 |
||
|
||
| ||
|
||
|
||
| ||
We've been waiting for it.
And finally, here is the new architecture: a correction of past mistakes and a solid foundation for the future. But is it really so? We are going to probe into both aspects.  CONTENTS
D3D RightMark synthetic testsThe version of D3D RightMark Beta 4 (1050) synthetic benchmark we used, as well as its description is available at http://3d.rightmark.org Testbed configurations:
First, let's see whether the announced features (16 pixels per clock, 16 TMUs, etc.) are really such. Pixel Filling testTexelrate, FFP mode, for various numbers of textures overlaid on one pixel: 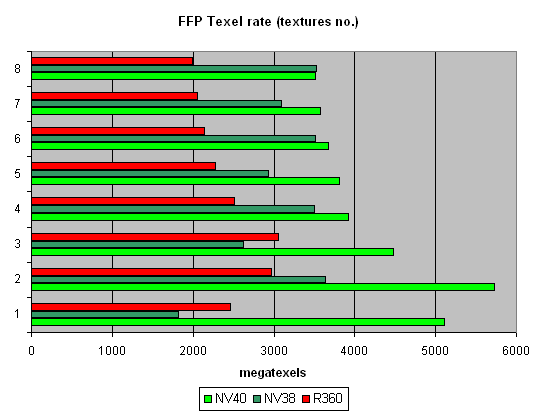 A theoretical NV40 maximum for this test is 6.4 gigatexels per second. In reality, we nearly reached 6 gigatexels, which clearly indicates that there are 16 texture modules. One texture has a result just a bit lower than two textures have - obviously, the frame buffer bandwidth is not enough, and then we see a steady relation: the more textures, the lower the filling speed. There are no jumps between even and odd numbers (as NV38 has), which is typical of two-TMUs-per-pixel configurations. On the contrary, the picture is similar to that in R360. Thus, we can conclude that the 16x1 scheme has really withstood the reality test. Interestingly, R360 reaches the maximum on three textures, while NV40 only on two, which indicates the latter's more effective work with the frame buffer during filling. And it is no less interesting that as the number of textures grows, NV38 gets closer to NV40 - if there is an even number of textures, the NV38 selection efficiency nearly reaches the theoretical limit. But we remember that real tasks make it much more complicated: R360, not very good at texture selection, often beat NV38 by its number of pipelines and computational capability. We'll examine this aspect of NV40 a bit later. And right now for the fillrate (pixelrate), FFP mode, for various numbers of textures overlaid on one pixel: Well, NV40 is the new tzar here. Its peak speed of work with the frame buffer (0 textures -colour