 |
||
|
||
| ||
|
||
|
||
| ||
Part 2: Video card's features, synthetic tests
 TABLE OF CONTENTS
The Same Candy in a New Wrapper and Probably Sweeter... ATI RADEON X1950 XTX (R580+). Part 1: Theoretical materialsThe company plans on manufacturing two video cards based on the updated GPU, they will be absolutely identical in frequencies and memory size.
This great price drop will lead to much lower prices for the old solutions: $399 for the X1900 XTX, $299 for the X1900 XT. Then there will appear the X1900 XT 256MB card for $279. Well... we haven't seen such a price war for a long time. I wonder what will be NVIDIA's response.
Video card
You can see well that the design suffered no changes compared to the X1900 XTX. Only the power supply unit was slightly modified (that's natural, as the card uses different memory chips with different voltages). In other respects, it's a complete copy, so there is no point in paying much attention to it. Especially as we have reviewed the X1900 XTX cards many times. Note that the card is equipped with very fast 0.9ns memory. But its operating frequency is reduced (1000 MHz instead of 1100 MHz).
We should mention that the card is equipped with a couple of DVI connectors. Dual link DVI allows to get resolutions higher than 1600x1200 via the digital connection.
Now let's review the cooling system.
    We have already noted in the beginning of the article that one of the new elements in this product is a new cooler. Look at the photo above. Experienced readers may have already noticed that the design was borrowed from Arctic Cooling — a famous manufacturer of noiseless and very efficient cooling devices. We don't know who manufactured this very cooler for the Canadian company, there are no stickers or labels. But it seems like Arctic Cooling. Of course, the design is new in some respects and we see it for the first time. Fan blades in the first place. Fans from this company usually have quite different blades. There are fewer of them, but they are larger and curved. Like in the previously reviewed Arctic cooler in the X1900 XT/XTX card from HIS, all the heatsinks are made of copper. The memory is cooled by its own passive heatsink, not by the main one. The retention module is a tad different from the usual X1900/X1800 one, so the new device cannot be installed in the accelerators of the previous generation. I already mentioned drawbacks of ATI's cooling system for such cards: dimensions (this video card takes up two slots because of the cooler) and startup noise. Besides, the fan starts howling as the thermal load increases. There is only one advantage, but it's big: the hot air is driven out of a PC case, which is very important for hot elements inside. And the card gets very hot!
Today we can see that the drawback became irrelevant due to the fan dimensions, the startup noise has become a thing of the past. No howling! That's WHAT REALLY MATTERS!
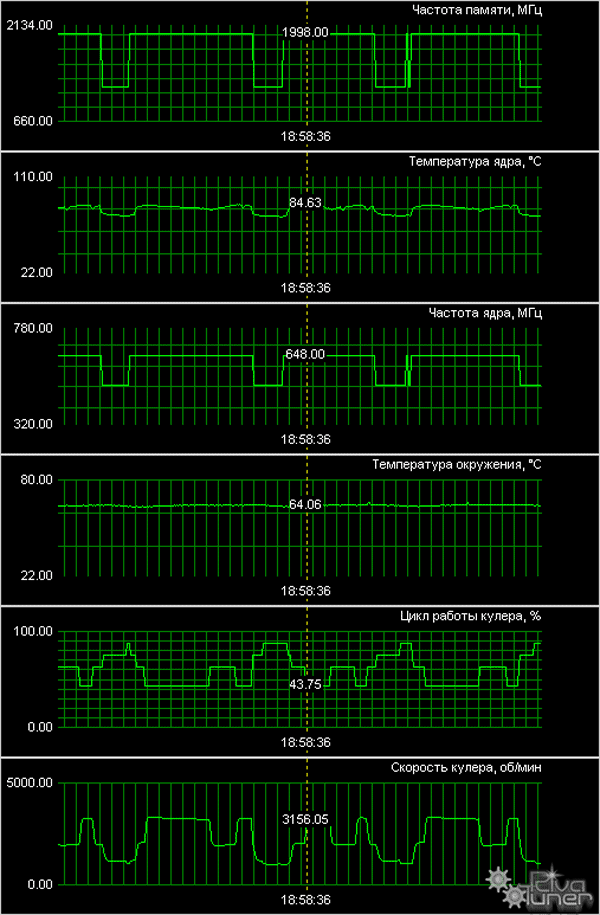 According to monitoring data, the heaviest load does not heat the core above 84°C, which is lower by 10°C-15°C than on the X1900 XTX card with a reference cooler. Fan speed grows, but there is still no noise. And the advantage (driving the hot air out of a PC case) remains. Of course, the memory gets hot as well and the heat from its heatsink remains inside a system unit. Not good.
