 |
||
|
||
| ||
|
||
|
||
| ||
Part 2: Video Card's Features, Synthetic Tests
 TABLE OF CONTENTS
ATI Technologies' Counter-Offensive is Still in Progress: RADEON X1900 XTX/XT (R580): Part 1: Theoretical materials
ATI Technologies' Counter-Offensive is Still in Progress: RADEON X1900 XTX/XT (R580): Part 2: Video Card's Features and Synthetic Tests
So, we proceed.
All the details about peculiarities of the R580 architecture (RADEON X1900) are already reviewed by Alexander Medvedev in Part I of this article. So, ATI plans on manufacturing two cards on this GPU.
Differences between these two cards are obviously minimal. Such a great difference in prices has to do with marketing reasons only, in order to subdue the demand for 1900 XTX cards from the very beginning with higher prices. Our test lab got a top representative of the series - the 1900 XTX (reference card) and the X1900 XT (a PowerColor product, though it's also a reference card :). These very cards will be reviewed here. Considering that both cards are COMPLETELY IDENTICAL in exterior (including the smallest details!), I will show only a reference card. Video card
You can see well that the design actually suffered no changes versus the X1800 XT, only a power supply unit was slightly modified (it's quite natural as the card has a new core with different memory chips, hence different voltages). In other respects, it's a complete copy of the reference design. So there is no point in elaborating on this issue, especially as we have reviewed the X1800 XT many times. It should be noted the card is equipped with excessively fast 1.1ns memory. 1.26ns is quite enough for 1550 MHz (X1800 XT). I guess 1.1ns memory will be used only in engineering samples, production-line cards will use 1.26ns memory. Besides, memory voltage is reduced relative to the standard value, which is actually brought to nought by overclocking.
We should also mention that the card is equipped with a couple of DVI connectors. Moreover, they are Dual link DVI, which allow resolutions higher than 1600x1200 via a digital channel (owners of huge LCD monitors have already complained of this limitation several times).
Now let's review the cooling system.
    Yep, that's the same cooler. As one of my colleagues put it, "coolers start to resemble refrigerators". There are two disadvantages: dimensions (this video card takes up two slots because of the cooler) and startup noise. There is only one major advantage: the hot air is driven out of a PC case, which is very important for hot elements inside. And the card gets very hot! I repeat that the howling can be heard only at startup. Then the rotational speed drops and the cooler becomes almost noiseless. Only under a very heavy load, when the temperature rises above 80°C, the rotational speed grows so that you may hear some low noise.
Now have a look at the processor.
X1900 XTX — R580 is manufactured on Week 45, 2005, it's somewhere in November; that is the chip is not even three months old Comparison with the X1800 XT As we can see, the die is noticeably larger. But it was to be expected, as the number of pixel pipelines has grown threefold, so the number of ALUs has grown just as much, plus enlarged caches, etc. 400 mln transistors versus 310. Considering that the die operates at a higher frequency than in the R520, you can imagine its power consumption! I have already mentioned above that the card gets very hot.
Unlike the reference card, the product from PowerColor comes shipped in a box and has a bundle:
  < I repeat, in other respects it's just a copy of the previously reviewed X1900 XTX.
Installation and DriversTestbed configurations:
VSync is disabled. In order to evaluate efficiency of the new core, we carried out some tests with the X1900 XTX at the frequencies reduced to the X1800 XT level - 625/1500 MHz.