filling and one texture) is twice as high as in R360 and 2.5 times higher than in NV38. However, this chip rights itself with an even number of textures (2 and more). And although the theoretical limit of 6.4 gigapixels per second is not reached, it is definitely possible to write 16 pixels per clock. Thus, as many as 4 quads (2x2) (i.e. 16 pixels) are processed per clock. Interestingly, as the number of textures grows, the filling speed falls faster than in the previous generation: this is due to a low core frequency and a double number of texture units compared to a fourfold increase in the number of pixels. Let us look at the relation between the filling speed and the shader version: 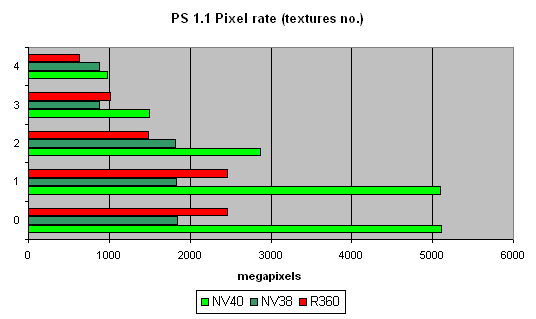 the picture is same as with FFP. Ironically, NVIDIA is now an undisputable leader on shaders 1.4, ATI's brain-child. Well, life is life. Due to its architectural peculiarities, NV38 slowed down on shaders 2.0 in this test (additional clocks were needed for some instructions realised as macros in NV38), which made it more effective with shaders 1.4 (although it is exactly the opposite with R360 where 2.0 has a higher performance than 1.4). But now the justice is restored, miscalculations are corrected, and NV40 is equally good on all shader versions. Though we must say old R360 looks not at all so bad against NV40. Here is a summary graph for a number of textures, that compares NV38 and NV40: 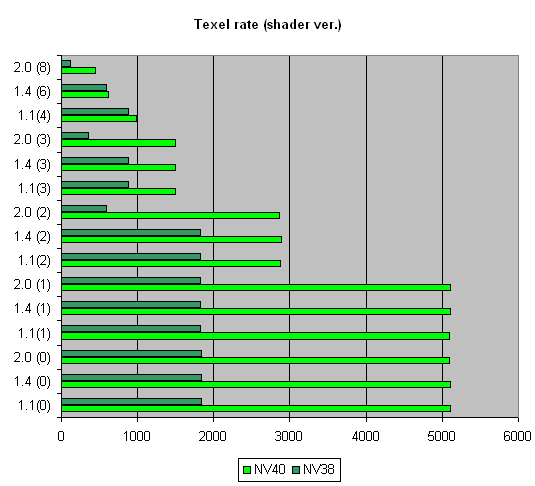 Thus, the following preferrences can be noticed:
And now let's see how well texture modules cope with caching and bilinear filtering of real different-size textures: 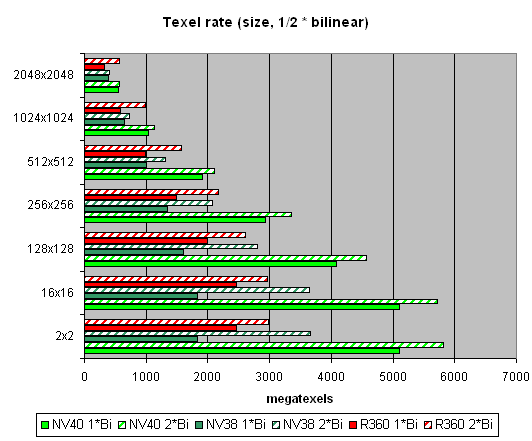 The data are given for textures of different sizes, one and two textures per pixel. Concerning sizes up to 512x512, 16 NV40 texture modules have a visible advantage there, and their results are close to the theoretical limit. But then, as the texture sizes grow, the memory bandwidth becomes the restrictor. Caching efficiency is really high: we reach more than 4 gigatexels on the most common size of 128x128. Now let's see