 |
||
|
||
| ||
|
||
|
||
| ||
nForce is a real force!Rate of growth is the most important factor on the IT market now. And here such a promising company as NVIDIA has to look for new niches to maintain its strong position. The most part of the graphics accelerator market belongs now to NVIDIA, and it is still growing. However, it becomes more difficult to increase their share. Anyway, XX% of users will buy alternative products. And it is quite expensive to make them to change their mind. On the other hand, on the corporate market Intel with its integrated solutions and ATI rule, and NVIDIA has great opportunities here. Foray into the corporate market is the key problem to solve for NVIDIA in the near future. And NVIDIA follows its own strategy. The rumor has it that it is unnecessary to use 3D graphics for business applications. On the other hand, the NVIDIA's position in 3D graphics is the strongest. Large companies pay great attention to TCO (total cost of ownership), that is why integrated solutions are so popular in offices. NVIDIA has created an integrated chipset and has started to promote it actively. This chipset allows us to use 3D graphics in business (3D models of products, presentations and graphs). This way NVIDIA wants to persuade the corporate market that there is nothing to do without modern 3D graphics in office. If NVIDIA is able to make a graphics accelerator of 57 million of transistors, the experience of developing such complex chipsets gives at least 50% of success in developing any other solution, including a chipset, especially a chipset with an integrated graphics; this allows to use a ready graphics core. If earlier a computer was used for a classic set of applications (e-mail, word processing, speadsheet), now in the corporate sphere it is often necessary to solve a wide range of problems related to multimedia (video/audio editing, surround sound, etc.) and 3D. So, NVIDIA offers its new solution for the corporate PC of the XXI century. NVIDIA nForce Platform Processing Architecture (NVIDIA nForce)The chipset traditionally consists of two chips: North and South bridges. But here instead of banal North bridge and South bridge we have nForce Integrated Graphics Processor (IGP) and nForce Media and Communications Processor (MCP). Either device is positioned as a processor, that can take a part of the CPU's work. Exactly such approach for designing chipsets is, in our opinion, the most rational. The performance increase requires more advanced mechanisms than usual buffering and pipelining. 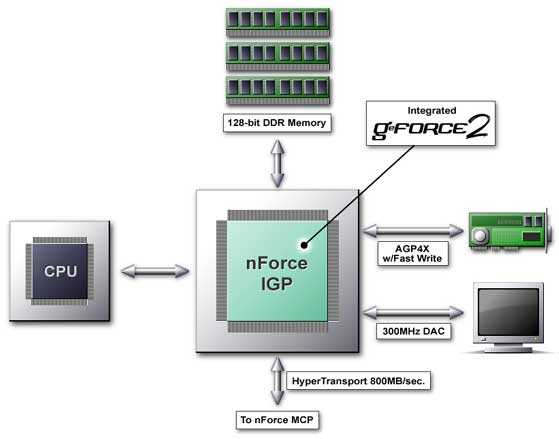 The North bridge (Integrated Graphics Processor) is equipped with an integrated video - GeForce2 MX core. All the parameters and features of the integrated graphics core coincide with the GeForce2 MX. The difference lies in usage of Shared Memory, which provides another bandwidth of the memory bus, and therefore, a performance, as well as connection with the processor via a wider internal bus (8x AGP like). Now let's mark three major things about the North bridge: 