Now let's have a look at monitoring (X1900 XTX):
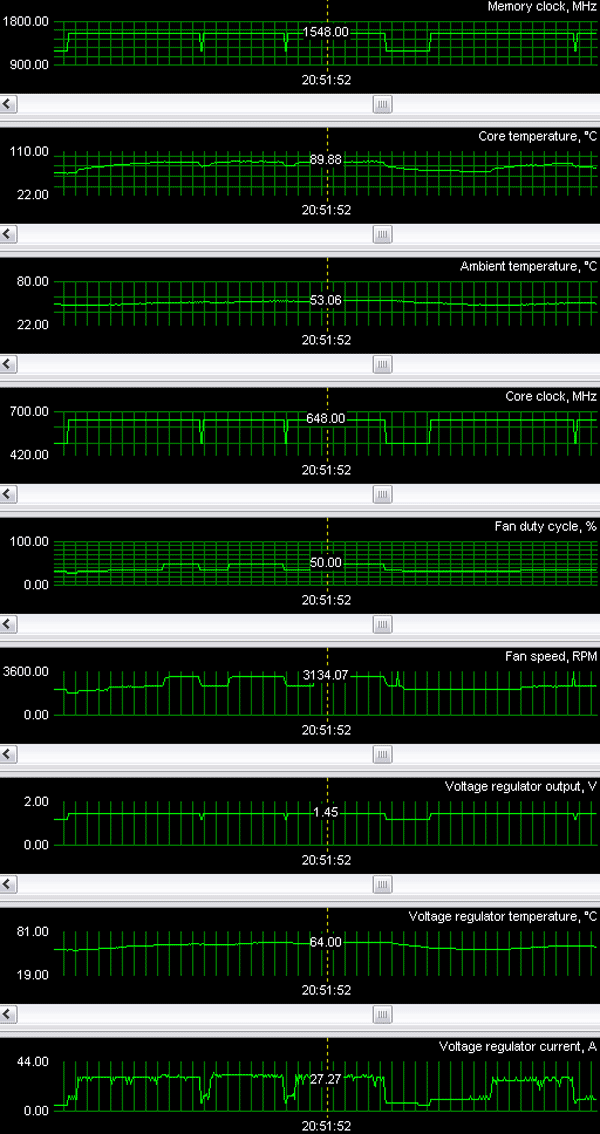 To our joy, Alexei Nikolaychuk updated the latest version of RivaTuner and now it works correctly with the new card and copes well with its monitoring. We can see that the maximum core temperature is higher compared to the X1800 XT - it's nearly 90°C (versus 80°C in the X1800 XT). The maximum load current may reach 40A. This and the 1.45V voltage give us the power consumption of the core of 58 Watts (60 Watts to make it even). Considering that the memory operates at a lower voltage than the standard value, its power consumption is not that high, but it's still about 50 Watts. So the new card certainly consumes more than 100 Watts. Unfortunately, reduced memory voltage does not allow to overclock memory! Such fast memory is wasted, the card does not allow to use it to the full extent! By the way, the core itself overclocks badly either, 685 MHz maximum: to all appearances, designers have squeezed maximum from the 0.09-micron process technology. We can still raise the core voltage - we already saw it in the X1800 XT PE from Sapphire (we have recently reviewed this card).
Remember that a monitor should be connected to the lower jack, if you intend to use a X1xxx card with a TV and a monitor simultaneously.
Synthetic tests
D3D RightMark Beta 4 (1050) that we used and its description are available at http://3d.rightmark.org
We also used new tests for Pixel Shaders 2.0 (more complex and adequate) - D3D RightMark Pixel Shading 2 and D3D RightMark Pixel Shading 3, oriented to the future. Now these tests are in beta testing and can be downloaded here:
We carried out our tests with the following cards:
Pixel Filling test
Peak texelrate, FFP mode, various numbers of textures applied to a single pixel:
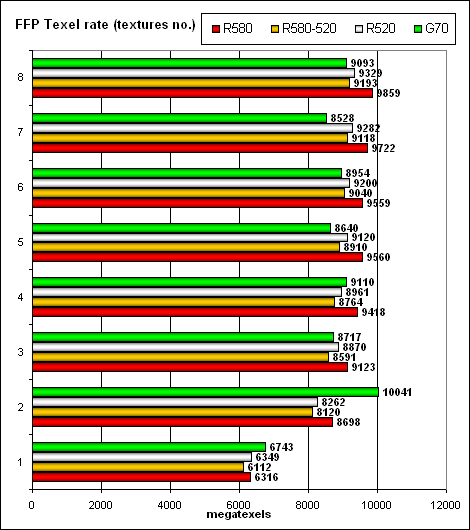