Now have a look at the processor.
X1950 XTX — R580+ is manufactured on Week 21, 2006. That is somewhere in June or end of May, the chip is not even three months old Comparison with the X1900 XTX The chips are absolutely identical in exterior, of course. And the designations are similar. Installation and DriversTestbed configuration:
VSync is disabled. The quality in drivers is set to "Quality". We didn't disable optimizations. Here is the situation with overclocking: Our sample was overclocked to 704/2200 MHz.
Monitoring results show that RivaTuner (written by A.Nikolaychuk) has been updated :) and now supports this ATI product.
 Synthetic testsD3D RightMark Beta 4 (1050) and its description (used in our tests) are available at http://3d.rightmark.org We also used more complex tests of pixel shaders 2.0 and 3.0 — D3D RightMark Pixel Shading 2 and D3D RightMark Pixel Shading 3. Some of the tasks that appeared in these tests are already used in real applications, the others shall appear there in the nearest future. These test sets are in a beta testing stage and available for download from here. We ran our synthetic tests on the following cards:
Pixel Filling testThis test determines peak texel rate in FFP mode for various numbers of textures applied to a single pixel: 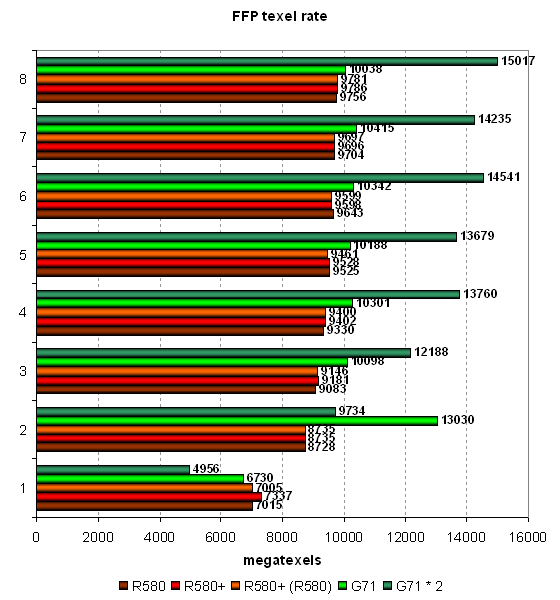 R580+ shows no changes versus R580. Higher results of the R580+ in the test with a single texture can be explained by the effect of the higher bandwidth - when the memory frequency is reduced, we can see parity with the R580. Having compared ATI and NVIDIA, we can see their parity in single-chip solutions. The only exception here is the optimized case with two textures per pixel, where NVIDIA's solution is noticeably faster than ATI's chips. In other cases, the cards are very close to each other, but the G71 still has a little advantage thanks to more texture units. But it's slightly outperformed in case of a single texture. That's curious, as the situation used to be reverse - the G70 was faster with a single texture, but was outperformed with more textures. The single-card SLI solution based on two G71 chips offers interesting results. The card fails the tests with one or two textures, being outperformed by the single G71 chip. But in the other cases it shoots forward. The more texture fetches, the more noticeable the difference. 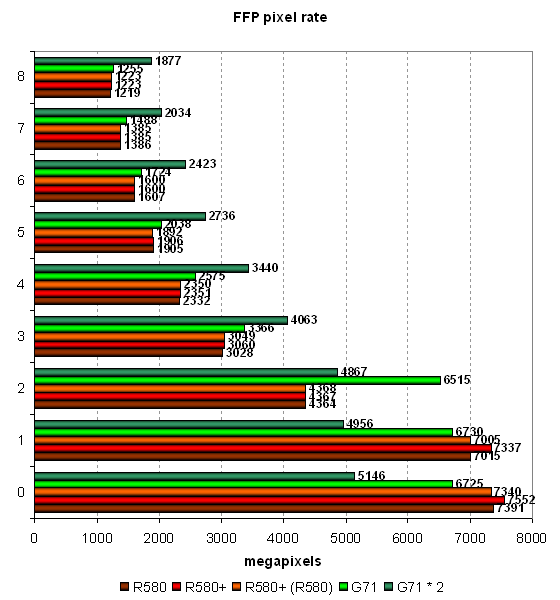 Our fillrate test demonstrates a similar picture, taking into account the number of pixels written into a frame buffer. In case of 0 and 1 texture, the R580+ is definitely at a small advantage due to the increased memory bandwidth. In the test with two textures, NVIDIA's chip is noticeably faster. The contenders are similar in other tests, but the G71 is slightly better. Dual-chip GeForce 7950 GX2 outperforms single-chip modifications only starting from three textures per pixel. Let's see the same task executed by pixel shader 2.0:  No significant