 |
||
|
||
| ||
|
||
|
||
| ||
The First Test Results in RightMark Memory AnalyzerWe've already published many articles devoted to revealing performance potential of dual-channel DDR2-800 memory (and faster products). Interest to such reviews is caused by the high performance potential of dual-channel DDR2 memory as such, which is still unrevealed due to bottlenecks, represented by other components of the memory system. In case of the Intel platforms, the key bottleneck is the FSB shared by all CPU cores (and system processors, if we speak about multiprocessor systems). Its bandwidth is always lower than that of dual-channel DDR2 memory. In our previous analysis of this issue we reviewed Intel 975X and 965G chipsets with 266 MHz FSB, which bandwidth was about 8.53 GB/s. We almost reached real memory bandwidth results coming close to this mark. But this mark is still far from the theoretical bandwidth of DDR2-800 memory (12.8 GB/s), so we couldn't say that we revealed full performance potential of such memory. Analysis of multicore AMD platforms with the integrated DDR2 memory controller (starting from AM2) is of special interest. Theoretically, these platforms can reveal full bandwidth potential of the memory system, as they don't have the FSB bottleneck, shared by all CPU cores, which theoretical bandwidth is sure lower than the theoretical bandwidth of dual-channel DDR2. Nevertheless, our first analysis of AMD AM2 representatives (Athlon 64 X2 and Athlon 64 FX operating at 2.0-2.8 GHz) showed that real memory bandwidth results that could be obtained on this platform were much lower than their theoretical maximum, and they were directly dependent on clock rates of a CPU core and a memory controller. As we found out, the reason was in a relatively narrow (64-bit bidirectional) L1-L2 bus of the CPU core, which effective bandwidth is lower than the theoretical bandwidth of the dual-channel DDR2-800. Then we tried to analyze multicore memory access, in this case — from two threads executed on both processor cores. This way of accessing memory should have lifted off the limitation of narrow L1-L2 bus of the processor core, because each core of Athlon 64 X2 processors has its own L1- and L2- caches. However, the increase in memory bandwidth from the dual-core memory access method was not very big — for example, the increase did not exceed 15% in memory read tests with software prefetch, and the absolute memory bandwidth results were less than 70% of the theoretical maximum. This time the bottleneck was apparently in the integrated memory controller itself. Thus, our previous reviews demonstrate that the full performance potential of dual-channel DDR2-800 memory (and especially its faster modifications) on Intel platforms is limited by a relatively narrow FSB shared by all CPU cores. What concerns AMD AM2, the problem is in the older architecture of AMD Athlon 64 X2 processors (which hasn't been changed much since the first Athlon 64 models) and the limited efficiency of the integrated DDR2 memory controller. So we expect much from the new generation of platforms from Intel and AMD. The former is represented by the 3.2 GHz quad-core Intel Core 2 Extreme QX9770 processor based on a new 45-nm Yorkfield core and Intel X48 chipset. FSB clock rate of this processor and chipset is 400 MHz, its bandwidth matches that of dual-channel DDR2-800 memory. The latter platform is based on the engineering sample of a 2.4 GHz processor from the recently announced family of quad-core processors - AMD Phenom X4. These processors have a modified architecture of the core (especially its bottleneck — L1-L2 D-Cache bus) and the integrated memory controller. Let's start with test results demonstrated by the first of these platforms. Intel Core 2 Extreme QX9770 / Intel X48On this platform we used dual-channel DDR2-800 memory (5-5-5-15 timings), because as we mentioned above, theoretical bandwidth of this memory type is identical to the theoretical bandwidth of the 400 MHz FSB. It means synchronous operation (FSB:DRAM = 1:1), which is optimal from the point of view of memory performance. We took the readings