 |
||
|
||
| ||
|
||
|
||
| ||
Not long ago we reviewed the main pros and cons of the simplest NUMA configuration, implemented in dual processor AMD Opteron platforms. In this case the memory system of the platform consisted of just two dual channel memory controllers (nodes), each of which either contained (Configuration 2+2), or did not contain (Configuration 4+0) its own memory. Controllers were connected with a single bidirectional HyperTransport bus. Now it's time (to be more exact, we have an opportunity) to examine a more complex NUMA organization, which can be implemented with four memory controllers in AMD Opteron processors. Let's have a look at the flowchart below. 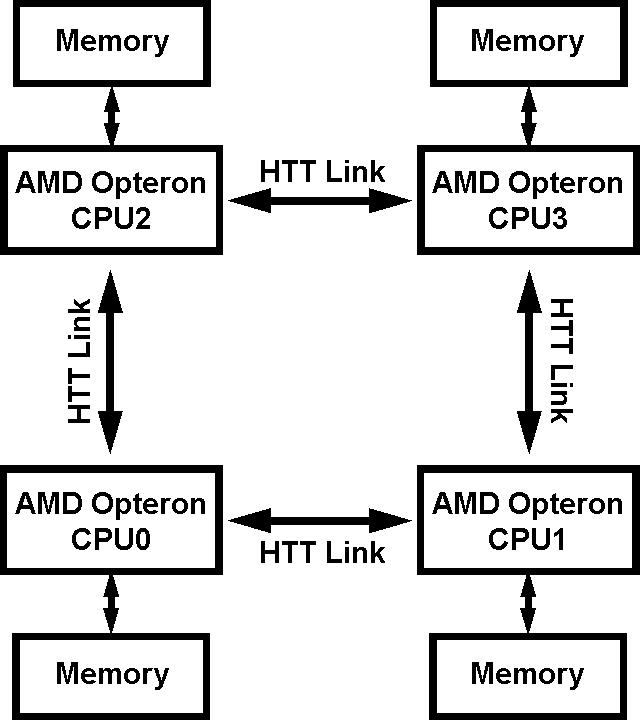 Simplified flowchart of a 4-node NUMA system So, that's what we've got here: each memory controller has its own memory (we shall not consider "cheaper" modifications with no local node memory, as such offers are practically impossible to find on the market of relatively expensive four processor AMD Opteron platforms); each of nodes is connected to two neighbouring nodes via two vacant HyperTransport buses of a processor (remember that AMD Opteron processors have three HyperTransport buses, but in this case one of them is used for connection with peripheral devices via the PCI-X bridge of the chipset). Such an organization of memory system has one important peculiarity: each given processor (for example, CPU0) may have not only local memory (belonging to the memory controller of this processor) and remote memory (belonging to the neighbouring controller, in our example — CPU1 and CPU2), but also double-remote (CPU3). Indeed, in the latter case, in order for CPU0 to get access to the address space of the CPU3 memory controller, electric signals should pass two serial HyperTransport buses (CPU0 -> CPU1 -> CPU3 or CPU0 -> CPU2 -> CPU3, which must theoretically provide additional flexibility for data transfer). Thus, sophisticating non-uniform memory architecture inevitably increases its non-uniformity. That's how it looks like in theory. But as always, we shall test it in practice by carrying out real quantitative evaluations. Testbed configuration and software
Test resultsThe tests were carried out in the standard mode for testing memory of any platform. We measured the following parameters: Average Real Memory Bandwidth for linear reading/writing from/to memory, Maximum Real Memory Bandwidth for Reading (Software Prefetch) and Writing (Non-Temporal Store), as well as Pseudo-Random and Random Memory Access Latency for Walking a 16MB data block. As in case of our previous NUMA analysis, the difference from the generally accepted test is "binding" a test thread to a selected physical processor. Test data is always deployed by the first processor (that is this block will be deployed in the physical memory of the first processor). Then tests can be run on the first processor as well as on any other processor available in the system. This allows to evaluate data exchange parameters between a processor and memory, local or remote. Symmetric 4-node NUMA, SRAT, No Node InterleaveOur BIOS version in the STSS QDD4400 server allowed to control three memory parameters: SRAT (Enabled/Disabled), Node Interleave (Auto/Disabled), and Bank Interleave (Auto/Disabled). Several words about each of them: SRAT stands for System Resource Affinity Table. When enabled, it creates a special cognominal table in ACPI data, which allows OS to correctly associate processors with their memory areas — a very useful thing in case of NUMA systems. Of course, that only applies to NUMA-aware operating systems. Fortunately, Windows Server 2003 SP1 belongs to such operating systems. But this feature is absolutely of no importance for our today's tests - as we have already written, we manually assign our test application to a given processor, while SRAT is actual for regular