 |
||
|
||
| ||
|
||
|
||
| ||
On the one hand, the time in IT industry passes so fast that you might just miss a new product or technology, but on the other hand let's remember for how many years we awaited a new processor core from Intel? Not anything remade (added increased FSB, implemented virtual multiprocessing (or rather just admitted that the desktop model has it similar to server solution)), but something brand new? For two years! And even slightly longer. And all that time hotheads were discussing the favourite theme: what will it be, this new core? Forecasts ranged from the complete anathema to NetBurst and Banias's accession to desktop throne. The truth turns out to be more prosaic: the new core is a frank successor of Northwood. Of course, it has some architectural innovations, but we can't see anything revolutionary in it. So, emotionally Prescott can be estimated differently: some will praise Intel for consistency and purposefulness, while some, vice versa, will complain about the absence of fresh ideas. But emotions are personal, therefore let's address to the facts. TheoryKey core changes (Prescott vs. Northwood)First, here's a table summarizing the most considerable hardware differences between Prescott and Northwood.
I'll just add that the new core contains 125 million transistors (vs. Northwood's 55 million), has 112mm² crystal size (vs. Northwood's 146/131mm², depending on revision). As you can see, having increased the number of transistors by ~2.3 due to the new process, Intel still managed to reduce the crystal size. Not very considerably though - "just" by 1.3 (1.2) times. As for the strained silicon technology, it's rather simple. To increase the distance between silicon atoms, silicon is placed to a substrate which has larger atom distance, it has to "strain", according to the pattern enforced:
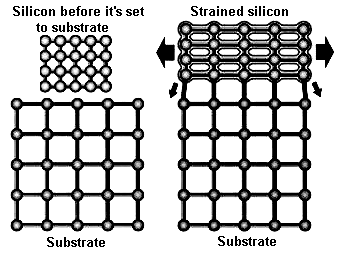 And this little figure will help you understand why it's easier for electrons
to pass through the strained silicon: 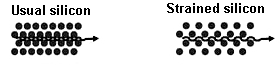 As you can see, the path of electron gets shorter this way. And now let's look at some more interesting differences - in the core logic. But first, it will be useful to revise the primary peculiarities of NetBurst architecture. Some prehistoryOne of the key differences implemented in NetBurst Intel considers the unique separation of x86 code decoding into internal core instructions (uops) and their execution procedures. By the way, this approach caused lots of discussions regarding the correctness of Pentium 4 pipeline stage calculations: from the classic (pre-NetBurst) point of view, decoder stages should be included into the common list. But Intel's official data on Pentium 4 pipeline offers information only about the Execution Unit pipeline stages, excluding the decoder. Still this objectively reflects the architecture peculiarity. So, if you need to obtain the classic pipeline length, just take the official value and add the decoder part. Therefore, the essential of NetBurst is an asynchronous core in which instruction decoder operates independently on the Execution Unit. From Intel's point of view, the clock speed, considerably higher than those of rivals, can be achieved only in asynchronous model, because otherwise expenses to decoder and Execution Unit synchronization grow proportionally to the clock speed. This is exactly the reason to use Execution Trace Cache in NetBurst (instead of L1 Instructions Cache for normal x86 code) that stores already decoded instructions (uops). The Trace is actually a sequence of uops. Besides, in this historical digression we would like to finally destroy myths
related to simplified wording which states that ALU of Pentium 4 operates
at "doubled clock speed". This is both truth, and lie. But
let's first look at Pentium 4 (Prescott) flowchart: 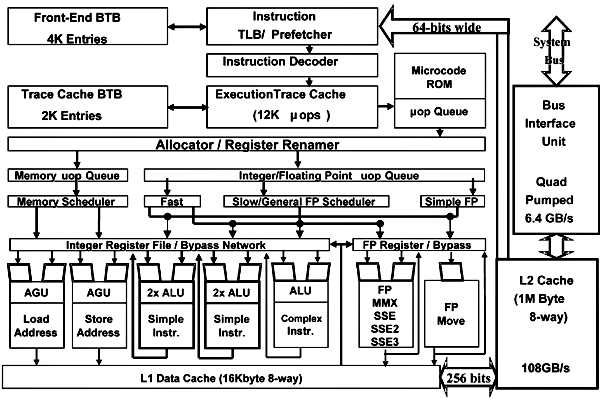 As you can see, ALU contains several parts, including Load / Store, Complex Instructions, Simple Instructions. So, the doubled speed (0.5 clock/operation) is used to process only instructions supported by Simple Instructions. Vice versa, ALU's Complex Instructions can spend up to 4 clocks per instruction. That's actually the end of NetBurst "internals" revision, and we move to the new features of the latest NetBurst core - Prescott. Increased pipeline lengthIt can hardly be called an "improvement", as all of you know that the longer pipeline is, the higher is the cost of a misprediction, and the lower the average application performance is. However, it seems Intel