their performance was also limited by the narrow 128-bit memory bus. Its implementation was especially weak in the RADEON HD 2600 XT compared to the 512-bit bus in the top RADEON HD 2900 XT. The AMD R6xx architecture was announced in May. Only the top R600-based solution was launched at that time. Mid- and Low-End cards based on the unified R6xx architecture were postponed till summer. It became clear that we wouldn't get good Mid-End solutions manufactured by the 80/90 nm fabrication process from both GPU makers. DirectX 10 support and unified architectures limited GPU complexity. So even cheap GPUs had to use quite complex units, for example, thread processors. That's why there are not many transistors left for execution units, so it was very difficult to design a fast Mid-End processor based on the 80/90-nm fabrication process. Now that NVIDIA adopts the 65-nm fabrication process, and AMD is mastering even the 55-nm fabrication process, there appear truly powerful Mid-End GPUs. They are actually former top GPUs manufactured by a thinner fabrication process. They demonstrate appropriate performance. The only problem is narrower memory bus width. The main difference between RV670/G92 and R600/G80 is the fabrication process (55-nm and 65-nm correspondingly). It reduced the primary costs of complex GPUs, which is important for inexpensive products. Moreover, unlike the R600, the new GPUs from AMD support DirectX 10.1, PCI Express 2.0, and include an improved unit of hardware-assisted video playback and processing. Before you read this article, you should read the baseline reviews - DX Current, DX Next, and Longhorn, which describe various aspects of modern graphics cards and architectural peculiarities of NVIDIA and AMD (ATI) products.
These articles predicted the current situation with GPU architectures, a lot of forecasts on future solutions came true. Detailed information on the unified architecture of AMD R6xx (by the example of older GPUs) can be found in the following articles:
So, the overhauled RV670 is based on the RADEON HD 2000 (R6xx) architecture. This GPU includes all main features of this family, such as the unified shader architecture, full DirectX 10 support (DX 10.1), high-quality methods of anisotropic filtering and a new antialiasing algorithm with the increased number of samples, etc. The RV670 offers better features. This GPU is used in Mid-End solutions for 179-229 USD. I repeat that the key technological innovation is the 55 nm fabrication process, which helps reduce the costs and bring these solutions down to this price segment. One of the important improvements is UVD, which is not available (or it does not work as it should, which is almost the same) in the R600. The situation is exactly like with NVIDIA cards - low-end and mid-end GPUs offer better features for video decoding. We shall return to analyzing performance and quality of video decoding in the new solutions from AMD and NVIDIA in continuation of our older analysis. RADEON HD 3850 and HD 3870
RADEON HD 3870 Specifications
RADEON HD 3850 Specifications
As you can see, AMD decided to change the traditional designation of ATI RADEON cards starting from the RADEON HD 3870 and 3850. For example, in the RADEON HD 3870, the first numeral (3) denotes a generation of graphics cards, probably starting from X1000 (X1800, X1600, etc), the second numeral (8) - a family of cards, the third and fourth numerals (70 in this case) - a given model of a graphics card within the specified generation and family. As usual, a greater numeral suggests higher performance. AMD gives the following translation of the new titles into the old designation scheme: 50 means PRO, 70 stands for XT. We should publish our traditional digression about the amount of video memory required by modern games. Our recent analysis shows that many modern games have very high requirements to video memory size, they use up to 500-600 MB. It does not mean that all game resources must be stored in local video memory. Resource management may often be given to API, especially as Direct3D 10 uses video memory virtualization. Nevertheless, modern 3D applications tend to increase their requirements to local video memory size. So 256 MB is the minimum size, and the optimal solution is presently 512 MB. You must take it into into account, when you choose between two products of the HD 3800 family. They do not