changes, FFP and shaders work in the same way (perhaps, FFP is emulated by the effective shader) and demonstrate similar results. There is no clear-cut superiority of one product over the other, except for the dual-chip video card from NVIDIA. But it actually demonstrates strange sags in case of even texture numbers. Compare the results on this diagram with those on the previous one. While in case of 3, 5 and 7 textures the results are practically the same, the modes with 4, 6 and 8 textures reveal lower PS 2.0 fillrates versus FFT, approximately by 10%. There are evidently some bugs in SLI mode. Geometry Processing Speed testLet's start with the simplest vertex shader that determines maximum triangle bandwidth: 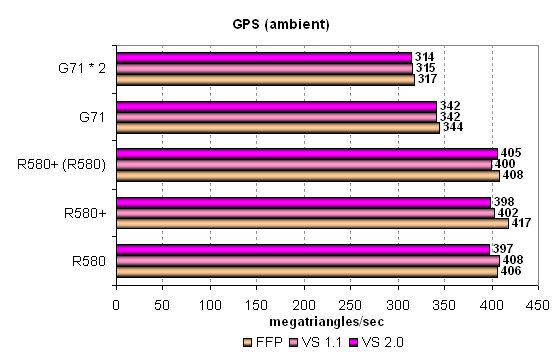 Even though the frequency of vertex units in NVIDIA solutions is at least no lower and the number of vertex units in chips from both companies is the same, ATI's GPUs noticeably outperform their competitors in maximum number of processed triangles per second. This value exceeds 400 millions for R580 and R580+, which is great and practically unobtainable in practice. Execution efficiency of this task is similar for all the chips in various modes. Peak performance differs little in FFP, VS 1.1 and VS 2.0. The difference exists somewhere, but it's small. The dual-chip SLI solution is inefficient in this test. We have an impression that only one chip is used. Let's see what happens under heavier conditions. The second diagram with GPS offers a more complex shader with a single light source: 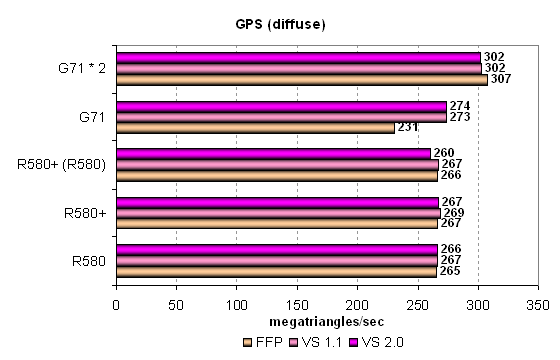 Here is a proof of the same vertex units in R580+ and R580 — no performance difference between them. In other respects, the situation is absolutely different. The single-chip solution from NVIDIA is still outperformed in FFP emulation mode, but in VS 1.1 and VS 2.0 modes it shoots forward. Note that these two modes are evidently more important that the former. The dual-chip card outperforms the competing solutions as well as its single-chip companion now. However, these differences are insignificant from the practical point of view, considering the reserve of pure geometry performance. Let's analyze a more complex geometry task that includes static and dynamic branching:  Hardware optimization of FFP emulation reveals itself with mixed-light sources, both NVIDIA and ATI offer it. That's another proof that the architecture of vertex units in R580+ has not been changed much versus R580. We again see contrary weak spots of vertex units from ATI and NVIDIA — dynamic branches result in significant performance drops in chips from the former company, static branches — in chips from the latter. It's funny — a shader with dynamic branches is executed by the G71 as fast as a shader with static branches is executed by R580/R580+. The contrary is also true: a shader with static branches is executed by G71 as fast as a shader with dynamic branches by R580/R580+. So ATI