 |
||
|
||
| ||
|
||
|
||
| ||
On May 24 in high hot spring ATI officials conducted a conference in Moscow devoted to the technology to be reviewed in this article, details on the new Xbox 360, and other no less useful things. That was great, I'd like to thank Nikolai Radovski and other representatives of the company for useful information and competent answers to our questions! ATI CrossFire is the official name of the Canadian answer to NVIDIA SLI, which was rumoured about in technical forums all over Internet even six months ago. Are there any differences? Certainly. Are there advantages? To all appearances, the answer is yes, quite significant at that. Soon we shall publish our tests and analysis of the quality aspects, but now we are going to review theoretical and architectural aspects and to try and forecast tendencies and consequences. General architecture of CrossFire.The main objective of this technology is to organize rendering team-work for two video accelerators. This architecture must be not only effective (high efficiency, low costs of additional schemes, availability for common users and enthusiasts), but also convenient to use (compatibility with the existing programs and even with existing hardware solutions, limpidity, simplicity, and reliability). There are a lot of requirements, but running a few paragraphs forward I want to congratulate ATI with the thorough and well thought-out approach to resolving these tasks. So, we are offered the following architecture: 
Several accelerators (consumer modification comprises two cards) render their own parts of the image and output it via TDMS transmitters in the conventional DVI format. Then the data goes to the black box (red box in the diagram) called Composing Engine. This device actually combines rendering results to obtain the aggregate image. This red box outputs the standard DVI signal, but this time it's a final frame assembled from two portions of data calculated by both VPUs. To resolve synchronization problems, Composing Engine contains its own buffer storage that allows this device to accumulate data asynchronously and then assemble and output the resulting frame (when both accelerators are ready). That is there is no need is accurate synchronization of VPU operations. There are only two conditions: each VPU must know what part of the data to render and each VPU must complete transferring rendered data into this "red box", Composing Engine. After that the frame will be transferred to the output device in DVI format or (if we need an analog signal) to the external graphics DAC, which converts the DVI stream into the standard analog VGA signal. And now the most vital question – how are VPUs going to share the data to be calculated? A little theory: The main interaction algorithms of accelerators.We can easily single out three main algorithms, that are used nowadays for this purpose in various consumer and professional solutions:
So, let's sum up pros and cons of the above methods:
Which one was chosen by ATI specialists? Stay with us, we shall dwell on this issue later. And now let's proceed to the hardware specifics of CrossFire. How did ATI implemented the above mentioned "red box" in practice? Like this: CrossFire specifics.So, we have two video cards installed in a system with two graphics PCI-Express slots. A regular ATI card and a special ATI card with CrossFire technology: 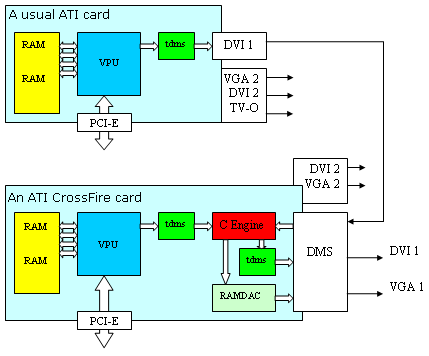
That's the reason why we entitled the article "Asymmetric repartee" ;-) It turns out that ATI engineers decided to place the above mentioned "red box" (C Engine on the diagram) on a single card, the main one, and to transfer data to it from the second card via the regular external DVI connector. Thus they designed a solution that is compatible with the existing cards, manufactured before CrossFire! Isn't it just great – if you already have a PCI-Express video card from ATI with DVI out, all you need to get a super system is to buy an additional special CrossFire card, connect the DVI out of the old card with the new card by a special bundled cable, and here you go. The new card will output an image, assembled by Composing Engine from the results calculated by both cards, in DVI or analog VGA format. The CrossFire card is equipped with a special