differ that much in price. So, AMD again enters the market of Mid-End graphics cards as a technological leader, its new GPUs are manufactured by the 55 nm fabrication process. These transitions are relevant, because finer process technologies provide such advantages as smaller cores or more transistors on the same die area, they increase the frequency potential of GPUs and yield of effective GPUs at high clock rates, as well as reduce primary costs. If we compare surface areas of the R600 (80 nm) and RV670 (55 nm), which have a similar number of transistors (700 and 666 millions correspondingly), the difference is more than twofold: 408 and 192 square mm correspondingly! Higher density of transistors affected the so called energy efficiency - the RV670 consumes twice as little power as the R600, demonstrating similar performance! Unfortunately, the advantage of the finer fabrication process is weaker here than in the competing product from NVIDIA. The older Mid-End card from AMD consumes similar amounts of power and dissipates as much heat as the competing graphics card based on the G92 manufactured by the 65 nm fabrication process, which has a larger die. ArchitectureIn our previous articles (R600, RV630), devoted to the announcement of the R6xx architecture and the RADEON HD 2900/HD 2600/HD 2400 cards, we described all architectural features of the new GPU family with the unified architecture from AMD. This article will only give a recap, you may consult the above mentioned articles for details. The RV670 has all the features available in the previous solutions (320 unified processors, 16 texture fetch units, 16 raster units, programmable tessellator, etc) with minor modifications to support Direct3D 10.1 (we'll speak about it later.) Architecture of the R6xx combines some old solutions (R5xx and Xenos) with new features: a powerful thread processor, superscalar architecture of shader processors with dedicated branching units, etc. The block diagram of the RV670 is absolutely identical to that of the R600: 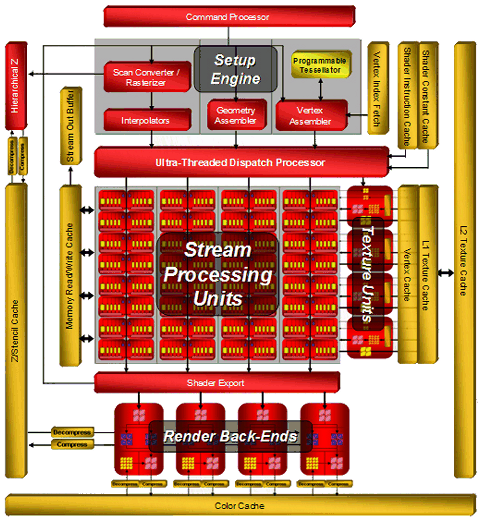 In fact, the RV670 does not differ from the R600, it has the same number of all units (ALU, ROP, TMU.) You can read about all architectural features of the R600 in the baseline article, the link is published above. The only difference of the new Mid-End GPU that deteriorates its performance is its 256-bit bus versus the 512-bit bus. But all other things in that article hold true for the new product. Of course, AMD claims that the memory controller in the RV670 was optimized for more efficient bandwidth usage, that the 256-bit bus is actually 512-bit inside, etc. One of the presentation slides even runs that the HD 3870 performs on a par with the RADEON HD 2900 at equal clock rates. If memory bandwidth efficiency is also taken into account, does it mean that the R600 cannot utilize the entire capacity of its 512-bit bus? Why is the RV670 so efficient? We'll touch upon this issue in the next parts. Direct3D 10.1 supportAMD calls the RV670 the first GPU with DirectX 10.1 support. The company praises innovations in this updated API to the skies and promises global illumination and ambient occlusion in real time. NVIDIA does not have such solutions so far, so it calls DX 10.1 a minor update, which is not very relevant for the industry. That's a usual marketing game, we've seen it many times. Let's try to find out how important the 10.1 update is. This version of DirectX will be available only in the first half of the next year, together with an update for MS Windows Vista. Service Pack 1 with DirectX 10.1 will not be released soon, to say nothing of new API features in real games. That main change in this version is some feature improvements: updated Shader Model 4.1, independent blending modes for MRT, cube map arrays, reading and writing values into buffers with MSAA, simultaneous texture fetch Gather4 (it was known as FETCH4 in ATI GPUs), mandatory blending of integer 16-bit formats and filtering of 32-bit floating-point formats, as well as MSAA support with at least four samples, etc. New features of DirectX 10.1 will facilitate some rendering techniques (for example, global illumination in real time). All new features can be divided into the following groups: shading and texturing improvements, changes in antialiasing and specifications. Let's try and find out what they give us in practice.