couldn't find another way to increase core overclocking potential, so they had to use the unpopular, but tried one. As a result Prescott's pipeline became 11 stages longer that makes the total of 31. Frankly speaking, we knowingly moved this "pleasant" news to the beginning. And actually, all other innovations are required to minimize the negative effect of the single aforementioned change. :) Improved branch predictionIn general, they "tuned" the transition prediction for cycles. If before backward transitions have been considered cycles, now it analyzes transition length and tries to determine whether it's a cycle or not. They also found out that for branches with certain types of conditional transitions the standard mechanism is usually useless independently on their direction and length. So now it's not used in such cases. However, besides theoretical research, Intel also used pure empiricism, i.e. merely monitored the efficiency of branch prediction on certain algorithms. To do this they analyzed the amount of mispredictions obtained in SPECint_base2000 and changed the algorithms to minimize their numbers. The documents provide the following values (# of mispredictions for 100 instructions):
ALU accelerationALU now features a special shift/rotate unit that now enables to execute these operations in the double-speed ALU (in Northwood they were processed in the ALU Complex Instructions unit and required more clocks). Besides, they sped up the integer multiply operation previously executed in the FPU. The new core has a dedicated block for it. Besides, there's a number of smaller improvements to speed up the FPU (and MMX) processing. But we better test it further in the article, in the test part. Memory subsystemOf course, one the new core advantages is the doubled L1 data cache of 16KB and doubled L2 cache of 1MB. However, there's another interesting peculiarity: the core now features special logic to monitor for page faults in software prefetch instructions. This enables software prefetch to also prefetch page table entries, i.e. prefetch now doesn't stop at a loaded page, but simultaneously updates memory pages in DTLB. Those experienced will notice that Intel carefully watches for programmer comments though doesn't publicly recants about every newly found performance negating factor. New SSE3 instructionsExcept everything else, Prescott now supports 13 new instructions called, according to the tradition, SSE3. They include x87 to integer, complex arithmetic, 1 video encoding, new vertex array instructions, and also 2 thread sync instruction (a clear consequence of Hyper-Threading). Actually there's a new review of SSE3 coming soon, so let's not pause on it here for long. And now enough theories and specs, "let's try to take off" with all these innovations :). TestsTestbed and softwareTestbed
  Pentium 4 2.8AGHz Prescott The only Prescott with 533MHz FSB and w/o Hyper-Threading   Pentium 4 3.2EGHz Prescott 800MHz FSB Hyper-Threading   Pentium 4 3.4GHz Northwood Just another "Northwood" Software and drivers
Finishing the description I'd like to explain how we selected processors for tests. On the one hand, it would be wrong to exclude AMD processors at all, as they are Intel's main competing products. On the other hand, to compare in this article two Pentium 4 generations with processors from another maker would mean a mess, not a correct comparison. So we decided to compromise in this first Prescott-related material. First, to exclude any "extreme" models like Pentium 4 eXtreme Edition and Athlon 64 FX; second, to include only one but fast representative of the alternate platform - Athlon 64 3400+. But frankly speaking the results of the latter are rather optional here. In this material we are mostly interested in comparing the new Intel's core with the previous. If you want information how Prescott stands near its rival, it's in the diagrams. We guess comments are not required here, you will see it yourself. Knowing the performance of Prescott and Northwood operating at the same clock speed and the performance ratio of Northwood and top AMD processors (we repeatedly reviewed this issue), you know enough to make any required conclusions yourself. Besides, I'd like to explain two columns for Prescott 3.2GHz in diagrams. As
you all know, when a new core is released, makers start the mishmash
around BIOS updates, microcode updates, etc. So, it seemed logical to
us to use the official Prescott-ready motherboards that we have to the
full to secure against possible defects of any of our certain boards.