with RightMark Multi-Threaded Memory Test in several memory access modes: single-threaded mode, two-threaded mode from two cores of the the physical core and from two cores of different physical cores (quad-core Intel Core 2 processors are actually two dual-core processors attached to the common FSB), and four-threaded mode from all four processor cores. In all cases, the size of a tested memory block was 64 MB (divided by the number of threads, for example, 32+32 MB in two-threaded mode). We measured the following parameters: memory bandwidth for reading (Read) and reading with software prefetch (Read PF), for simple writing (Write) and non-temporal store (Write NT). Our test results are published on the diagram. Real memory bandwidth reaches 6.7 GB/s (Read) and 7.3 GB/s (Read SP) in single-threaded mode. These results do not differ much from typical values of older generations of Intel Core 2 (in our previous review they amounted to 6.0-6.8 GB/s). Memory write bandwidth (Write) reaches 2.8 GB/s (a typical value for Intel platforms). However the most interesting bandwidth results are demonstrated in the non-temporal store mode, 8.3 GB/s (65% of the theoretical memory bandwidth). Considering that memory bandwidth in non-temporal store mode on Intel platforms (starting from Pentium 4 and including Core 2 processors) is limited to 2/3 of the theoretical FSB bandwidth, this result is a direct proof of high efficiency of the new 400 MHz FSB in Intel Core 2 Extreme QX9770 / Intel X48 platform. Let's have a look at bandwidth values for the two-threaded mode, represented by two options — memory access from two cores of the same physical core ("2 threads, same core") and two cores of the different physical cores ("2 threads, different cores"). You can see that two cores of the same physical processor core reach lower memory read bandwidth results than two cores of different physical cores. The reason is obvious: in the first case, two threads share a common 6-MB L2-Cache of the same physical core. In the second case, each thread uses 6 MB of L2-Cache of its physical core (that is, two threads utilize 12 MB of L2-Cache in total). Efficient data caching leads to higher memory bandwidth, although these results do not have to do with memory characteristics directly. Interestingly, the inverse effect is demonstrated by writing data — the two-threaded mode with two different physical cores shows lower bandwidth (2.62 GB/s) versus the single-thread mode (2.78 GB/s). It's much lower than memory bandwidth obtained when data are read by two cores of the same physical processor core (3.46 GB/s). It may have to do with syncing the content of L2 Caches. This process is much more efficient for a single shared L2 Cache of one physical processor core. What concerns results of four-threaded tests, when all the four cores access memory simultaneously, we can expect memory bandwidth values to fall in between results of the two-threaded mode with two cores of the same physical processor core and of different physical cores. Our tests prove this assumption. However, maximum real memory bandwidth values look suspicious. In case of two- and four-threaded access, they are not much higher than bandwidth values in the single-thread mode (maximum gain is below 25%), and they are still far from the theoretical FSB and memory bandwidth. The best result of real Read SP bandwidth in the two-threaded mode with different physical cores (9.14 GB/s) is only 71% of the theoretical maximum. This result has broken the record of the Intel Core 2 platform with a 266 MHz FSB (8.33 GB/s). But it fails to reach even theoretical bandwidth of a 333 MHz FSB and/or dual-channel DDR2-667 memory (10.67 GB/s). So the memory system of Intel Core 2 benefits little from its wide 400 MHz FSB. AMD Phenom X4 2.4 GHzNew processors from AMD have suffered architectural changes of the core (we are mostly interested in its bottleneck now — L1-L2 D-Cache bus) and of the integrated memory controller. Let's start with a brief examination of the L1-L2 D-Cache bus of the core (it will be reviewed in detail in the article devoted to the Phenom core architecture). Readings of the bus bandwidth are published below. 