As we have already mentioned above, some of the new features of DirectX 10.1 simplify development of algorithms that raise 3D graphics quality. AMD gives an example of Global Illumination (GI). As sterling GI is too complex to compute in real time, most old games use indirect illumination with a constant ambient component, the roughest GI approximation. They sometimes use better methods, described in the article, which link is published above. As far as GI is concerned, the advantage of DirectX 10.1 is in using cube map arrays together with geometry shaders in the efficient algorithm of GI in real time. That's how it works: a scene is divided into parts corresponding to a 3D array of cube maps. Each facet of a cube map contains a simplified scene with a camera pointed from the center of the cube outward (light probe), all six facets are recorded in a cube map. Resolution and detail level of these cube maps must not be too high, a scene must be rendered in real time.  Each cube map is converted into a spherical representation using spherical harmonics. It allows to determine illumination intensity and color for each point in a cube. Points between cubes are interpolated using values from neighboring cube maps. Besides, cube map arrays can be used for high-quality reflections for many objects in a scene. This method of computing GI scales well depending on the size and number of cubes (into which a scene is divided), as well as resolution and detail level of cube maps. New features of DirectX 10.1 allow to use arrays of cube maps. A lot of cube maps are drawn simultaneously, which increases efficiency of this technique. Another interesting technique facilitated in DirectX 10.1 is ambient occlusion. It computes the amount of light that reaches a given point in all directions and the amount of light reflected by objects, which didn't make it to the point. That is, parts of a scene surrounded by objects will be darker than points, which have no objects standing in the light. This feature makes the image look more realistic. DirectX 10.1 features facilitate the task with Gather4 texture fetches. This technique use single-channel textures of special format to store data, unlike usual RGB(A) textures. Gather4 allows to fetch four samples from such textures simultaneously. It can be used to improve texture filtering or to increase performance. Let's talk about improvements in antialiasing. The most popular method of antialiasing is multisampling (MSAA), which works only on polygon edges, and does not smooth textures and pixel shaders. DX 10.1 has new features that make it easier to solve these problems. We wrote in the baseline article that the RADEON HD 2000 family featured a new AA algorithm - custom filter anti-aliasing (CFAA), a flexible programmable method. DirectX 10.1 allows to use special AA filters from pixel shaders. Such methods improve image quality when the regular MSAA algorithm experiences some problems. For example, in case of HDR rendering or deferred shading. Such algorithms use shader access to screen buffers that appeared in DX 10.1. The older DX version allowed to read and write data only to multi-sample color buffers. Direct3D 10.1 now allows to read and write data from/to Z buffer for each sample separately. So 3D developers can use advanced AA methods in custom algorithms and even combinations of usual AA and shader AA. Many new features of DirectX 10.1 are useful, of course, but we shouldn't forget that the updated API will appear in six months. Graphics cards with its support will also take some time to spread (by the way, NVIDIA plans to introduce the DirectX 10.1 support in the next generation of its products, which will appear only after Service Pack 1 for Vista). Besides, the first graphics cards will certainly be slow at using some of the new features of the API. Interestingly, some game developers regard DirectX 10.1 as a minor update, and they don't even plan to use it. Perhaps, their attitude will change in time, because some features of the new API will really help them improve the quality of real-time rendering. PCI Express 2.0The RV670 offers sterling support for PCI Express 2.0. The second version of PCI Express doubles the standard bandwidth, from 2.5 Gbit/s to 5 Gbit/s. As a result, the standard graphics slot (x16) can transfer data at up to 8 GB/s in each direction (marketing specialists love to sum up these numbers and specify 16 GB/s) versus 4 GB/s for Version 1.x. Besides, PCI Express 2.0 is compatible with PCI Express 1.1. Old graphics cards will work in new motherboards, and new graphics cards supporting the second version will still work in motherboards without this support. External power supply being sufficient, of course. And they won't have the increased interface bandwidth. It's not easy to evaluate the real effect of higher PCI Express bandwidth on performance - tests should be run in equal conditions, which is problematic. But higher bandwidth won't hurt, especially for SLI/CrossFire systems that exchange data via PCI Express as well. Besides, lots of modern games require large volumes of fast memory. When there is not enough video memory, a game will use system memory, so PCI Express 2.0 will certainly be welcome. 