So, the increased core frequency in the new card on G70 allows us to speak of parity. The only exception is an optimized case with two textures per pixel, where NVIDIA shoots forward. In other cases the cards offer identical performance, according to their frequencies and numbers of texture units. The higher frequency of the core and memory gives the R580 a little monotonous advantage in case of many textures. But on the other hand, the G70 is a tad faster in case of a single texture – that is it handles a frame buffer a tad more efficiently. Interestingly, the R520 samples textures a tad faster than the R580 at the same frequency – probably the latter has some penalties that have to do with the increased number of pixel processors, which are actually useless in this test, but which still have to be manipulated. These penalties are noticeable, constant, but so small that we have nothing to worry about – that is the architecture scales well and this feature has been there from the very beginning. However, ATI already dealt with such a ratio of pixel processors and texture units (48:16) in Xenos (xbox 360 chip). They must have finetuned interaction procedures. 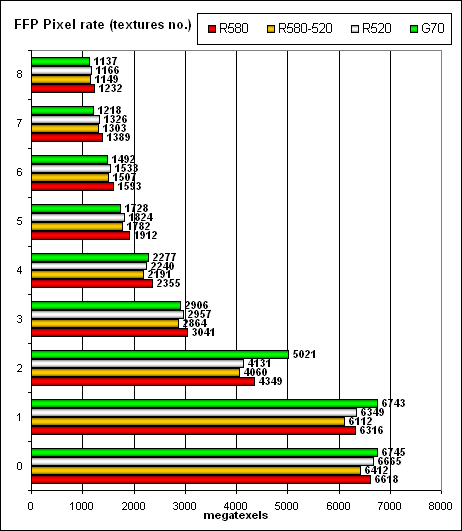 The same situation, but in terms of pixels written to a frame buffer. In peak cases – 0, 1, and 2 textures. NVIDIA is a tad faster, in other cases it's slightly outperformed.
Let's run the same test with PS 2.0:
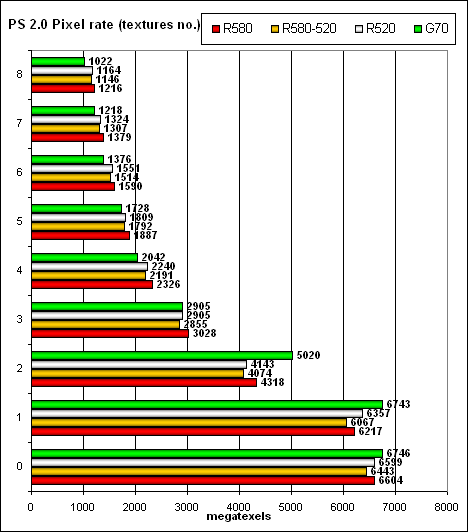 So we can establish a fact that nothing has changed — FFP as well as shaders operate in the same way (from the point of view of hardware, FFP is emulated by a shader) and demonstrate the same results. We see no domination, the cards demonstrate identical performance. Geometry Processing Speed test
The simplest shader — maximum bandwidth in terms of triangles:
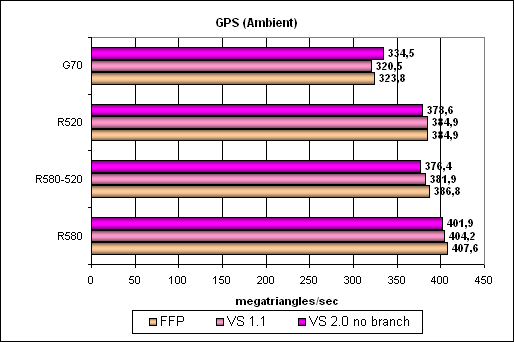 Everything agrees with the frequencies and the number of vertex units. The results are impressive – 400 mln triangles per second are more than enough. Interestingly, the G70 executes this test in VS 2 mode more efficiently than in VS 1.1 mode. The R580 and R520 do it vice versa. The difference is not large, but we'll see what'll happen in more complex tests.