prefers static branches and NVIDIA - dynamic ones. What a story for game developers, it is enough to make you weep... It has no effect on real applications so far, most of them use vertex shaders without dynamic branching, and performance of geometry units is enormous in all solutions, far from being a bottleneck. On the whole, we can say that the G71 slightly outperforms the R580+ in geometric performance in the most complex test. The high clock frequency of vertex units has finally had its effect. The dual-chip card from NVIDIA outperforms single-chip solutions, but not much. Geometric performance is obviously not one of its advantages. Let's sum up what we have learnt in the geometry tests: there is no difference between R580+ and R580; the new product demonstrates the advantage of its higher memory bandwidth only in a limited number of cases. We noticed no architectural changes, there is still no vertex texture fetch and shaders with dynamic branches still show some performance drops. It's approximately on a par with the competing single-chip solution (sometimes it's insignificantly outperformed). But the dual-chip NVIDIA card is usually beyond competition, it's outperformed by all card only in case of the simplest shader. Pixel Shaders TestThe first group of pixel shaders to be analyzed is simple enough for modern GPUs. It includes various versions of pixel programs of relatively low complexity: 1.1, 1.4 and 2.0. 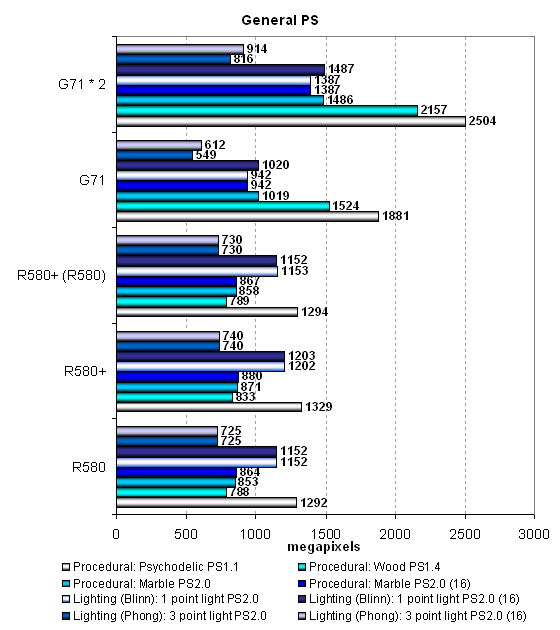 There is a little difference between R580+ and R580 in some of these tests. Judging from the "R580+ (R520)" result (R580+ chip operating with GDDR4 memory at R580 frequencies), higher results are demonstrated only due to the increased memory bandwidth. We don't see any results that would speak of architectural changes in the R580+. What concerns competition, NVIDIA solutions are victorious with the simplest programs 1.x, as usual. They are much faster. But in case of more complex Shaders 2.0, R580 and R580+ take the lead. The advantage is small, but it still exists. Shaders with reduced precision of calculations are executed faster by the G71 and expectedly make no sense in case of the R580. NVIDIA's architecture gains advantage when a number of temporal registers and their precision is reduced. But ATI's architecture is not so critical to the volume of temporal data. This approach seems potentially better for future complex shaders. On the whole, if we have a look at more important tests with pixel shaders 2.x and forget about shaders 1.x, ATI's solution seems better. Even in favorable conditions, the R580+ is outperformed by the dual-GPU card from NVIDIA. That's only natural — two chips, even if they operate at lower frequencies, are much better than a single chip. GeForce 7950 GX2 card demonstrated good results in pixel shader tests — it always breaks away from the other models. We found one oddity that has to do with low-precision calculations. While Lighting (Phong) and Lighting (Blinn) tests benefit from forcing 16-bit calculations (even if not much), the Procedural: Marble test demonstrates a contrary situation - a shader with lower-precision calculations is processed slower than with full precision. Peculiarities of a shader recompiler or something else? Let's have a look at the results in more complex pixel programs: 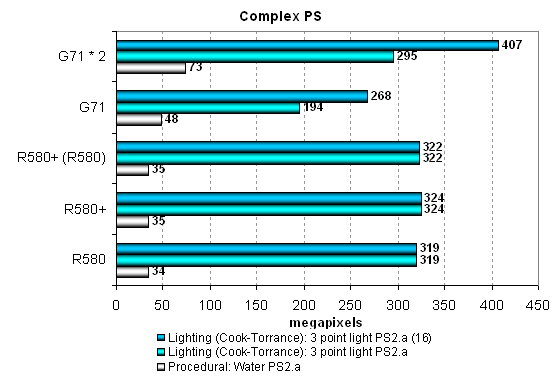 That's another proof that there is no difference between R580+ and R580. Architecturally, it's just the same chip, but supporting faster memory, which can be a potential advantage under heavy load on video memory. NVIDIA chips benefit from 16-bit precision in the Cook-Torrance test as well, but only the dual-chip modification manages to outperform ATI solutions. The single-chip G71 is outperformed by the R580+ even in case of FP16. If we have a look at the results of Procedural: Water test, we'll see different approaches of the two GPU companies again. A shader program with procedural water visualization actively uses texture fetch (dependent access, high nesting levels). This shader is executed faster on NVIDIA chips, which have more texture units. The reverse difference in performance is no less than in the previous case with the Cook-Torrance shader. A developer has to make a choice how to implement his or her algorithms, as one chip benefits from lots of math, while the other one prefers texture fetching. Different architectures again make developers write individual shader code. New Pixel Shaders TestsThese new tests were introduced not long ago and we'll try to focus on them in our future reviews. They can be downloaded as part of D3D RightMark Beta. We plan on gradually giving up our early synthetic tests with some old shader versions. We'll try to focus on Shaders 2.x and 3.0 (written in HLSL) in the first place. Performance of old versions can be tested in real applications, where they have been used for a long time already. And synthetic tests, which should look into future, must be constantly updated to keep up with the times. Our new tests are divided into two categories. We'll start with simple Shaders 2.0. There are two new tests with effects that are already implemented in modern 3D applications:
We'll test both shaders in two modifications: the first one specializes in math, the other — in texture sampling. We'll also check the results for low (FP16) and normal (FP24 or FP32) calculation precision. Let's analyze the math-intensive versions: 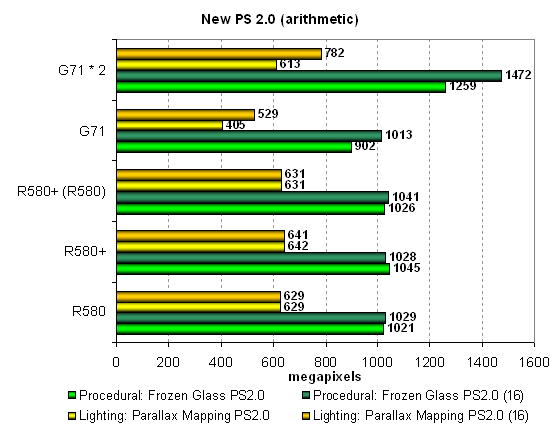 First of all, we confirm our assumption about no changes in the R580+ versus the R580, that's our main task for today. Secondly, we can see that ATI's solutions always outperform the single-chip NVIDIA G71, especially in the Parallax Mapping test. Performance of G71 and dual-chip G71 depends much on calculation precision. In case of FP16, NVIDIA's solution is nearly on a par with the R580+, which is potentially better prepared for