applications without such binding. On the contrary, Node Interleave is an interesting solution for OS and applications that know nothing about NUMA. As we have already written, this solution consists in interleaving memory by 4-KB pages between modules in different nodes (memory controllers of processors). As a result, the initially asymmetric NUMA becomes practically completely symmetric, as any data block deployed in memory will be homogeneously distributed across the address space of all memory controllers. Note that the platform under review does not allow to enable Node Interleave with SRAT, which is quite natural. And finally, Bank Interleave is just interleaving access to logical banks of a memory module. As our previous tests demonstrated some memory performance gain when this mode was set to Auto, we decided to leave this parameter unchanged. Here is the first series of tests: SRAT is enabled, Node Interleave is disabled (due to enabled SRAT), Bank Interleave is set to Auto. We'd have obtained the same results even without SRAT mode, just by disabling Node Interleave.
CPU0's access (considering that these are dual core processors, a "processor" in this article means the first core of a given physical processor; in fact, we can just as well analyze the second core, we just must review different physical processors) to local memory demonstrates quite acceptable memory bandwidth and latencies. Reading operations with Software Prefetch show 95% of the theoretical memory bandwidth, which in this case is equal to 5028 MB/s (the memory frequency is 2200 / 14 = approximately 157 MHz). Due to asynchronous memory mode, latencies are noticeably higher compared to the results of the previous tests, where we used DDR-400 memory. CPU0's access to remote memory, belonging to CPU1 and CPU2, has expectedly similar characteristics in both cases with a slight advantage of CPU1. The maximum real memory read bandwidth goes down to 57-59% of the theoretical maximum. Memory bandwidth drop is less pronounced versus what we saw with DDR-400 memory, because what's important here is the fact that the memory bandwidth dropped to 3.0 — 3.2 GB/s, which is to all appearances a real maximum of the data transfer rate via HyperTransport (its theoretical maximum throughput is 4.0 GB/s). We are surprised by an insignificant increase in latencies in this case: they grow only by 2-5 ns for pseudo-random walk and by 10-17 ns for random walk. Note that in our previous tests of 2-node symmetric NUMA, remote memory access latencies became noticeably higher — on the average, from 45 ns for accessing local memory to 70 ns for accessing remote memory. The reason for such an insignificant latency rise in this case is not quite clear. It's probably the effect of asymmetric memory operating mode that introduces noticeable latencies even for accessing local memory, which are partially hidden during remote memory access. And finally we should review CPU0 accessing double-remote memory of CPU3, which is done sequentially via two HyperTransport buses. Strange as it may seem, such access mode practically equals remote memory access in maximum real memory bandwidth — it remains on the level of 3.0 GB/s for reading and 2.4 GB/s for writing. Only the average real memory bandwidth is decreased, from about 2.0 GB/s (reading remote memory) to 1.67 GB/s (reading double-remote memory). Besides, this mode demonstrates increased latencies, again insignificantly. Latencies during pseudo-random walk are increased by 18-19 ns relative to local memory access latencies (14-15 ns relative to remote memory access latencies); in case of random walk — 42-45 ns relative to local memory access latencies (32-37 ns relative to remote memory access latencies). Symmetric 4-node NUMA, No SRAT, Node InterleaveLet's proceed to the second series of tests: SRAT is disabled, Node Interleave and Bank Interleave are set to Auto.