how things will change at trilinear filtering: 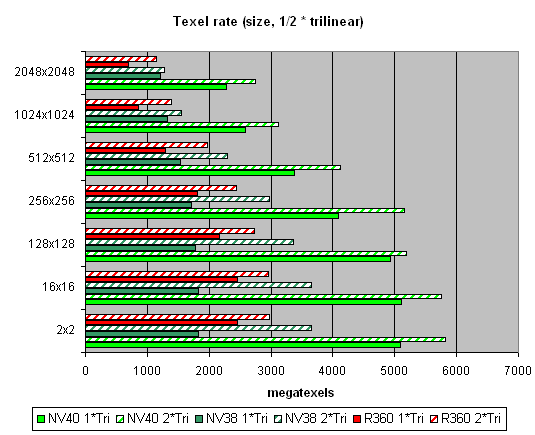 Gee! NV40's advantage is even more solid here. But that makes sense: the more texture units, the higher the results of trilinear filtering. And besides, mip levels enable a more effective texture data caching. NV40 has a double advantage here, which means it's got no rivals in this aspect. And finally, here's a limiting case of 8 textures subjected to trilinear filtering: 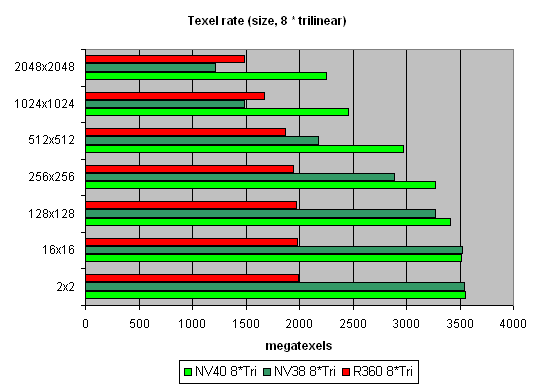 It shows once again that realisation of texture selection is NVIDIA's strong point. Andnow let's take a look at the relation between performance of texture modules and texture formats: 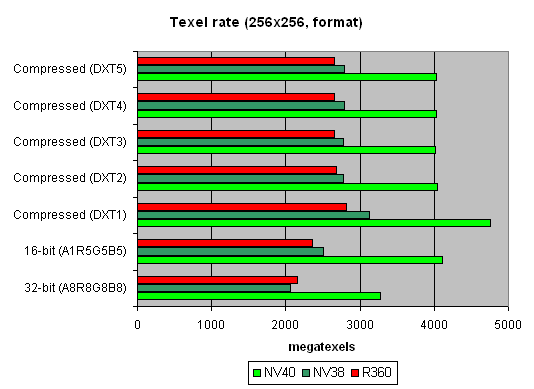 A larger size: 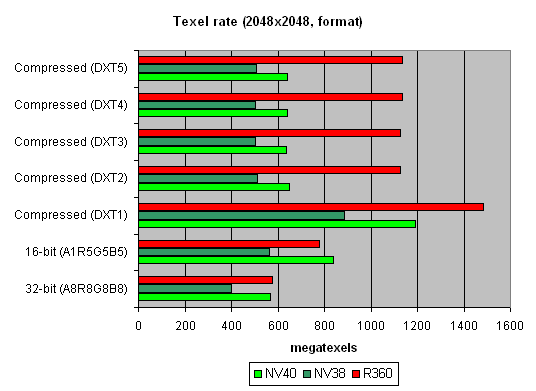 That's pretty interesting, isn't it? Why does R360 defeat even NV40 when compressed textures have larger sizes? The answer is simple as that: textures stored in an NVIDIA texture cache are already unpacked and made into the 32-bit format, while an ATI texture cache contains textures that are still compressed. On one hand, NVIDIA must have a more effective texture selection, as there are fewer standstills during unpacking and consequently, less time is spent. But on the other hand, a large size of the textures can bring about ATI's leadership, as NV40 will reach the maximal memory bandwidth and even its 16 TMUs won't help it. And that is, actually, what we see in the second graph. In real applications, however, the balance can tilt to either side, depending on the shaders, the number of textures and their size, and on many other parameters. Si, ibn general, two facts can be stated:
Geometry Processing Speed testThe simplest shader - the maximal triangle bandwidth: 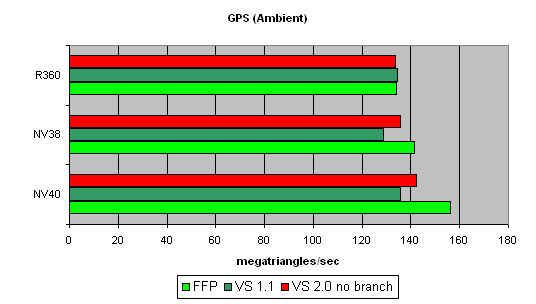 It's difficult to say why NV40's results do not exceed those of the previous generation. To all appearance, the chip's vertex processors just can't make a full flip on such a primitive task. Later we will check our assumption on more complex tasks. And now we can state that NV40's speed dependence on the