Let's take a closer look at the IGP architecture: 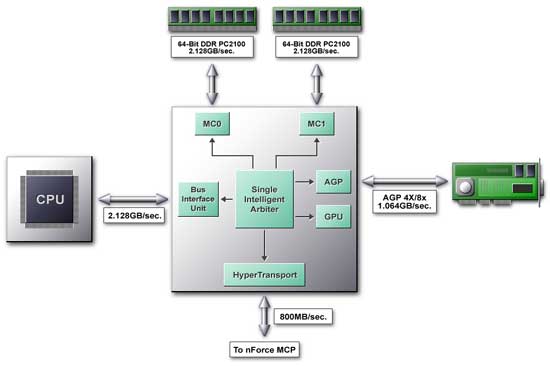 The Single Intelligent Arbiter serves a base for the NB, which is a connecting link for all functional units. This unit implements two functions. The first is a high-speed internal communication of NB functional units. Here the Single Intelligent Arbiter acts as a cross-commutator providing the following ways of data exchange with the memory: 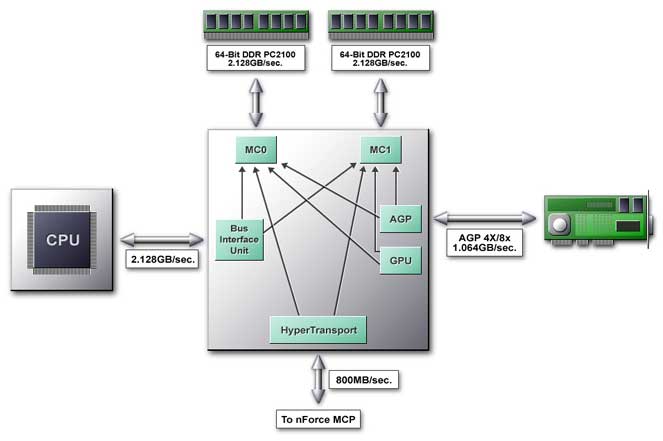 Besides, it is responsible for data transfer from the processor to the external AGP 4X bus, the integrated graphics core and HyperTransport bus. The Arbiter has an advanced caching system not only for data but also for various algorithms (patterns) of memory accessing and is able to predict and access data. This mechanism is called DASP. DASPThe chipset manufacturers think out new methods to provide a processor with a continuous data flaw. For example, the SuperBypass technology from AMD allows a processor to retrieve data directly from the memory in certain cases. NVIDIA offers its own solution for the mechanism which provides minimal delays in the circuit "CPU - chipset - memory". This mechanism is called DASP (Dynamic Adaptive Speculative Pre-Processor). The key word here is Speculative. Such technology means implementation of some action beforehand. Such implementation, regardless of whether it will be really called for, decreases idle time of a pipeline in CPUs. Why not to apply similar technologies in chipsets? Let's look at the DASP closer. This is a device (agent) which traces CPU requests and tries to anticipate a access pattern based on some algorithms. The most part of processor requests to the memory has a definite form, so you can say what data and from what part of memory will be requested later by processor. The DASP guesses the sequence of processor requests and loads data in its cache in advance. This helps to make delays much smaller. According to NVIDIA, latency becomes 40-60% lower. The DASP effectiveness rides on two important things. The prediction block traces not one but a lot of data flows at the same time, which makes possible to choose data for placing into the DASP cache in the most effective way. A completely pipelined architecture allows to execute operations of reading from the cache/recording from the memory into the cache simultaneously. Secondly, the chipset is designed so that in case of incorrectly predicted data placed into the cache the processor can access the memory directly leaving the DASP aside. In this case no performance losses appear. The processor is the most unpleasant client for the memory. It jumps from one part of the memory into others crossing with other devices that store their data in the memory quite logically. The synchronous memory even with two parallel channels slows down its operation considerably, it has to reinstall an initial address. How to prevent it? Let's consider two popular problems - multiplication of matrixes and search in the data base with a key field: Multiplication. Two sequences of reading and one of recording go simultaneously:
Reading is implemented successively only for the second matrix, the first one is read in steps. Search in the database with two fields. A size of the whole record is SIZE, a shift of the first desired field from the beginning is SHIFT1, of the second - SHIFT2.