However you will see that in most cases the new processor behaved the
same. 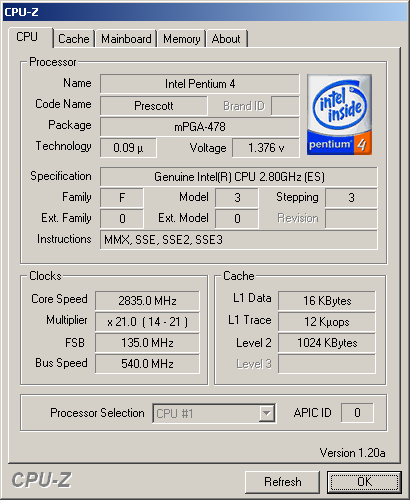 CPU-Z recognizes all Prescott 2.8AGHz features correctly, including SSE3 and 533MHz FSB 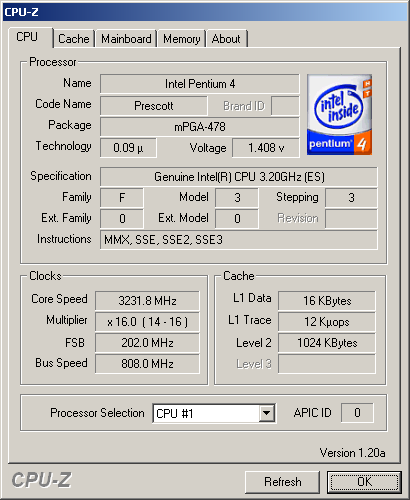 Of course, it didn't make any mistakes with Prescott 3.2EGHz CPU RightMark low-levelFirst, we decided to test the new core in two modes, traditionally the best and the worst for Pentium 4 - SSE/SSE2 and MMX/FPU. Let's start with Math Solving. Well, the results are disappointing. The new core is slower that the old. Moreover, it lags with MMX/FPU even more that with SSE/SSE2. The first conclusion is: if anything was "tinkered" in FPU, our CPU RightMark clearly uses other instructions. And what about the rendering? Let's first look at the rendering module in a single-thread and dual-thread modes at max. performance (SSE/SSE2). The picture is rather interesting: if there's one thread used, Prescott has minimal advantage and higher-clock Northwood easily outruns it. But as soon as we enable Hyper-Threading, Prescott abruptly rushes forward leaving all other participants behind. It seems they did something to the core except expanding the instruction range to optimize parallel thread processing. Now let's look at the same processors with MMX/FPU. It's absolutely identical. If you compare it with the previous, you will see that our thoroughness justifies itself: if we considered only the best (dual-thread) result, we would make a wrong conclusion that Prescott is faster in the instruction processing even with MMX/FPU. Now we can clearly see that the performance grew only due to optimized usage of virtual CPU resources. Real application testsBefore we look at the results in this section, let me explain something again. The thing is that 3.4GHz Pentium 4 Prescott is still unavailable for us, so what you can see on our diagrams as "Virtual" Prescott 3.4GHz is just an approximation of Prescott 3.2GHz results calculated under the ideal conditions of performance growth proportional to the clock rate. You can say this is too clumsy and it would be more correct to overclock our Prescott 3.2GHz sample with FSB or just draw the approximation curve using the three points: Prescott 2.8GHz -> 3.0GHz -> 3.2GHz. Well, it would be more correct. But just note how the general picture is affected by this "ideal" Prescott 3.4GHz (the real one can either be the same or slower). Risking to make an unauthorized disclosure, we can say it straight: it doesn't almost affect it. It's clearly seen where Prescott wins, and where it loses, it loses even being idealized at 3.4GHz. Graphics testsNorthwood 3.4GHz (performing slightly better than Northwood 3.2GHz) and Prescott 2.8GHz (the absence of Hyper-Threading made it an outsider at once) produce the most predictable results. Prescott 3.2GHz is trying to catch up the similar Northwood, but still can't make it. And our "virtual Prescott 3.4GHz", in its turn couldn't outrun the real Northwood 3.4GHz that is also natural. On the other hand, we can say that all processors except Prescott 2.8GHz perform almost identical. It's hardly an argument to upgrade to the Prescott, but it's also not an argument against its purchase in the new system. Lightwave shows us similar situation, just Prescott lags even more. Here we should remember that Lightwave was "honed" for Pentium 4 very thoroughly. We can assume that exactly because of this it turned out so sensible to smallest architecture changes. Besides, we must mark that for the first time Athlon 64 3400+ demonstrates not the best, but rather good result. In other reviews we've already mentioned that Photoshop is very cache-loving, and this is further indicated by the Prescott results. Media encodingAs we test the new (or significantly modified) architecture, any application might become a surprise for us. Actually, now quantity is even more important than quality because we have to gather as much data as possible about the behavior of old applications (not optimized for Prescott) with the new core. If we speak of the popular LAME, it turns out that Prescott shows completely new (but still worse) results comparing to those indicated by Northwood. Well... this happens :) Ogg Encoder shows almost the same: Prescott loses much to all other processes despite the doubled L1 and L2 caches. We guess we should blame the longer pipeline at the same Trace Cache capacity. Even the DivX codec bent for NetBurst disliked the new core. Not very much, but disliked. Still there's a certain hope for SSE3 - DivX developers just love various optimizations (at least, according to the announcement), so chances are high that the only and unique instruction intended for video encoding will find its place in the future release of this codec.