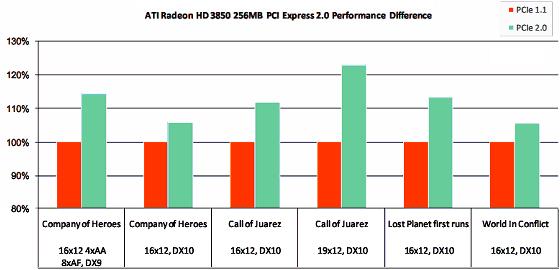 AMD publishes the following data for RADEON HD 3850 with 256 MB of memory: performance difference between systems with PCI Express 1.x and 2.0 in Company of Heroes, Call of Juarez, Lost Planet, and World In Conflict varies from 5% to 25%, about 10% on the average. In high resolutions of course, when a frame buffer and contiguous buffers occupy the biggest part of local video memory, and some resources are stored in system memory. To provide backward compatibility with existing PCI Express 1.0 and 1.1 solutions, Specifications 2.0 support both 2.5 Gbit/s and 5 Gbit/s transfer rates. Backward compatibility of PCI Express 2.0 allows to install older 2.5 Gbit/s solutions in 5.0 Gbit/s slots, which will operate at a lower speed. And devices designed in compliance with Specs 2.0 will support both 2.5 Gbit/s and 5 Gbit/s. As usual, it's all good on paper, but engineers may encounter some compatibility problems with some combinations of motherboards and expansion cards. ATI CrossFireXBoth AMD and NVIDIA decided to surprise users with multi-GPU configurations and systems with two or more graphics cards. RV670-based solutions are the first graphics cards to support quad-card systems (or configurations with two dual-GPU cards). However, quad-card configurations make sense only in very high resolutions and optimized applications with optimized drivers. Moreover, gameplay won't actually improve in some CrossFire modes, even if the frame rate grows. However, this issue should be discussed in a separate article. If GPU makers say it's necessary, then it's true. They regard multi-GPU configurations as a way to increase performance (in benchmarks in the first place). Starting from CATALYST 7.10, a special mode is enabled by default for all DirectX 9 and 10 applications - it's called Compatible AFR. It will not fix all problems and bugs, but it should raise performance more often than CrossFire systems before this great moment. The question is how much performance will be gained. We like what both companies say - efficiency of CrossFire and SLI is very high, up to 80% (it's more like 50% in reality) in super high resolutions like 2560x1600. But these results are demonstrated in benchmarks, not in games. These figures are for people who play 3DMark. Along with an excellent opportunity to install four graphics cards consuming over 100 W each, CrossFireX allows to overclock multi-GPU solutions, including automatic detection of operating frequencies, as well as support for some new multi-monitor modes, up to eight monitors. They promise to enable this very important feature in the drivers to be released in early 2008. ATI PowerPlayUnlike CrossFire, the real improvement for common users is the ATI PowerPlay technology - it's dynamic power management technology that came from GPUs for notebooks. A special control circuit in a GPU monitors its load (by the way, GPU usage is shown on the Overdrive tab in CATALYST Control Center) and determines a necessary operating mode by controlling clock rates of a GPU, memory, voltages, and other parameters, optimizing power consumption and heat release. In other words, the voltage and clock rates as well as the fan speed will be minimized in 2D mode, when the GPU is not loaded much. In some cases the fan may be even stopped. Under some 3D load all parameters will be set to medium. And when the GPU works at full capacity, voltages and clock rates will be set to maximum. Unlike the previous solutions from AMD and NVIDIA, these modes are controlled by the GPU itself, not by the driver. That is this control is more efficient, with shorter delays, and without the notorious problems with detecting 2D/3D modes, when a 3D application in a window is not detected by the drivers as a 3D application. AMD compared power consumption of the HD 2900 XT and the HD 3870 in its presentation. While the difference in power consumption and heat release in 2D and intensive 3D modes is the usual twofold, in the light game mode (frankly speaking, I don't understand what games are meant here, probably very old projects and modern casual 3D games) the difference reaches fourfold. So, we've examined theoretical peculiarities of the new Mid-End RV670. The next part will cover practical tests, where you will learn how performance of the new graphics cards based on RV670 relates to performance of the previous cards from AMD and competing graphics cards from NVIDIA based on the G92. We'll also find out the effect of the cut-down memory bus on their performance compared to the flagship - RADEON HD 2900 XT. Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. |