Here it is more complicated, a gap is again the same, but the record access can touch several fields. But, as a rule, fields are read in the same order. The DASP memorizes shifts between consequent operations of reading in an associative array, and then, when a processor implements a similar operation, it recognizes known sequences access patterns and starts a predicted data access. It is capable to trace several patterns at the same time. According to NVIDIA, the benefits with the DASP enabled are from 6% to 30%. The largest benefit is obtained in case of copying and memory search tasks, 8%-6% are achieved in case of Hi-End applications such as coding with Windows Media Encoder 4.0 or a final rendering of a movie on the Adobe Premiere 5.0. This new technology based on the prediction and recognition of access patterns sets a new level for all developers of modern computer architectures. TwinbankAnother cardinal innovation of NVIDIA is a unique dual-channel DDR memory controller called TwinBank Memory Architecture. This architecture enables never seen before 4.2 GBytes/s memory bandwidth for PC2100 modules. Here we should ask whether the system bus of Athlons and Durons is well balanced with respect to a twice larger memory bus bandwidth. Let's recall an i840 chipset with a dual channel RDRAM controller with 3.2 GBytes/s bandwidth and with usual 133 MHz FSB. The advantage of i840 based systems over i815 based systems with PC133 memory was very small. In that case FSB with 1.066GB/sec was a real bottleneck. Besides, the i840 systems were slower than i815 ones at the expense of a higher latency of the RDRAM. Here we should mark out two aspects that differ the situation with the TwinBank Memory Architecture from the one mentioned above. Transition to the DDR memory doesn't cause a serious increase in latency. The memory subsystem was created aiming at this graphics subsystem integrated into the chipset. So far incredible power of the GPU that uses not a separate memory but works using SMA (Shared Memory Architecture) makes NVIDIA engineers expand the memory bus width up to 128 bit, thus giving 4.2 GBytes/s bandwidth. Let's consider how the TwinBank Memory Architecture works. It is based on two independent 64-bit DDR memory controllers marked on the scheme as MC0 and MC1 and supporting both PC2100 and PC1600 DDR SDRAM. The advantage of the cross controller is that it allows the CPU and GPU to access memory modules at the same time. Data stored in the memory according to a principle of interleaved organization - such scheme makes possible to start reading a data block from the first controller until the second part of the previous block is read from the second controller. At one clock cycle each controller can give 128 bit of data (DDR). Since all data types operated by CPU and GPU are optimized for 64-bit access, in almost all cases memory access for a CPU and GPU is simultaneous and independent. As a result, memory access becomes more effective. The memory controller can work both in 128-bit and in 64-bit modes. The 64-bit mode is supported by the first controller MC0 and the second one - MC1. The system will work regardless of what bank your DDR module is installed in. MC0 is responsible for the DIMM0 connector, and the other two - DIMM1/DIMM2 are controlled by MC1. The both controllers have the same functionality, but they at the same time are programmed independently. In case of two memory modules of different capacity or PC2100 and PC1600 modules the system will provide a normal 128-bit memory access but with some restrictions. As a result, an interleaved organization of operation of the memory controllers, the doubled effectiveness of operation with the memory will be possible only in a zone where sizes of the modules coincide. So, for obtaining the maximum performance it is better to use modules with the same size. Apart from DDR memory, SDRAM is supported, and the total size of the memory supported makes 1.5 GBytes. Unfortunately, ECC