Oh! The first victory. Getting back to the software selection, we can state that Windows Media Video 9 has a good Hyper-Threading support. And the low-level tests indicated that virtual CPUs provide are more efficient in the new core. It seems it's the first positive result achieved due to the qualitative, not quantitative Prescott innovation. In all situations before it survived only due to the doubled cache. That's a very, very interesting result. Mainconcept MPEG Encoder that we blamed for incorrect operation with Hyper-Threading at MPEG1 encoding now adequately works with virtual processors emulated by Prescott, not Northwood! Maybe we shouldn't blame the programmers, but there's was just a processor core "bug" that resulted in incorrect thread parallelization? Looking at Prescott, we guess this assumption has a right to live. On the other hand Prescott 2.8AGHz performed good even without Hyper-Threading. It seems we are on the threshold of an interesting discovery: can it be that Prescott's Hyper-Threading optimization is just to give it enough cache (that Northwood lacked)?! And again we are pleased with the new core: Mainconcept MPEG Encoder not only lost its MPEG1 encoding bug, but also showed significantly better performance in MPEG2 encoding. Considering the previous test results, we can assuredly state that it's the reason of optimized Hyper-Threading (remembering the supposed essential of this optimization). What's the most interesting, the processor didn't require any special SSE3 instructions, and nicely performed anyway (there can't be SSE3 support in this encoder version as it's rather old). And Canopus ProCoder just didn't notice any changes. There's actually slight performance difference that benefits Prescott. But still it's very slight. Considering ProCoder is cache-loving as well, we can even say that all this doubled cache was used to compensate other core drawbacks. It just pulled Prescott on the level of Northwood, not higher. ArchivingAs usually we tested 7-Zip both with and without multithreading support. Still we didn't achieve the expected effect in this application and didn't notice that Prescott's multithreading provided stronger effect that Northwood's. There was not much difference between the cores, in general. It seems that we observed the aforementioned effect: all that Prescott's doubled L1 Data and L2 could do was to compensate its longer pipeline. It's one of the few tests that indicates the board difference. But in general it shows almost the same: same-clock Prescott and Northwood perform even. Those of you pessimist will say it's bad, while optimist will state it might be worse. :) GamesThe picture is similar in all three games, there's no need to comment it much: Prescott is slightly slower. Summarizing the resultsWell, drawing conclusions from tests above we can say the following: Prescott is in general slower than Northwood. Sometimes it's compensated by larger cache pulling the performance even to the older core. And if the application is sensitive to L2 cache, Prescott can even win. Besides, it shows better Hyper-Threading efficiency (but it seems the reason is doubled L2 again). Respectively, if an application can use both advantages - large cache and virtual multiprocessing, the benefit is considerable. But in general Prescott performs about the same as Northwood (and even worse - with the older software). This is no revolution. But read more below. As for the Prescott 2.8AGHz with 533MHz FSB and without Hyper-Threading, it's totally clear. First, it's a good way for Intel to make something of models that just were not able to work in the "real Prescott" mode. It's such a Celeron-like Prescott (though there should be an official Celeron on this core as well). Second, the absence of Hyper-Threading most likely means that Intel just doesn't want to implement HT into an older bus. As you can see, the only 533MHz FSB + HT was only the first 3.06GHz Pentium 4. But this is clear as well, as at that moment there just wasn't 800MHz FSB processors. So, may Intel excuse us for this wording, Pentium 4 2.8AGHz is just "something resembling Prescott". Just another inexpensive (otherwise no one would buy it), but high-clock Pentium 4. And its core is totally unimportant. Frankly speaking we thought over excluding it from this material as well, but then decided to give it a chance to sparkle once. Comparing