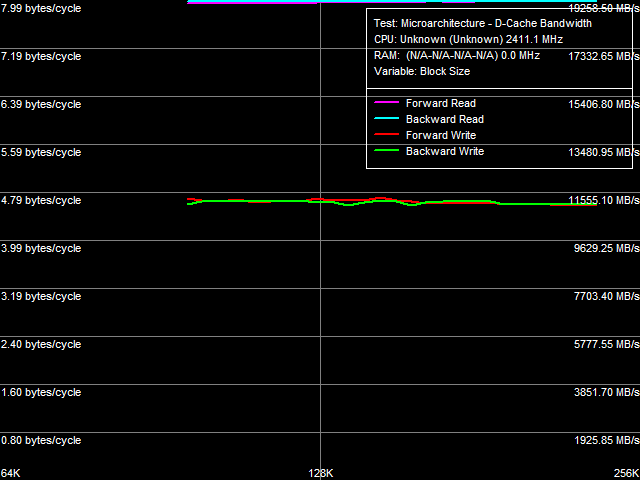 This bus has become much more efficient — its bandwidth reaches almost the maximum level (for a 128-bit bus) of 7.99 bytes/cycle (15.98 bytes/cycle taking into account the exclusive organization of D-Cache, where each cache line sent from L2 to L1 Cache pushes the least used cache line out from L1 and L2) for reading and approximately 4.7 (9.4) bytes/cycle for writing. Results of Athlon 64 X2 processors are noticeably lower - 4.75 (9.5) bytes/cycle for reading and 4.55 (9.1) bytes/cycle for writing. Bandwidth (expressed in GB/s, that is bound to CPU clock rate) of the L1-L2 D-Cache bus in Phenom processors is even more interesting. In our case (2.4 GHz core clock), it amounts to imposing 19.25 GB/s, which is noticeably higher than theoretical bandwidth of dual-channel DDR2-1066 memory (approximately 17.6 GB/s). Thus, we can say that the L1-L2 D-Cache bus in AMD Phenom processors has stopped acting as a bottleneck, providing a sufficient performance margin. It's only reasonable to assume that the increased efficiency of the D-Cache bus in AMD Phenom processors (compared to the D-Cache bus in Athlon 64 processors) has to do with its modified organization and preserved 128-bit capacity. To check it up, we used the data arrival test along the L1-L2 bus, its results are published in the picture. 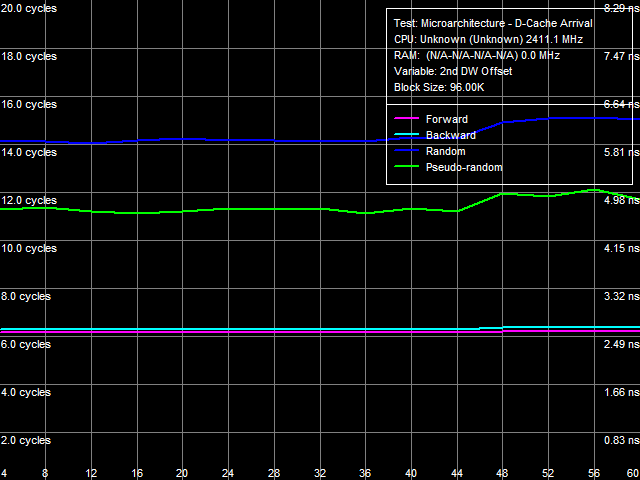 Complete quantitative interpretation of these results requires a more detailed examination of the Phenom core architecture (which will be reviewed in a separate article). As for now, we can only note that low results of total latency of two calls to a data line in L2-Cache during forward and backward walks and their almost complete insensitivity to the distance between data elements (abscissa on the graph) indicate hardware prefetch on the level of L2-Cache — that's a new feature in AMD processors. More sound latency values of two calls and higher sensitivity to the distance between data elements is demonstrated by pseudo-random and random access curves. They show a 1-cycle increase in latency, when the second element moves by 48 bytes (or longer) relative to the first element. It means that the L1-L2 D-Cache bus in Phenom processors can transfer up to 48 bytes per three cycles of L1-Cache access (its latency is still three cycles), that is the efficient bandwidth in one direction is 48/3 = 16 bytes/cycle (effective bit capacity — 128 bit). Efficient bandwidth of the L1-L2 D-Cache bus in Athlon 64 processors in one direction is just 8 bytes/cycle (effective bit capacity — 64 bit). So we can draw a conclusion that AMD Phenom processors have indeed a different organization of the L1-L2 D-Cache bus — it has evolved from a 64-bit bi-directional bus (in Athlon 64 processors) into a 128-bit unidirectional bus. And now let's examine the integrated memory controller in new AMD Phenom X4 processors. According to the documentation, it works with DDR2 (including unofficial DDR2-1066) and DDR3 memory. But presently available AMD Phenom X4 products support only DDR2. The integrated memory controller consists of two separate 64-bit controllers of DDR2 memory. So we can come up with three scenarios of its usage:
The single-channel mode is of little practical interest these days, as well as the single-channel mode of DDR2 memory in general. The so called ganged mode is a usual dual-channel mode — both 64-bit controllers are "populated" with identical memory modules (the same type, speed characteristics, capacity, and physical organization), and the effective memory bus width is 128 bit (64 bit per controller). The new unganged mode of the integrated memory controller is more interesting. It's something in between a dual-channel ganged mode and a single-channel mode. Each of 64-bit controllers can be populated with memory modules of one type (DDR2 or DDR3 for future models of processors, but not DDR2 and DDR3 together) and of the same speed (for example, DDR2-800), but of different capacity and/or physical organization. They work independently. Bit capacity