features no support. Theoretically, the situation is quite promising - the dual-channel memory controller is able both to provide a definite overall performance gain and to become an excellent mate for a high-efficient GPU integrated into the chipset. As for the integrated graphics core, here we may expect both lower and higher performance than that of the GeForce2 MX. Highs: a wide memory bus (when all other devices and the processor load the available bandwidth incompletely), a wide internal bus "processor - integrated graphics core" with a bandwidth equivalent to that of AGP 8x. Lows: the total memory and the lower clock speed (a maximum of 133 MHz instead of 166 or 200), low quality 2D graphics. NVIDIA has given the results of the nForce in the Quake3 (1024X68X32) in the presentation. The nForce's performance with 64bit memory access is nearly the same as that of GeForce2 MX200 based cards, and with the 128bit memory access the nForce performs nearly 25% faster than the GeForce2 MX200. The high-speed interface HyperTransport crowns the possibilities of the NB. AMD has developed it to provide 800 MBytes/s bandwidth. And exactly it provides communication with the Media and Communications Processor (MCP). nForce MCPThe South Bridge pleases us with a degree of integration and a set of functions: 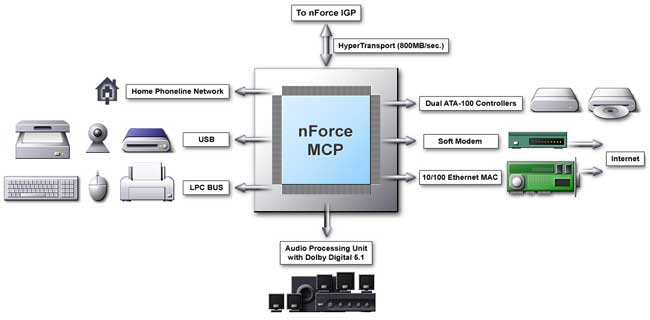 It is called MCP (Media and Communications Processor), it has the following functions: 
There are two versions of MCP that are planned to be produced - with hardware Dolby Digital 5.1 encoder and without it. The chips will be called MCP and MCP-D. The MCP supports the special patented NVIDIA technology for a continuous isochronous (transfer of packets in equal periods of time) data flow for a network interface. Hihg-speed network protocols are based on it, and if a packet is not received, it should be resent. The StreamThru technology must provide a garanteed bandwidth for an integrated network controller making the number of packets to be resent minimal. NVIDIA reports that a full featured network controller integrated in the MCP provides the 15% performance boost in real network applications as compared with its PCI bus competitors. APUYou might remember the first NVIDIA chipset NV1 (the most popular card based on it was Diamond EDGE 3D). It has a powerful (for that time) integrated sound subsystem with the performance of 350 MIPS, with hardware support of 32 audio channels with 16 bit and 44.1 kHz sampling frequency. Samples in the DLS1 format were loaded into the RAM. But at that time NVIDIA was too early to the market with this new technology and its solution didn't become popular and was not successful. So, today it is the second NVIDIA's attempt to introduce its solution which also contains the audio part - APU. What is APU? The nForce APU is the Audio Processing Unit, one of the components of the Media and Communications Processor (MCP). It is meant to unload the CPU from sound processing calculations. Advantages of the nForce APU:
APU architectureThe Audio Processing Unit is a multiprocessor audio rendering engine. 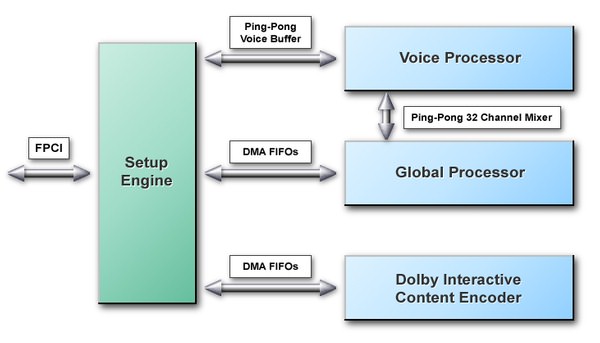
General structural scheme of the APU The APU consists of 4 main functional units:
The APU accelerates audio streams on a hardware level when recording and playing. All operations on audio data are implemented in the system memory. Thus we can direct the resulting stream to any digital device of an audio subsystem or to use it again as one of the sources for the following mixing. Setup EngineThis unit implements the following functions:
Voice ProcessorThe Voice Processor (VP) implements rendering of all 2D and 3D voices. HRTF filters are calculated at the same time with other 2D calculations. All samples are mixed in one of 32 mixer bins. The input data and parameters are ping-ponged on a voice basis. Global ProcessorThe Global Processor is a programmable DSP. It will perform the following functions on each frame:
Dolby Interactive Content EncoderSo, the nForce APU contains an integrated Dolby Interactive Content Encoder based on the programmable DSP with a data format converter from a fixed form into a form with a floating point (fix-to-float format engine). Data are taken from an output of the Global Processor and encoded into the Dolby Digital (AC-3) stream. A user may enjoy a multi channel surround sound of a cinema quality... rendered in real time mode by means of the nForce APU and then decoded on a normal home theater set or a high-quality multimedia 5.1 acoustic set with DD5.1 decoder. 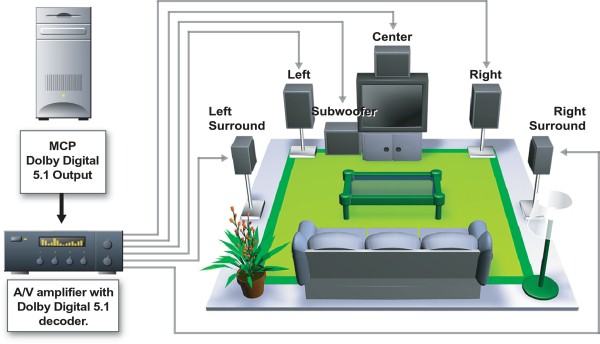
nForce APU features usage for the multi channel surround sound of true cinema quality DirectX 8.0 Features and BenefitsIn the DirectX 7.0 under the DirectMusic we mean a questionable usage of a MIDI Microsoft Sinthesizer with a possibility to load its samples into the DLS. Here are the reasons why the developers didn't like the DirectMusic until the DirectX 8.0 was released:
But developers have accumulated sufficient experience of usage of MIDI technologies. It is a work without temporary delays with samples and loops, per-channel effect overlaying, etc. With the release of the DirectX 8.0 Microsoft decided to make the DirectSound and DirectMusic closer in order to give programmers a possibility to reach flexibility and to increase the quality of musical decoration of programs. The DirectX 8.0 brings several new benefits into its audio part - DirectSound and DirectMusic:
The APU was developed exactly as the DX8 audio processor and has an opportunity to make calculations on a hardware level:
3D sound APIFinally we can see NVIDIA/Sensaura license agreement (dated 13.11.2000) results. Additional possibilities of the APU in case of usage of DS3D extensions of Sensaura:
It is still unclear whether the Digital Ear technology will be used for adjustment of HRTF filters for every user. Fans of the A3D technology can't announce NVIDIA to be a follower of Aureal. The Sensaura technology allows to translate some calls A3D 1.0 in DS3D. But it is only a program emulation, not fully hardware supported A3D. The major mistake of all native APIs is their closeness (Glide in 3D graphics, A3D in 3D sound). The EAX or I3DL2 is another question. An open realization of the API in the form of DS3D extensions makes possible a normal support among a wide range of manufacturers of cards and 3D technologies - Sensaura, Creative Labs, CLR, QSound Labs. And even here we have some misunderstandings among PC users. One of them is that there are only two formats of 3D sound: EAX and A3D. And also DS3D which is a low qulaity program 3D sound. But algorithms from Sensaura are very interesting and as there are no "Sensaura" option in the games it means nobody support it now. Fortunatelly it is not true! At the moment there is only one 3D API - the DirectSound3D. If you don't have a modern sound card, when switching on the DS3D the program variant is enabled - Hardware Emulation Layer, which a 8 bit 22 KHz (at default) sound. If there is a hardware support of the DS3D the program transfers the API calls to a sound engine. After that algorithms supported by the card start working (as well as software support in driver level). When enabling the EAX option in a game the DS3D extensions start working according to the presets of the surround sound - reverberation. The EAX2 accounts for occlusions and obstructions. The quality of realization depends completely on the drivers and the sound card. So, Sensaura algorithms fully work in case hardware DirectSound3D, EAX1, EAX2 and I3DL2 supported by the game. It is interesting whether NVIDIA will be able to provide sound in games in 6 speakers with usage of the technology of multichannel 3D sound MultiDrive from Sensaura. The only 6-channel solution CS4630 uses only 4 speakers for it with current drivers. Preliminary comparison of the APU with other 6-channel audio chips