shader version coincides with that in NV38, and as was supposed before, the vertex processors of these chips may have a lot in common. A more complex shader - one simple point light source: 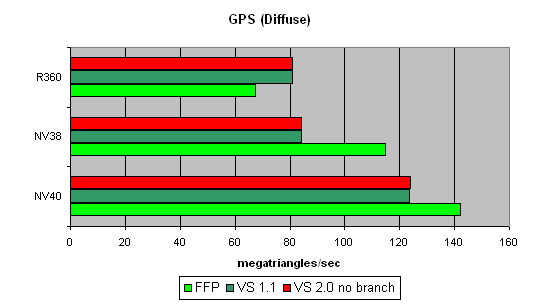 Here, NV40's advantage becomes more visible. A too short shader was just limited by the speed of the buffers and the vertex selection mechanism, while the NV40's vertex processor had the opportunity to be engaged in calculations, and the result was quick to improve. Interestingly, FFP is still the best variant for NVIDIA and the worst one for ATI, due to additional units designed for a quicker lighting calculation within standard FFP requirements. Let's make the task still more complicated: 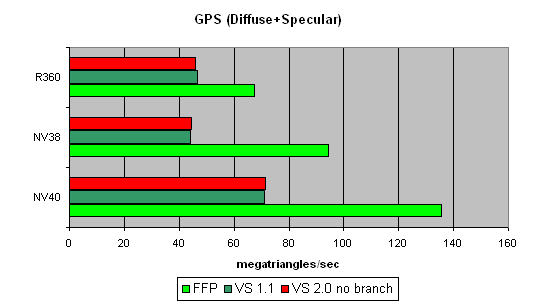 FFP leads here even with ATI: it algorithm is simpler than that used in the vertex shader. And NV40 is a clear-cut champion here. And now the most complex task: three light sources in variants without jumps, with a static and a dynamic exeution control: 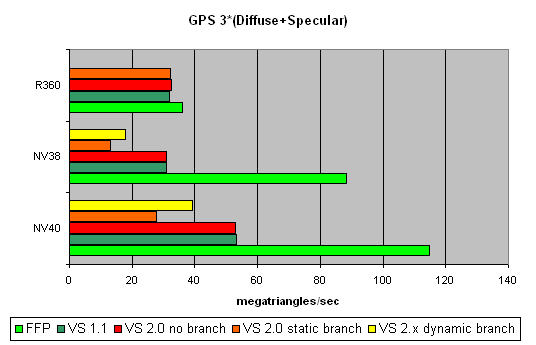 Static jumps badly affect NVIDIA. And as the decrease is similar in both NV38 and NV40, we can conclude that their vertex processors are also similar (in this respect). The paradox is that dynamic jumps are better than static ones for NVIDIA chips. In the case of ATI, everything is quite smooth. Thus, to conclude:
Pixel Shaders testThe first group of shaders are versions simple for real-time execution: 1.1, 1.4, and 2.0: 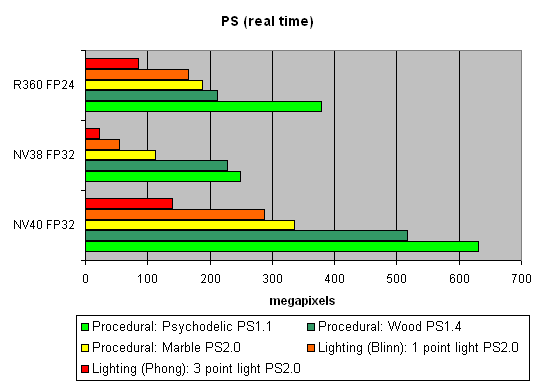 Well, that's finally it: NV40 has defeated NV38. The new layout of the pixel processor, new ALUs and texture module cope excellently with different shader versions. Let's find out the increase of using 16-bit precision floating-point numbers: 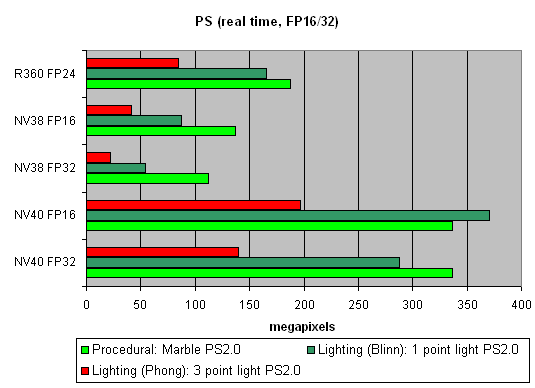 16-bit precision brings NV40 an advantage, bigger in some shaders, smaller in others, and sometimes even more visible than for NV38. Of course, it may be due to the compiler's influence: the more optimised it will get, the fewer temporary variables and pixel processor rounds will be used. As a