A more complex shader — a single mixed-light source:
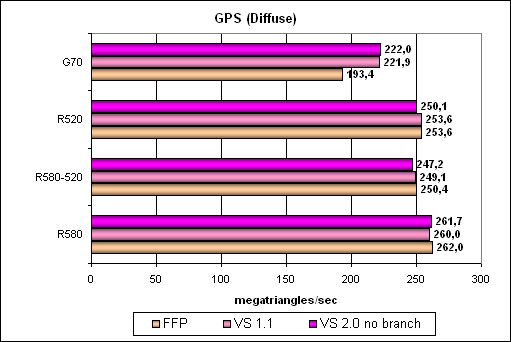
The same situation, NVIDIA gets slower in FFP emulation mode, but still insignificantly, considering the great performance reserve in terms of triangles. Let's complicate the task:
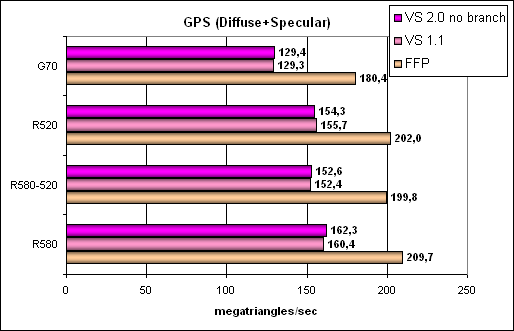 Aha, this mixed-light source reveals hardware optimization of FFP emulation – both NVIDIA and ATI have it in this generation. The cards again fair according to their frequencies. We can see that the vertex architecture of R580 suffered no noticeable changes versus the R520 (see R580-520 and R520).
A more difficult task, including branching:
 Here we can see that branching is a weak spot of ATI's vertex unit – while ATI defeats NVIDIA in any other tests, its performance drops significantly in case of dynamic branching. But the G70 prefers them to static branches. That's the effect of different vertex unit organizations – ATI traces back to the R420 or even earlier, its vertex units do not support texture sampling (it's a fine aspect that actually discredits full SM3 support – we already discussed this issue in our interview with ATI and NVIDIA – links) and are less advanced architecturally in terms of branching. But it has no effect on real applications, as most of them use Vertex Shaders 2.0 without dynamic branching. As we can see, performance of these units in both competitors is huge. The situation will change later with the appearance of WGF 2 cards, which vertex units must cope efficiently with branching and texture sampling. Conclusions on geometry tests: the situation hasn't changed much, the difference between the R580 and the R520 is conditioned by the core frequency only. We have seen no architectural innovations. It's an evident parity or a little ATI's advantage depending on a given task. Except for no texture sampling and glitches in compiling and executing Shaders 3.0, vertex units from ATI are praiseworthy — everything is up to the mark! Pixel Shaders Test
The first group of shaders, which is rather simple to execute in real time, 1.1, 1.4, and 2.0:
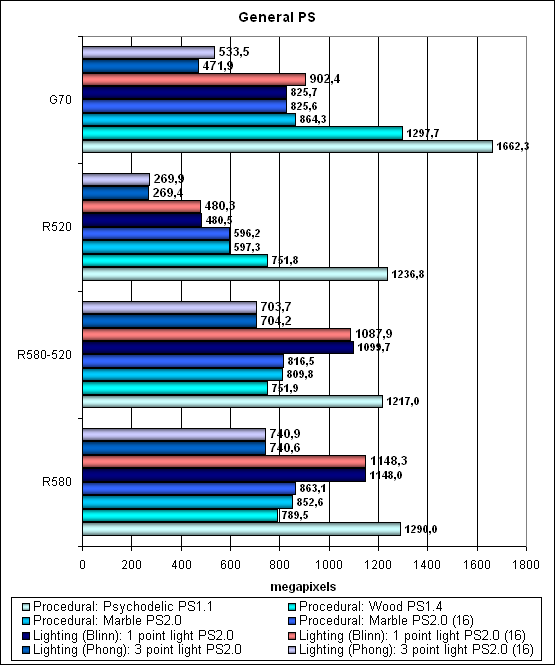 As before, NVIDIA leads in the simplest PS1.X shaders. The R580 leads in more complex Shaders 2.0, its advantage is evident, though it's not twofold. It's followed by R580 operating at the frequency of R520 and G70. The R520 takes the last place, it noticeably lags behind. We can see that the R520 situation gets much better – now NVIDIA is defeated in Shaders 2.0. Compared to the R520, performance of some shaders (executed by the new chip) has grown by 1.5-2 times – quite justified, considering how many transistors were required to add 32 pixel processors. That's without increasing the number of texture units, computations only. Shaders with reduced precision (FP16) are executed faster by the G70 and bring no benefits to the R580 – it's OK, that's different architectures to you. While the G70 benefits from the reduction of temporal registers or their precision, the R5XX just has a sufficient number