such tasks. On the other hand, the R580 and the R580+ are so fast that they outperform the dual-chip G71 in the parallax mapping test, if we don't take into account the results of the latter with reduced calculation precision! By the way, the dual-chip SLI solution from NVIDIA is always faster than a single-chip solution in these tests. Let's analyze texture-priority modifications of the same tests: 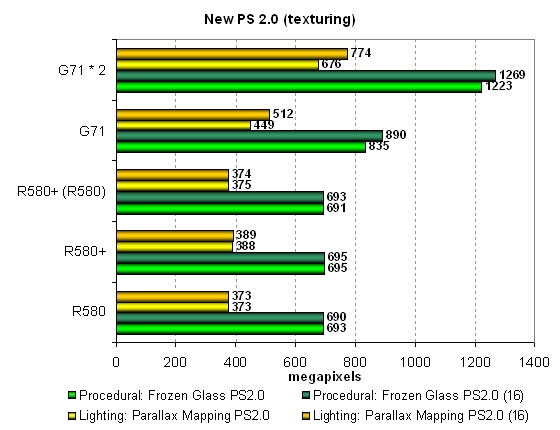 The picture changes completely here, as performance is limited by texture units (ATI — 16, NVIDIA — 24). NVIDIA looks like a winner in this case. But have a look at the figures — a single math-intensive shader is executed faster even by the G71. And the second algorithm is executed at the similar rate. What's the point in focusing on texturing, if there is nearly no performance difference? We can see that it all depends on programmers' decision again — if they lay stress on math, ATI will be victorious, if on texturing — NVIDIA will win. We cannot say for sure about the future, but the existing tests must show the current situation in the next part of the article. In other respects, we can say that the R580+ corroborates its parity with the R580. And the dual-G71 is always faster than a single chip, even if not by 1.5-2 times. And now what concerns the results of two more tests — with pixel shaders 3.0, our most complex synthetic test. We developed two shader programs within the D3D RightMark project. This time they are very long, complex, with lots of branches:
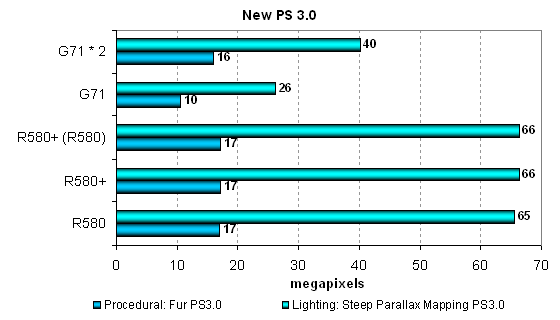 That's a worthy load, have a look at the performance results and compare them with previous tests, even not the simplest ones! That happens on the most robust video cards. The architecture of R580 and R580+ is evidently better suited for such heaviest conditions. They provide the most efficient execution of pixel shaders 3.0 with lots of branches. Performance difference in the Fur shader amounts to more than 1.5 times. Even the dual-G71 solution did not manage to catch up with a single R580+. In the second case, steep parallax mapping, the difference is even more pronounced, more than two-fold for the single chip solution from NVIDIA and more than 1.5-fold for the dual-chip card. Conclusions on the tests with "heavy" pixel shaders: a lot of pixel processors in the R580 and the R580+ flex their muscles in all tests, including complex SM 2.0 programs. That's definitely a reserve for the future, for an architecture to be even more efficient for DirectX 10. One important question remains: will this reserve for the future be used in R580-based video cards? We have some doubts because moderns games have no such complex shaders with branching so far, which would bring even the most powerful chips to their knees. Such applications may fail to appear, when the current architecture is still used. Few texture units in the chip may also play against the R580, while many modern applications depend much on texturing performance. We'll analyze the situation in real applications and see how modern games act on different architectures. Our complex synthetic tests reveal that the advantage of R580+ is irrefutable in case of a certain approach to programming pixel shaders. Hidden Surface Removal TestPeak efficiency of culling invisible triangles (without applying textures/with texturing), depending on geometry complexity: 