* Dolby Pro Logic encoding is present ** DD 5.1 decoding with a soft DVD player *** DD 5.1 decoding with drivers and a soft DVD player The APU supports all latest features and benefits of the sound part of the DirectX 8, provides a great deal of hardware voices (DirectSound - up to 256, and 64 DirectSound 3D), supports multi speaker configurations (up to 6 speakers). The APU is able to encode and transfer data in a Dolby Digital stream via S/PDIF to a home theater. NVIDIA is trying to make its audio subsystem to correspond to the level of the latest achievements in 3D graphics. Let's wish them good luck! ConclusionThe NVIDIA nForce chipset will be shipped in 4 versions (128/64 bit memory bus nForce IGP and presence/absence of hardware encoding of Dolby Digital 5.1 in nForce MCP):
The most part of the first boards will be based on the 420 (420-D) system. In the second part of the article we will carefully examine the performance and possibilities of the cards on the nForce. Note that ABIT, ASUS, GigaByte and MSI will be main NVIDIA partners to launch nForce.  The ASUS (A7N266-V) board was first prepared for the release, and exactly this board will probably be used at nForce presentation. If a user installs an external graphics accelerator from NVIDIA on this board it will be unnecessary to install new drivers. It was made possible due to the unique driver architecture from NVIDIA. If, for example, your company has 1000 computers and you decide to upgrade a video subsystem on all of them, it will be much easier for you to implement it.  NVIDIA has developed special stickers to place them on computer cases, inside of which nForce mainboards are installed. We can state that these stickers will first appear on Fujitsu-Siemens computers since Fujitsu-Siemens is a partner of NVIDIA in promotion of the nForce on the corporate market. XBox will use a chip called MCP-X - it is a full analog of the MCP-D, differing only in the lack of PCI bus support. The NB of the XBox is the IGP-128, with the GeForce2 core replaced with GeForce3, with special advanced T&L unit. Another differnce is Intel Pentium III and AGTL system bus. 2 DDR memory channels will work at 200 MHz providing a bandwidth more than 6 GBytes/s. The GeForce3 has a lower memory bandwidth than its full version. But there is nothing to worry about - a console doesn't need high resolutions and high fillrate. An Internal bus "CPU <-> GPU" is not only wider than a standard AGP 4x, but it is free from many disadvantages of the latter. Since we mentioned Intel, let's take into consideration the following fact - the nForce chipset with a 128bit FSB provides a bandwidth of 4.2 GB/s; it is more than enough for the Intel Pentium 4 (without a graphics accelerator integrated into an IGP). Intel has to decide what to sell: processors or chipsets. Besides, Intel takes usage of the HyperTransport from AMD in mainboards for its own processors as a support of a competing company. So, if Intel decides that it is better to sell its own processors and that the HyperTransport is just a good and convenient technology, then, first, the market will receive an excellent High-end chipset for Pentium 4; secondly, the market will get a good chipset for Pentium 4 for a corporate market (where Intel wants so much to promote Pentium 4 !); thirdly, it won't be necessary to promote "marketing" chipsets, like i845 for Pentium 4 (it is ridiculous to offer solutions with a system bus that can pump less than 3.2 GB/s of data for Pentium 4); fourthly, all users, as well as Intel, benefit (since the market will offer good chipsets for good processors, and nobody will find fault with Intel because of the policy in advertisement and sales). Let's wait and see what Intel will decide. Technical problems when adapting NVIDIA nForce for Pentium 4 are, in fact, absent. In the second part of the article we will examine some peculiarities, stability and performance of the nForce chipset in detail. Highs:
Lows:
Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. |














