 |
||
|
||
| ||
|
||
|
||
| ||
"A new generation of Pentium processors. Be ready to meet Intel Pentium 4. Based on a completely new architecture Intel NetBurst, Pentium 4 processor establishes a new standard for high-performance microprocessors. New generation of performance. The processor of a new generation intended for desktop computers features an improved Intel's micro-architecture and a powerful set of additional functions developed to provide an optimal performance for working with the latest Internet-technologies. Get the maximum performance with a new processor Intel Pentium 4 from the leader in microprocessor production..." Part II: how it works |
|
Tweet | ||
It's high time to take a close look at a new processor from Intel - Pentium 4.
Well, we already know what was the reason for Willamette to appear in this world - it's exactly the limitations on the clock frequency of P6 family procesors - it's because of too big stages of the 12 stage pipeline. They are not able to work at the frequency much more than 1 GHz within .18 micron technology. The ceiling for this technologic process is 1.1 - 1.2 GHz. This insufficiently stable work in limiting modes was the main reason of Pentium III Coppermine 1,13 GHz withdrawal.
Intel company surmised this situation long before it happened and it had made a decision of a new hyperpipelining project - that was the processor with 20 stage pipeline. According to Intel, the processors based on this technology will manage to up the frequency by 40% as comparing with P6 family within the same technological process. So, for .18 micron technology the limit constitutes 1,55 - 1,7 GHz; it's quite enough to compete against AMD company which is going on to increase clock frequency of its copper Thunderbird's. Besides, a bit later announced, .13 micron technology will grant much lighter perspective for frequency gain.
However, with deeper look it's not so marvelous as it seemed first. The main task of a pipeline is to provide a continuous processing of micro-ops flow without any delays. To maintain non-stop work of such a long pipeline Intel comapany brought in different enhancements allowing Willamette to appear. Let's look at what there are interesting in the crystal of Pentium 4, and what performance gain might be achieved with such fundamental frequency increase.
Intel fairly estimates all drawbacks of such a long pipeline. Here is their openion.
<Intel>: "Applications can be divided into two main categories - integer/office applications and multimedia applications which use floating point calculations".
Office applications' code contains a lot of branches difficult to predict, and the processor has to implement a lot of idle work, giving out mispredicted branches from time to time and spending much time for suppling the pipeline with the right instructions. To put it simple, a positive factor of clock speed increase is accompanied by the raise of the number of stages, and sometimes by performance decrease. Intel itself says that in such applications the performance decrease may reach 10-20 % against the P6 architecture at the same frequency. But cheer up -
<Intel>: "in applications such as word processors the processor's performance level doesn't influence the working speed quite strongly, since its performance much higher than that of a writing or reading man".
There is something to worry about...
As for applications which actively use calculatons with floating point, there is no troubles because of relatively small number of jumps and simpler prediction -
<Intel>: "such applications do not suffer from pipeline deepening, and they even speed up with clock frequency increase".
And none would doubt that the maximum performance in such applications (i.e. MP3 coding) lightens the life of users much more then unbelievable performance in i.e. Word.
And in result, Pentium 4 comes out not as universal processor that manages any problems, but as a powerful processor exactly for modern tasks with minimum number of branches. Among them the basic step is taken by the applications directly connected to the Internet - even the architecture of the processor is named NetBurst.
NetBurst microarchitecture from Intel includes all perspective developings that were used previously in the architecture of P6 family processors, and some enhancing features.
The continuous work of hyperpipelining architecture can be realized if there is a possibility of out-of-order execution and speculative execution of instructions. Under such scheme, the processor uses an internal branch prediction algorithm, which though gives out the right prediction not all the time. Moreover, the longer pipeline, the more time the clearing and the restart take. To optimize the scheme, the company established the following solutions.
To minimize the wrong jumps, the processor (Willamette) includes a large, 4 KBytes (for P6 it's 512 byte) BTB (branch target buffer), which stores more detailed information on the previous jumps than P6 does. Besides, there used an advanced branch prediction algorithm which allows predicting with more accuracy. Intel hopes that P4 will be able to handle branch prediction with 93-94% accuracy (one third more than in P6 family architecure).
To provide the Execution Unit with micro-ops, the Reservation Station, which is named Instruction Window in the new processor, became larger - up to 126 instructions. So, the processor has got a wider choice of instructions for out-of-turn execution.
The both enhancing features are the part of the Advanced Dynamic Execution Engine.
Execution Trace Cache serves to provide an increased micro-ops flow and to restore the pipeline in case of wrong choice of the branch. Here, the cache is located behind the decoder and contains the micro-ops ready to be executed. Thanks to this feature, the pipeline suspense, which happened due to long decoding of complex instructions, isn't there any more. The micro-ops in the cache are arranged into several branch lines; there is a trace (a long part of the program) that is cached. The traces are chosen successively, regardless of their addresses. It ensures the increased micro-ops flow and the optimal usage of cache space, that can accomodate appr. 12,000 micro-ops.