of these units and is not that critical to the volume of temporal data. Thus, its architecture is potentially better at scaling. It's better adapted to future computations, complex shaders, and such distant prospects as arbitrary memory access from shaders. We should congratulate ATI – a great deposit into the future. So, if we look into the future and forget about Shaders 1.X, ATI's solution does not look unjustified. On the contrary, it provides a noticeable advantage over the G70. However, we don't know yet how the G71 will fair. Besides, don't forget that the G70 is less complex in the number of transistors. Anyway, unlike the RV530, the 3:1 concept is in its prime here. It has demonstrated its expedience in terms of pixel shaders.
Let's proceed to longer shaders:
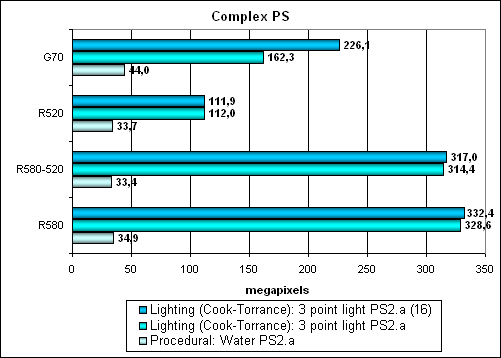 NVIDIA again gets advantage here from 16-bit precision (don't forget that intensive intermediate calculations of this precision may result in noticeable deterioration of rendering quality and the current de facto standard and requirement to all future APIs is internal calculations in FP32 format). The R580 is nearly three times as fast as the R520 in the complex computing model. It noticeably outperforms NVIDIA, especially if we don't take FP16 into account. That's laudable. Interestingly, we can also see a small difference between FP16 here – that's probably an effect of too many intermediate computations. But this difference is hardly noticeable and not critical. In its turn, a procedural water shader intensively uses texture access, depending on large nesting levels. So it's executed faster by NVIDIA, which has more texture units. Here is the dilemma we mentioned earlier – different algorithms may be implemented in different ways, one chip will favour computation priority, the other - texture access priority. Some things can be calculated, others can be looked up in a prearranged table. Unfortunately, architectures differ very much now. Each of them will have its own optimal shaders, which will pose new difficulties to programmers, especially to those who thoroughly optimize performance of their shaders. Anyway, the R580 works much better with pixel shaders than the R520. The new chip can be really called a shader king. It noticeably outperforms the G70 in any calculations that are not limited by texture sampling. Let's proceed to Our new shader testsWe are going to gradually switch to new tests, which are available for download (see above) as part of D3D RightMark Beta. In future we shall give up earlier versions of synthetic tests and focus on HLSL shaders for SM 2.0 and 3.0. Earlier shaders can be tested in existing applications, while synthetic tests for current and future loads should be adjusted to the spirit of the times (we have done that). Let's start with simpler PS 2.0 shaders. There are two new tests with topical effects:
Both shaders are tested in two modifications: fully oriented to computations and to texture sampling. Besides, we also check the results for FP16 and FP32 precision.