of the memory bus is 64 bit — it's little different from the single-channel mode at first sight. It holds true for single-core access to memory. But when these restrictions are lifted (that is in case of a single-core or multi-core access to data in different memory segments), it's possible to address both 64-bit controllers simultaneously - we'll see it below in multi-threaded test results. Another major innovation of the integrated memory controller in AMD Phenom X4 processors is L3 D-Cache, which belongs to the integrated memory controller, so it's shared by all four independent processor cores with their own L1- and L2- caches (in our case — 64 KB and 512 KB, correspondingly). Let's proceed to memory tests. As the integrated memory controller in AMD Phenom X4 supports DDR2-800 and DDR2-1066, we've tested both memory types (DDR2-800 at 4-4-4-12 and DDR2-1066 at 5-5-5-15). Tests were run both in ganged and unganged modes, single-core access (single-threaded test) and quad-core access (multi-threaded test). As in previous tests, the size of a tested memory block is 64 MB (16+16+16+16 MB for four-threaded access). We measured memory bandwidth for plain reading (Read) and reading with software prefetch (Read PF), as well as for plain writing (Write) and writing data using non-temporal store (Write NT). In case of a single-threaded access to DDR2-800, the new Phenom X4 in the ganged mode demonstrates noticeably better results for "plain" reading than the equally clocked Athlon 64 X2 4800+ that took part in our previous review — 6.25 GB/s versus 3.90 GB/s. It's most likely the effect of the new, much more efficient L1-L2 cache bus of the processor. But the same does not hold true for memory bandwidth for reading data with software prefetch — it's quite low (there is a little gain versus memory bandwidth for "plain" reading — 7.33 GB/s versus 6.25 GB/s), and it's even lower than memory bandwidth for reading with software prefetch demonstrated by the Athlon 64 X2 (7.59 GB/s). Memory bandwidth for writing data (non-temporal store) is also noticeably lower than that of the Athlon 64 X2 (5.04 GB/s versus 6.90 GB/s). Thus, the new Phenom X4 in ganged mode demonstrates mixed results in case of single-threaded memory access. What concerns the unganged mode, memory read bandwidth of the integrated memory controller is natural. In this case (single-threaded access, one memory block), such operating mode of the controller is actually identical to the single-channel mode, which theoretical memory bandwidth is just 6.4 GB/s. Higher maximum real memory bandwidth for reading (6.89 GB/s) is caused by the effect of L3 Cache of the memory controller. Note that DDR2-1066 memory in our tests works at 480 MHz, that is in "DDR2-960" mode (memory controller clock rate - 2400 MHz, scaler = 5) with the theoretical bandwidth of 7.68 GB/s in the single-channel mode and 15.36 GB/s in the dual-channel mode. The first thing that arrests our attention in the results of single-threaded tests of DDR2-1066 memory is its bandwidth values for writing (non-temporal store), which are equal to memory bandwidth values obtained in this test with DDR2-800 memory. In other words, they do not depend on memory frequency, and they indicate a new restriction, which seems to exist in the processor core (the equally clocked Athlon 64 X2 4800+ demonstrates higher results in this case). But then memory bandwidth values for writing (ganged mode) grow higher: from 6.25 GB/s to 6.97 GB/s (by 11.5%) for plain reading and from 7.33 GB/s to 8.34 GB/s (by 13.8%) for reading with software prefetch. However it should be noted that the relative bandwidth gain is smaller than the memory frequency gain (from 400 MHz to 480 MHz, that is by 20%). The unganged mode again demonstrates memory bandwidth values typical of the single-channel mode with DDR2-1066 memory (higher owing to the effect of L3 Cache). Let's proceed to results of multi-threaded memory access tests (two-threaded for Athlon 64 X2, four-threaded for Phenom X4). DDR2-800 tests demonstrate apparent advantages of the new AMD Phenom X4 processor: real memory read bandwidth is about 