 As we can see, the R580+ demonstrates no significant changes from the R580 in practical tests. But the HSR efficiency is lower for the R580+. This is most likely a measurement error, as it was on a par with the previous chip at the R580 frequencies. HyperZ buffers might have been increased, but we saw nothing like performance gains. But even in this case the hierarchical HSR from ATI is much more efficient than a single-level HSR in NVIDIA solutions. Especially it concerns scenes of high and average complexity, all the chips are similar in relatively simple scenes. Interestingly, NVIDIA GPUs close the gap in the tests with texturing. In case of simple scenes, they even catch up with ATI chips — that's the effect of more texture processors. Let's have a look at the absolute results in HSR tests: 
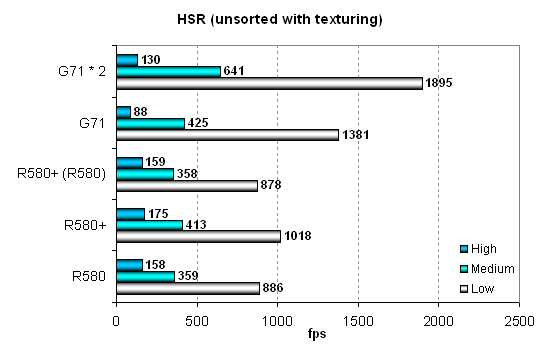 That's probably the first time when we see the R580+ significantly outperform the R580 in synthetic tests. The effect of its increased video memory frequency and bandwidth is rather strong. Performance of the new chip at the R580 frequencies matches performance of the previous solution. We didn't notice the effect of increased memory latencies. If we compare solutions from ATI and NVIDIA, we can see that 24 texture processors in the G71 win in two texturing tests out of three, even though they are less efficient. In a scene with complex geometry, the G71 is outperformed due to low HSR efficiency. The dual-chip card is a winner, though the performance gain is far from what we expected compared to the single-chip G71. Point Sprites test
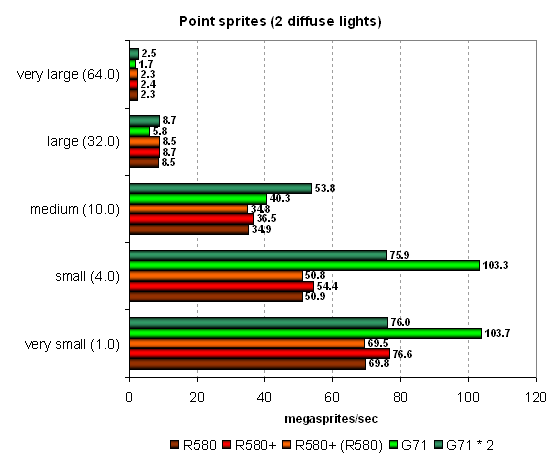 Point sprites are used in just a few real applications. Let's analyze their operation on various video chips. Results of the previous tests are confirmed — NVIDIA's chip outperforms ATI's solutions with small sprites due to more efficient operations with a frame buffer. But as sprites grow larger and lighting gets more complex, the G71 starts lagging behind. The dual-chip card behaves interestingly in this test — it's outperformed by the single-GPU card in case of small sprites, but it shoots forward in more complex conditions with large sprites. The R580+ again benefits from its more efficient GDDR4 video memory, winning several percents from its predecessor in easy conditions. Conclusions on the synthetic tests
The Same Candy in a New Wrapper and Probably Sweeter... ATI RADEON X1950 XTX (R580+). Part 3: Game tests (performance)
Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||





