So, computation-intensive modification of the task:
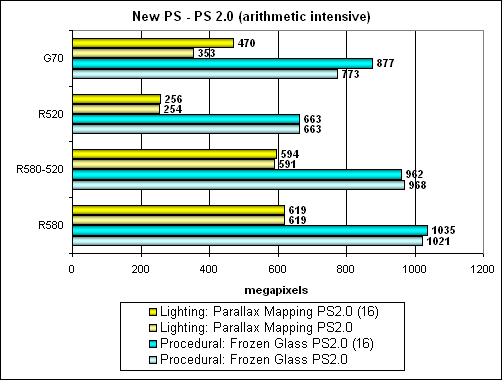
As we can see, the R580 always remains on the first place (it's especially good at parallax mapping), it's followed by the G70, the last place is left for the R520. And again, G70 performance noticeably depends on precision. Now the same tests will be run in their texture sampling modification:
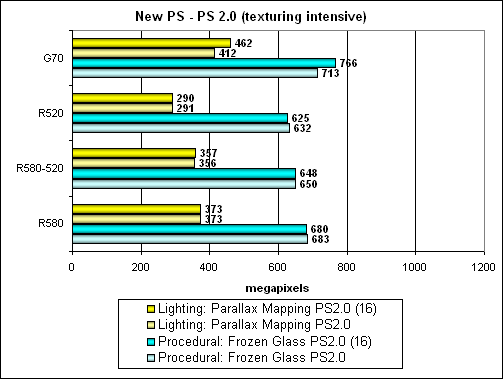 As we can see, advantage of the R580 over the R520 has practically no effect as performance is limited by texture units, 16 in both cases. Thus NVIDIA formally looks like a winner in this case. But as it's still a tad faster in the first scenario with computations (in a procedural test) and slightly slower in the second scenario (in a parallax mapping test), programmers will most likely prefer the first shader modifications and not create two different shaders for different cards. ATI will win in this situation, unless programmers decide for some reason (I wonder why?) to create a texture-priority shader in order to equalize G70 and R580. In this case ATI has implemented all the 32 new pixel processors for nothing. It's an interesting situation – too much depends on a context and programmers' preferences. We'll see what ways they will choose in their applications. But don't forget about a possible situation when the choice is already made – for example, the game is already released. Then the case may go against the R580. Just because programmers didn't know about its features and high performance in computing rather than texture sampling.
Here is another new test – Pixel Shaders 3.0:
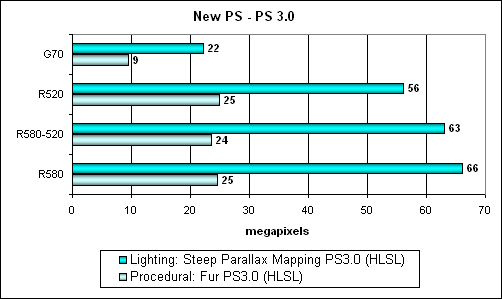 Two shaders, long, complex, with intensive branching:
These shaders are uncompromisable – just have a look at their execution speed even on such high-performance cards. 16-bit precision is out of the question - maximum precision level. The layout of forces is also obvious – the new ATI architecture efficiently executes SM 3 shaders. It has more than a twofold advantage. Bravo! The company made a good start, it should just use it for the WGF 2 platform. And then the shaders will indeed look like their counterparts from movies and high-performance offline rendering. Conclusions: an increased number of pixel processors in the R580 puts up a good performance in all shader tests starting from PS 2.0. That's a good start for the future – for complex cinematic shaders and an excellent odd for state-of-the-art games. But will this potential be revealed – the number of texture units is still 16? In our gaming tests we shall see how modern applications feel about the 3:1 ratio, chosen by ATI. Our tortuous synthetic tests showed that the advantage of the R580 is unchallenged in case of a correct approach to writing effects. But one should know about it, in order to choose this approach. Will it be done and was it already done in existing games? We'll see. HSR test
Peak efficiency (with and without textures) depending on geometry complexity:
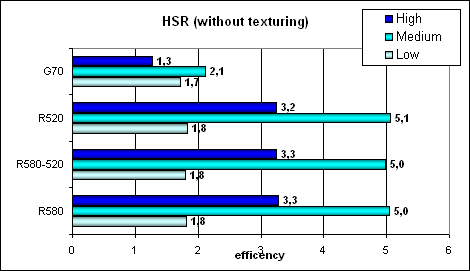
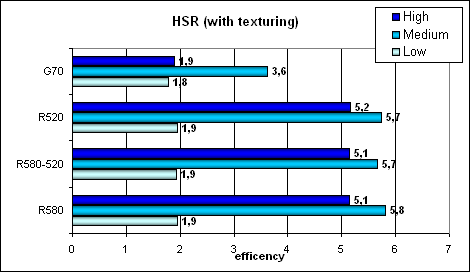 We can see no changes in practical tests versus the R520. Perhaps the on-chip buffer was indeed enlarged, but it was compensated by the increased core frequency. Anyway, ATI's hierarchic HSR looks better than a single-level one from NVIDIA, especially in high and medium complexity scenes. NVIDIA rehabilitates itself a little in texturing – the effect of a more efficient (for simple fill) integration of texture units into a pixel pipeline.