In simplistic terms it means the following. A lot of programs execute repeated operations on large volumes of data, and these data represent little values (it usually takes some bits). So, there appears an approach to represent the data more compact and to develop the operations that can execute such data sets. These operations are called SIMD (Single Instruction, Multiple Data). Besides, the processor Willamette includes the second generation of instructions which belong to SSE2 (Streaming SIMD Extensions 2), that include 144 new instructions. A bit later we will consider them in depth.
In Willamette processor ALUs (Arithmetic Logic Unit) operate at twice the core frequency, i.e. in the 1,4 GHz processor ALUs would therefore work at 2,8 GHz. So, certain instructions can be executed in half a core clock tick.
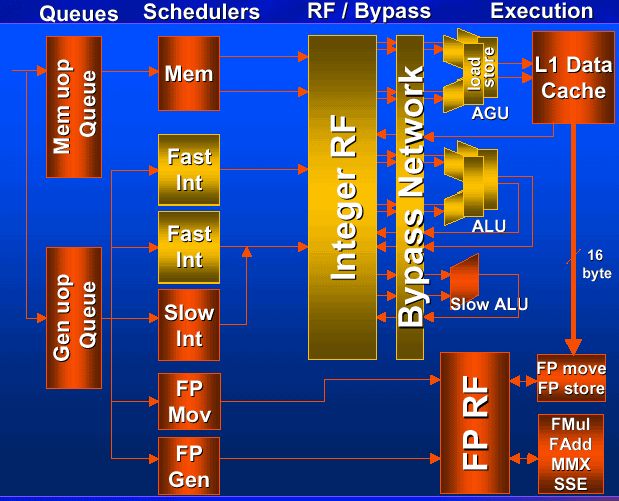
The units of golden color work at the double clock.
A strking Quad-pumped 400 MHz system bus ensures 3.2 GBytes/s bandwidth (compare with 133 MHz bus with 1,06 GBytes bandwidth of Pentium III).
Advanced Transfer Cache of the second level accomodates 256 KBytes and, similar to Coppermine, possesses 256-bit bus, works at processor's frequency and ensures higher bandwidth thanks to the increased clock speed.
A few words about a fast pipeline restart. It's not rather smooth. They lay special stress on that the decoders unit works independantly and doesn't belong to the pipeline itself. It allows to restart the pipeline quicker after the misprediction of the branch. Well, but the pipeline doesn't get smaller with this feature - those 20 stages remain there...
And the Level 1 cache is only 8 KBytes. At the moment we are short of time to look for the reasons which stimulated the processor developers to decrease it as comparing with the Coppermine.
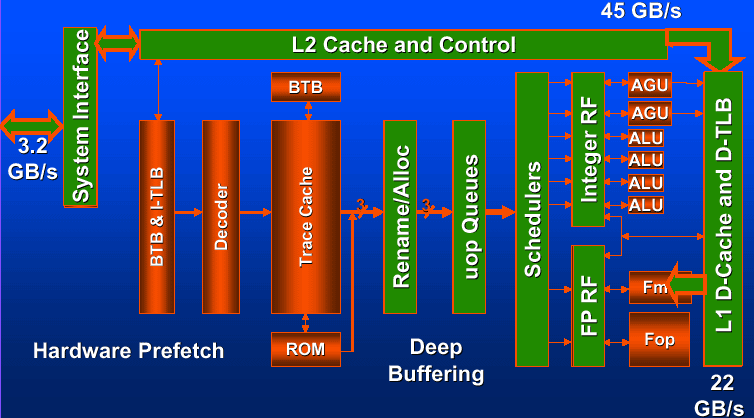
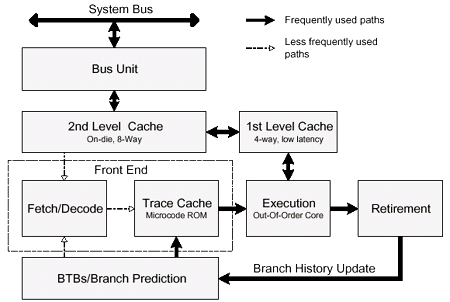
Here are 2 schemes of the Willamette which are supplemental to each other.
Similar to P6 family, the pipeline is divided into 3 independent functional units - the in-order front end which controls instruction decoding and processing, the out-of-order core where instructions are executed, and the in-order retirement pipeline.
Here is the scheme of a 20-stage pipeline:

The translation engine using BTB chooses and decodes instructions into micro-ops, combines traces out of them and transfer them into the trace cache. As soon as the trace is built, the trace cache is cheched for a micro-op that follows the trace; if it exists in the cache, the cache becomes the further source of micro-ops (and not the memory hierarchy).