similar-clock Prescott and Northwood cores we can clearly see that without Hyper-Threading Prescott 2.8GHz can't even compete with Pentium 4 2.8C (800MHz FSB + HT) in average performance. VersionsVersions exactly, not the conclusions. This article is far too ambiguous. It would be much simpler just to analyze the diagrams and make the obvious deduction: if the new isn't faster than the old, it's worse. So, just write it off. However, the simplest answer is not always the most correct, so we decided to touch analytics and consider Prescott release on the historical and marketing background. It turned out that there are actually several answers for the "What's the sense for Intel in releasing Prescott-based Pentium 4?" question, each logically reasoned. Version #1. Big MistakeAnd why not? Once upon a time there was Intel which decided to develop a processor core designed not for the maximum efficiency (given efficiency is ratio of performance to clock speed), but for easy scalability. If our 2000MHz lose to their 1000MHz, let's just boost it to 4GHz and leave everyone behind. And it's actually logical from the purely engineering angle. Experienced users are interested in performance more than in megahertz, anyway. What's the difference for them how it's achieved? The main thing is to make scalability as good as expected. But at 3.4GHz they stumbled upon problems with the aforementioned characteristic and had to invent a new core with even lower efficiency, unclear clock speed potential, etc. If you remember, this is just a version. That we look thoroughly at considering the real facts. The fact arguing for this version is the growth of Pentium 4 clock speed in 2003. Well, just 200MHz is a too small value regarding such "clock-loving" NetBurst architecture. Still... as you know, it's not good to separate one fact from other. Was it sensible to actively boost Pentium 4 clock speed last year? Seems like it wasn't... That time the main rival was working on other issues - it had new architecture, new core, and had to establish the volume production, provide corresponding chipsets, motherboards, software. So, one of the answers to the "Why did Pentium 4 clock speed (and performance) grow so slow in 2003?" is rather simple: there was no sense. Just no one to catch up or outrun. Still we can't yet answer the main question about the overclocking potential of the new core. At the moment there are no obvious facts confirming Prescott's good scalability. However, there's nothing arguing against it as well. There are 3.4 GHz versions of both Prescott and Northwood announced. The latter might become the last CPU on its core (still there's nothing official to prove it). And Prescott's initial 3.4GHz instead of 3.8GHz or 4.0GHz is clear as well: there's no need to hurry. Summing it up, the Big Mistake version has a right to live. But if Prescott's clock speed (or rather performance) grows quickly, it will become groundless at once. Version#2. Intermediate CoreIt's not a secret that sometimes a manufacturer needs to release a solution that's rather ordinary itself (and in another situation unimportant), but still required to help advance other solutions announced alongside or afterwards. Such a solution was Pentium 4 Willamette hardly good and fast, but designating the fact of transition to the new core. At the end of its life cycle it replaced the "intermediate" Socket 423 with a long-term Socket 478. What if Prescott is intended for the same role? As you all know, alongside Grantsdale-P we should see another Pentium 4 socket (Socket T / Socket 775 / LGA775) that will initially be used for Prescott CPUs exactly. And only after time passes Pentium 4 "Tejas" will be replacing them gradually. Here it would be logical to ask how fast would this "gradually" mean? As we are only putting versions forward, let's not limit our fantasy and assume that Intel wishes to speed up this process as much as possible. But how? Most likely, leaving the bottom places in performance ratings to Socket 478 and making Socket 775 a symbol of an improved, powerful Pentium 4 platform. This makes everything clear: Prescott is required so in the market there's a processor capable of working in both Socket 478, and Socket 775 motherboards. And the Tejas, given we are correct, is to be installed into Socket 775 only undertaking both Prescott and Socket 478. Logical, isn't it? We guess it is. In this case, Prescott shouldn't live for long... Version #3. "Die by the sword you came with..."It's not a secret that competition between Intel and AMD was almost always based on the opposition