Absolute values for comparison:
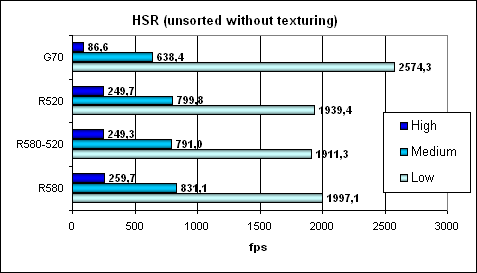
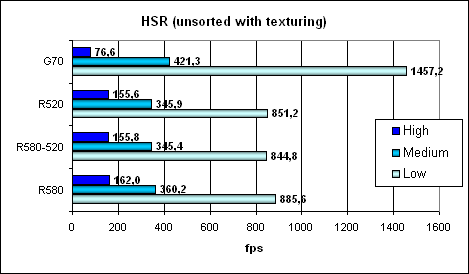 Here we can see that despite the lower efficiency, 24 texture units in the G70 may show their teeth. However, as soon as it comes to computations and shaders (not just simple filling of a chaotic scene), the advantage quickly sputters out. What concerns the efficiency of HSR unit, we have already noted that it's lower in the G70. Point Sprites test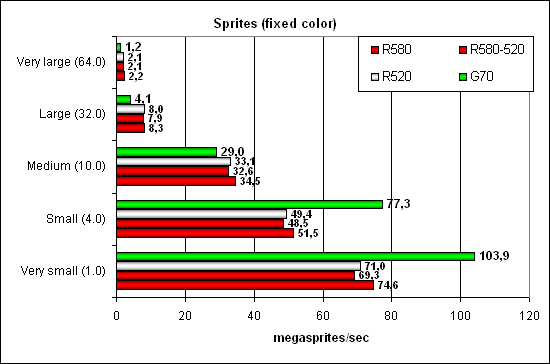
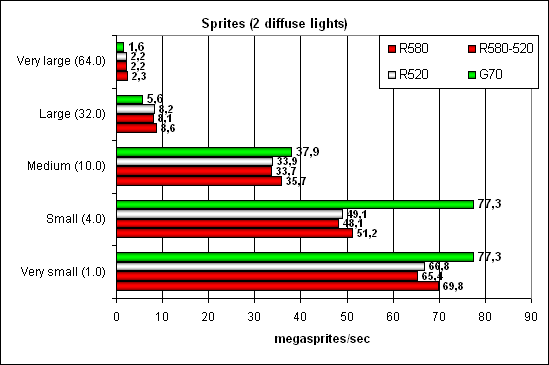 Everything is as usual – NVIDIA is leading in small sprites thanks to more efficient frame buffer operations. As their size and illumination complexity grow, it starts to lose, not fatally though. Conclusions on the synthetic tests
The most important part about game tests is to follow. Stay with us! ATI Technologies' Counter-Offensive is Still in Progress: RADEON X1900 XTX/XT (R580). Part 3: Game tests (performance)
Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||





