The trace cache and the translation engine utilize the same branch prediction mechanism: if the required micro-op is in the cache, it is taken out of there, and in case the micro-op is not there, it's taken out of the memory hierarchy. And it serves the base for a trace which is formed by the translation engine in the trace cache.
The BTB helps to define the address of the next micro-op in the trace cache (TC Nxt IP). Then micro-ops are fetched out of the trace cache (TC Fetch) and are transferred (Drive) into the RAT (register alias table). After that, the necessary resourses are allocated (such as loading queues, storing buffers etc. (Alloc)), and there comes logic registers rename (Rename). Micro-ops are put in the Queue until there appears free place in the Schedulers. There, micro-ops' dependencies are to be solved, and then micro-ops are transferred to the register files of the corresponding Dispatch Units. There, a micro-op is executed, and Flags are calculated. When implemeting the jump instruction, the real branch address and the predicted one are to be compared (Branch Check). After that the new address is recorded in the BTB (Drive).
Well, we can see that the 20-stage pipeline includes neither the translation engine nor the output unit. It's obvious that the processor does have them. And if the former might be detached from the pipeline at the expence of a large trace cache, the latter can't be hidden … So, what's there? Are there more than 20 stages? 22? 25? Or even 30? Well, the truth is not far off …
The most important positive feature of this processor is the usage of the second generation instructions called SSE2 (Streaming SIMD Extensions 2).
This new instruction set supports new formats of packed data and increase the speed of manipulation of 128-bit SIMD integer operations.
Besides, this extension adds the ability to manipulate double precision floationg point operations and several types of integer 128-bit operationes. All new data types can be operated with in XMM registers.
There are some improvements that concern 68-bit SIMD integer instructions, which worked in Pentium II and Pentium III processors with 64-bit MMX-registers; in Willamette architecture they allow operating with XMM-registers. This goody will add some more flexibility when developing SIMD-code using both MMX and XMM-registers.
It's obvious, that these improvements will up the performance dramatically in such applications as audio and video coding/decoding, speech recognition, and will allow to obtain some increase in 3D-graphics. Scientific and engeneering applications will see much of their speed boosts from the floating point side of SSE2.
In addition to main SIMD instructions there brought in some new instructions allowing to control data caching. There is possible a preselection of data before they are wanted, and streaming data transfer from/to the registers without cache destroying.
Besides, SSE2 instructions are completely based on SSE, do not require OS support, and will probably prove to be the main ace of the Willamette processor.
Well, the collected information on the new processor allows to estimate it, to define its pros and cons. When writing the review we used no leakage of information on the new device, which is kept secret. All data we have got are taken out of documentation, news releases and presentations which often contradicted each other (Intel is the author of all of them, though). Our task was to reveal the truth, systematize the material and give it out to our readers in simple form.
However, there are some blank spots, which we will try to fill in the shortest time possible; most likely it wiil be done right after an official announce of the processor on the 20-th of November.
And to this day we promise you to place in the site our last part of the review, where you can find the most interesting - benchmark tests and photo-gallery of a real Pentium 4 Willamette based computer.
Write a comment below. No registration needed!
|
Article navigation: |
| blog comments powered by Disqus |
| Most Popular Reviews | More RSS |
 |
Comparing old, cheap solutions from AMD with new, budget offerings from Intel.
February 1, 2013 · Processor Roundups |
 |
Inno3D GeForce GTX 670 iChill, Inno3D GeForce GTX 660 Ti Graphics Cards A couple of mid-range adapters with original cooling systems.
January 30, 2013 · Video cards: NVIDIA GPUs |
 |
Creative Sound Blaster X-Fi Surround 5.1 An external X-Fi solution in tests.
September 9, 2008 · Sound Cards |
 |
The first worthwhile Piledriver CPU.
September 11, 2012 · Processors: AMD |
 |
Consumed Power, Energy Consumption: Ivy Bridge vs. Sandy Bridge Trying out the new method.
September 18, 2012 · Processors: Intel |
| Latest Reviews | More RSS |
 |
Retested all graphics cards with the new drivers.
Oct 18, 2013 · 3Digests
|
|
Added new benchmarks: BioShock Infinite and Metro: Last Light.
Sep 06, 2013 · 3Digests
|
|
Added the test results of NVIDIA GeForce GTX 760 and AMD Radeon HD 7730.
Aug 05, 2013 · 3Digests
|
 |
Gainward GeForce GTX 650 Ti BOOST 2GB Golden Sample Graphics Card An excellent hybrid of GeForce GTX 650 Ti and GeForce GTX 660.
Jun 24, 2013 · Video cards: NVIDIA GPUs
|
|
Added the test results of NVIDIA GeForce GTX 770/780.
Jun 03, 2013 · 3Digests
|
| Latest News | More RSS |
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook
Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved.