result, the difference may diminish and FP32 results will get closer to FP16. Now let's take a look at really complex "cinema" shaders: 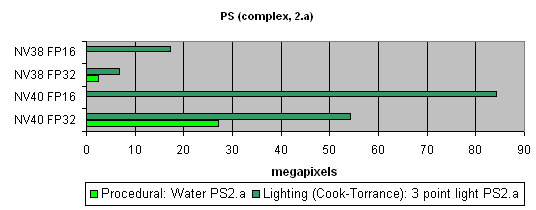 NV40 shows a fantastic performance, several times higher than the results of the previous generation. Dozens of dependent texture selections, a multitude of temporary variables, a complex code - that's why the difference between 16 and 32 bits is so great. And finally, we will examine how speed is dependent on arithmetic or diagram methods of sin, pow calculation and vector normalisation. We will do it separately for each chip: 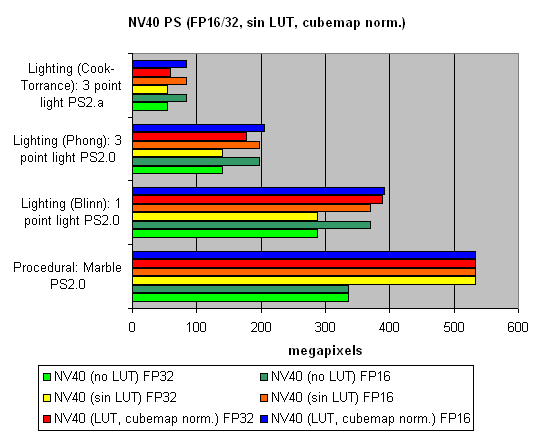 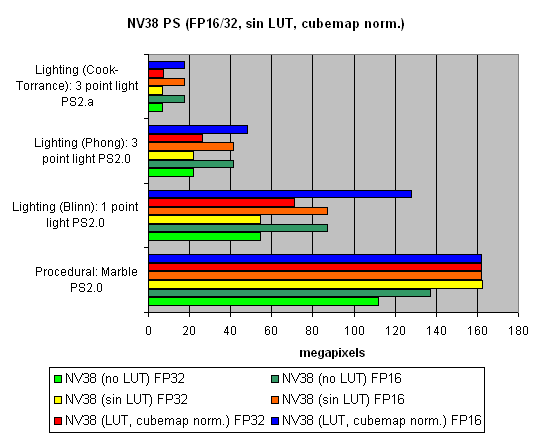 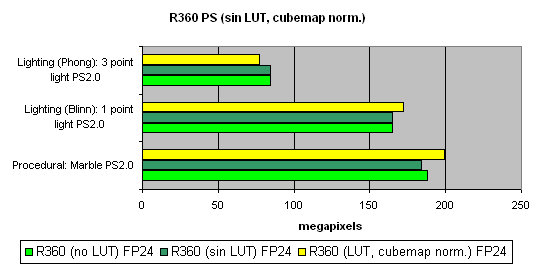 The general conclusions are as follows:
Total results for pixel shaders:
HSR testWe will begin with the peak efficiency (with and without textures) depending on the geometrical complexity: 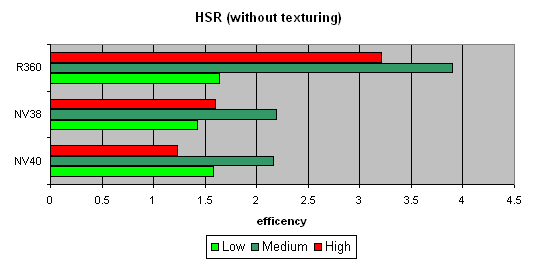 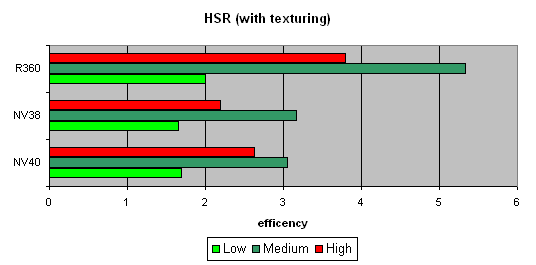 It is clear that ATI is better in moderate and complex scenes, due to two levels of reduced Z buffers (except the base buffer). NVIDIA traditionally has an additional level, which results in a lower HSR efficiency in the case of an optimal scene balance (moderate complexity). Besides, more effective filling and texturing also reduce peak HSR efficiency (or, to be more precise, the penalty for not removed areas diminishes). The dependence character shows that ther have been no changes in the algorithm since NV38. But absolute figures have increased substantially: 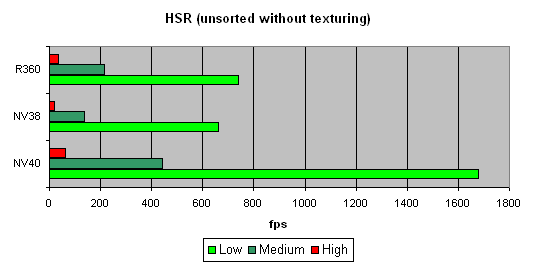 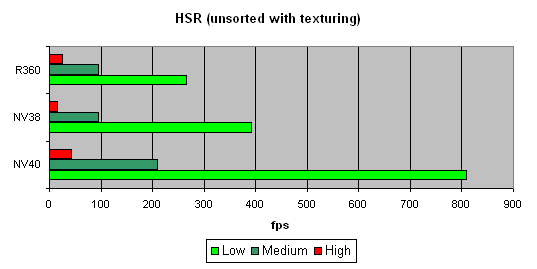 NV40 is evidently beyond comparison being at least twice as good as others. Conclusion:
Point Sprites test.We think, our readers are smart enough to make conclusions themselves. Sprites ceased to be a popular innovation long time ago and often lose to triangles in rendering speed.
[ Next part (4) ]
Alexander Medvedev (unclesam@ixbt.com)
Kirill Budankov (budankov@ixbt.com) 27.04.2004
Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. |