Enabling Node Interleave expectedly allows to reach practically complete NUMA symmetry in its 4-node configuration. Note that even in this case the maximum real memory read bandwidth is limited to 65-66% of the theoretical memory bandwidth. What concerns other throughput parameters, symmetrization of the 4-node asynchronous NUMA configuration is slightly worse than symmetrization of a simple symmetric synchronous 2-node NUMA (for example, a noticeably lower memory bandwidth for writing and non-optimized reading). It's also interesting to note a significant increase of pseudo-random walk latencies — nearly two-fold versus the pseudo-random local memory access latency. Besides, in this case the average latency (104-106 ns) cannot be calculated by averaging the results of accessing CPU0 memory by all the four processors — such an average value would have been around 62-66 ns. That may be the fault of more complex interleaving of memory pages that belong to all the four controllers, which makes this mode resemble random walk (pseudo-random walk, implemented in RMMA, is based on linear, direct, sequential walk on the level of memory pages, under condition of random walk within a memory page— but linearity on the level of physical memory pages is broken in this case, because each four sequential memory pages on the logical level belong to different physical address spaces). ConclusionIn our previous article about NUMA in the form of the simplest 2-node configuration we already demonstrated its advantage over the traditional SMP approach. Our today's tests prove that this fact also applies to a more complex 4-node NUMA configuration. To prove it, we publish a table, similar to that in the previous article. It will review traditional SMP systems (multi-processor systems, including dual-core systems or multi-processor dual-core systems with Intel Xeon/Pentium D), 2-node NUMA systems (dual-processor systems, including dual-processor dual-core AMD Opteron platforms) and 4-node NUMA systems (four-processor systems, including four-processor dual-core AMD Opteron platforms). For the last two cases we'll review operating modes both with enabled and disabled Node Interleave. We shall publish relative values of peak throughput (a number of times), not to be bound to quantitative characteristics of a given memory type. And a final note: results of non-optimized multiprocessing/multithreaded cases in NUMA systems are obtained by simple scaling, that is assuming no collisions during data transfer along HyperTransport buses.
Let's sum up what we've learnt about all memory systems. SMP systems: maximum memory bandwidth does not depend on a type and number of running applications, it is always equal to one — that is the throughput of an only memory controller in a system. 2-node NUMA systems: the real defeat from SMP systems can be seen only in case of single-threaded applications, if they are not assigned to a certain processor — in this case approximately 50% of queries are made to local memory, the other 50% — to remote memory; as a result, the maximum real memory bandwidth goes down to a level, when Node Interleave is enabled. No advantage is demonstrated by non-optimized multi-threaded applications either, which allocate memory in the address space of only one of the controllers, thus becoming limited to the memory bandwidth of this very controller. As you can see in the table, this limitation can be removed by optimizing multi-threaded applications to NUMA (ideally, each of the processors works solely with local memory), or by enabling Node Interleave mode to symmetrize the memory system (its benefits are limited to this very case). 4-node NUMA systems act similarly to 2-node systems, but for one important exception — they allow to reach higher peak memory bandwidth values, in case several applications are correctly distributed among the processors, or in case of NUMA-aware multithreaded applications (not fewer than 4 threads exchanging data with memory). These systems are not devoid of drawbacks that are typical to 2-node NUMA systems. Namely, they show no advantage over SMP systems, when only one single-threaded, or non-optimized multi-threaded application is running. However, there is also a way out in the latter case - the well-known Node Interleave mode. But remember that its benefits are limited to this very case, which is hardly widely spread in practice. It's not difficult to make sure that in any other cases Node Interleave can deteriorate memory performance, to say nothing of improving it. Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||