connector, which resembles DVI but has more pins. It's marked as DMS on the diagram. This connector is used to apply a DVI signal from the first video card, it's also used to output DVI and analog VGA of the resulting image, assembled by the red box. Besides, the initial card still has a vacant second output (DVI+VGA or just VGA), as well as TV-Out, and the CrossFire card also has the second DVI+VGA. All these outs, not used to render the image, can certainly be used for additional monitors and other standard applications at "peace-time", when no games are played. But they cannot output the image, calculated by both accelerators in CrossFire mode – it is applied only to the DMS connector. And now the most interesting question. Attention, please. What algorithm did ATI choose for its "red box" to split the image? The correct answer is any of the three described above! The red box on a CrossFire card is not a special chip with a hardcoded operating algorithm, but a small all-purpose chip with a programmable gate array. This small chip contains a flexibly configured circuit of logical elements and buffer storage to keep intermediate results, its algorithm is dictated by drivers that upload a corresponding scheme of relationships. ATI currently implemented all the three methods, described above. But it doesn't mean that there will be no improved or hybrid load distributions in future. All we'll ever need is to update drivers. I again cannot help congratulating ATI engineers on this smart solution – their approach reduced considerably design and introduction costs of CrossFire, it allowed to choose an optimal mode (among the available ones) for each application in terms of efficiency and thus secured our investments into the multi-chip solution from whims of games and applications. Thus, when you use CrossFire:
The current limitations of this technology:

Prospects of this technology:
Prices, dates, forecastAnd now several words about down-to-earth specifics. Prices and availability for a start: 
CrossFire cards will already appear in stores in late June, early July. ATI provides the following performance data on solutions with two video cards, CrossFire X850 XT compared to NVIDIA SLI 6800 Ultra (attention: two cards are used in both cases): 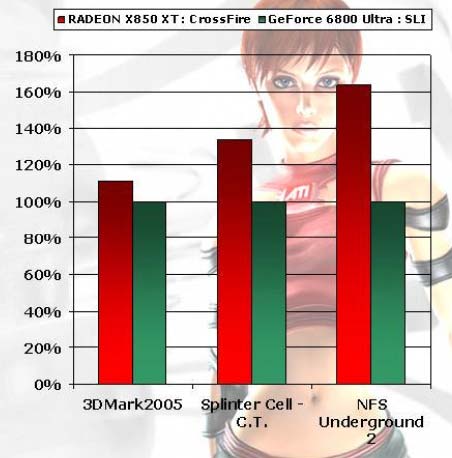 1600x1200 (4xAA 8xAF) We shall abstain from comments until we get our own results on performance and quality of this technology. So far, we can note that SLI only operates with a limited (greatly limited) number of games and thus it's heavily outscored by CrossFire here. It also requires purchasing two new video cards, which is also not good compared to CrossFire. ATI's technology can be (potentially) used by almost a million of all X800 and X850 series cards owners, no need to sell your old card. Two most vital questions: will ATI manage to retain this technological leadership? The next generation of NVIDIA products may add the best discoveries of the canadian experts to their armory, this way or another. Why is this technology called CrossFire – isn't it a reference to the Chrysler model of the same name ;-) It goes without saying that much will depend on the price/performance (in certain games) ratio. It will also be up to problems with image quality and compatibility. We are going to analyze all these aspects in the nearest future, but now let's draw a preliminary conclusion: ATI engineers designed an advantageous, flexible, and convenient architecture of multi-chip rendering, intended for end users and games. The prospects of CrossFire look better than those of NVIDIA SLI on paper. And the architectural solution can be (and should be) admitted as more refined and better thought-out. Its assets include compatibility with existing video cards and all applications, as well as a flexible choice of a collaboration mode. Of course, this technology is intended for a narrow segment of enthusiasts and it will not yield super profits. But we shouldn't forget that the total leadership, which can be brought by CrossFire, will certainly have a positive effect on the mainstream ATI sales. And technological leadership in such a sphere is no less tangible and precious contribution into the company image. Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. |


