of two key arguments: Intel's "Our processors are fastest!" and AMD's "Our price/performance ratios are the best!" This has been so for a long time already. And even the release of AMD's K7/K8 didn't change the situation despite the fact that they offered performance much better than that of K6. Before Intel didn't accepted exceptions to its main rule - to sell CPUs that have performance equal to that of rival solutions for slightly higher prices. The market is sometimes very simple - if people buy them anyway, why cut the price? Besides, though Intel participated in the price wars, the starter was always AMD. So, our third version bases on an obvious assumption: what if this time Intel decided to act more aggressively than usual and start the price war itself? Prescott's list of benefits includes not only the newness, cache sizes and potential (unconfirmed yet) scalability, but also the... price! This core is relatively cheap for production - if the 90nm process enables yield similar to at least Northwood, Intel will be able to sell its processors at significantly lower price losing nothing in absolute profit activities. It's obvious that such CPU characteristic as price/performance ratio can be improved by not only improving the performance, but also by reducing the price. Actually no one stops from reducing the performance, it's just to cut the price anyway :). According to unofficial Pentium 4 Prescott prices that appear in the Web, they should be much cheaper than Pentium 4 Northwood. So we can assume that Intel decided to perform a kind of an outflanking - while the main rival is still after the performance, it will be hit in the middle-end segment, where users thoroughly analyze price/performance ratio. Version #4. Hidden WeaponHere we must make a lyrical and historical digression for those who weren't continuously observing various nuances of the processor segment. So, for example, we might remember that right after the first Hyper-Threading processors arrived (not Pentium 4 "Northwood" + HT, but Xeon "Prestonia"), many were asking themselves: "If Prestonia and Northwood cores are so alike that their features are almost identical, and Prestonia still supports Hyper-Threading, while Northwood doesn't, would it be logical to assume that Northwood has it forced off, blocked?" Afterwards this was indirectly confirmed by the announcement of Northwood-based Pentium 4 3.06GHz with Hyper-Threading. The most daring even proposed rebelliously that even Willamette had Hyper-Threading! And let's now remember what we have regarding to Intel's new technological innovations. What comes to mind at once is La Grande and Vanderpool. The first provides hardware protection against outside breaches (so one software can't interfere with another). Of Vanderpool we know less, but according to what we have, we can assume it's a variant of complete PC virtualization, including all hardware resources. The simplest (and the most effective), example - two OS on a single PC, and if one of them even reboots, it doesn't affect the other anyhow. So, getting back to the theme: we strongly believe that both La Grande, and Vanderpool are already implemented, but blocked in the Prescott core (like it was with Hyper-Threading). If this is true, many things become clear. In particular, why it is that big, why it was in development for so long, but still doesn't differ much by the clock speed from the previous one. It seems like developers focused most of their efforts not on the highest performance, but on innovations debugging. This version has some things in common with the second - either way we deal with an intermediate core that is not required to be perfect, according to its role. By the way, the third version nicely adds to the second and the fourth: the low price here is to sweeten the pill of "intermediacy" for the end user. Drawing the bottom line
We had reasons to call this article "Half a step
forward". Prescott turned out to be more complex and ambiguous
than merely a Northwood with more cache and higher clock rate expected
by many. Of course, we might blame the manufacturer for a nearly zero
average performance boost, for high heat emission, new mishmash with
motherboard support... And, pardon us, it would be rather fair. After
all, these are not our problems, but we exactly are to stumble upon
them. So we'll just put bold dots in the end. We witness only the
beginning of a step. What should we see next and will the future (Tejas?)
be good for us? Only the time will tell...
Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. |