10.4-10.8 GB/s (versus 6.8 GB/s on the Athlon 64 X2); similar results are obtained with software prefetch (10.9-11.0 GB/s), which again speaks of relatively low efficiency of the latter. But results of maximum real memory bandwidth, reaching 85% of the theoretical maximum for DDR2-800, speak of a very good implementation of the new integrated memory controller in Phenom X4 processors. Another important note - the unganged mode of the memory controller, which performed just like a single-channel mode in single-threaded tests, does not act like this anymore and demonstrates even better results in most tests. The reason is obvious: each core in the multi-threaded test addresses its own block of data, and each core is serviced by its own memory controller (for example, the first and the second core address the first controller, while the third and the fourth — the second controller). Advantages of the unganged mode with processor cores serviced individually by two independent 64-bit controllers over the ganged mode with a common 128-bit controller available to all CPU cores become even more apparent as we upgrade from DDR2-800 to DDR2-1066 (960). In this case, memory bandwidth for reading with software prefetch reaches an imposing value of 13.14 GB/s. It amounts to 85% of the theoretical bandwidth of dual-channel "DDR2-960" — a similar threshold was reached in DDR2-800 tests, regardless of a memory controller mode. But the maximum memory bandwidth of "DDR2-960" in the ganged mode is just 11.4 GB/s, that is approximately 74% of the theoretical maximum. ConclusionBoth new platforms from Intel and AMD can come close to revealing performance potential of DDR2-800 memory and its faster modifications to this or that degree. The 400 MHz FSB on the Intel Core 2 Extreme QX9770 / Intel X48 platform lifts the usual restriction on memory bandwidth, because bandwidth of this bus is now equal to the bandwidth of dual-channel DDR2-800 memory. However, we cannot say that it cardinally increased maximum memory bandwidth obtained in our tests — it was about 9.14 GB/s, that is just 71% of the theoretical maximum. Potential of faster DDR2 or especially DDR3 memory types will be revealed even to a lower degree on this platform, because the 400 MHz FSB in this case will act as a bottleneck for memory bandwidth. Despite some nuances (for example, relatively low efficiency of software prefetch, as well as limited memory bandwidth in the non-temporal store mode), the new AMD Phenom X4 platform manages to reveal performance potential of DDR2-800 and DDR2-1066 memory to a much more impressive degree. The increase demonstrated in real memory bandwidth by single-thread memory access is achieved by the new 128-bit unidirectional L1-L2 D-Cache bus of the processor. And a significant gain in memory bandwidth for multi-threaded access is caused by a more efficient implementation of the integrated memory controller. We should note the new unganged mode, when the integrated controller acts as two independent 64-bit controllers, which can service memory calls from different processor cores. According to our test results, this is actually a single-channel mode for single-threaded access to a single data block (and it demonstrates appropriate values of real memory bandwidth). However, it becomes much more efficient for multi-threaded access to several data blocks. It becomes even more efficient than the ganged mode of the memory controller, which can be considered a classic modification of the 128-bit dual-channel memory controller. Efficiency of the unganged mode is especially noticeable with fast memory (e.g. DDR2-1066), when it can reach memory bandwidth values of about 85% of theoretical maximum. We have never seen such a big step to revealing the full potential of DDR2-800 and DDR2-1066 memory. And we can now say that the memory controller integrated into AMD processors has finally managed to demonstrate its indisputable advantage over the traditional bus architecture of Intel platforms. Dmitri Besedin (dmitri_b@ixbt.com)
December 5, 2007 Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. |














