General
No secret that on February 27 at Intel's Developer
Forum (IDF) a new GPU from NVIDIA, known as NV20, must be announced
officially. All are interested what's new could be seen in this
graphics processor. So, we are going to lift the veil of secrecy.
Note that we won't give results of performance measurements since
this engineering sample is rather raw and the drivers are not finished.
But on the NV20 functional features we can speak today in full volume.
First comes the NV20 specification (we are demonstrating
the most interesting parameters in order not to repeat everything
supported in the GeForce2).
NV20 specification
- Technology: 0.15 micron
- 60 mil. transistors
- Graphics core frequency: 200+ MHz (later "Ultra" and "Pro"
variants are possible, e.g. at 250 MHz)
- Rendering pixel pipelines: 4
- Texture blocks per rendering pipeline:
2
- 4 textures per pixel
- Memory interface: 128 bit
- Supported memory as DDR SDRAM/SGRAM
- At the time of release the first NV20 based cards will be equipped
with the memory working at 250 (500) MHz
- Peak bandwidth of the memory bus at 250 MHz: 8 GBytes/sec
- Supported local memory size: up to 128 MBytes (the first cards,
as our sample, will have 64 MBytes)
- RAMDAC: 350 MHz
- Max resolution: 2048x1536@75 Hz
- Integrated TMDS transmitter allows connecting digital monitors
and supports resolution up to 1600x1200
- External bus interface: full support of AGP x2/x4 (including
SBA, DME and Fast Writes) and PCI 2.2 (including Bus mastering).
- Hardware T&L: effective performance around 40+ million
triangles per second (our sample has a bit lower than 40 million
triangles per second at a special synthetical test)
- Full hardware support for all MS DirectX 8.0 and OpenGL 1.2
possibilities
- Full support for hardware VertexShaders DX8, 1.1 version
- Full support for hardware PixelShaders DX8, 1.0 version
- Support for volume textures
- Support for Cube environment mapping
- Support for projective textures
- Support for hardware tesselation of smooth surfaces (rectangular
and triangular patches)
- Hardware support for relief texturing of the following types:
Embosing, Dot Product3 and EMBM (at last!)
- Support for S3TC and all 5 DXTC texture compression methods
- Support for primitive clipping in arbitrary set planes
- Support for FSAA (with OGMS MultiSampling)
- Support for memory bandwidth saving based
on compressed Z-buffer
- Support for HSR (early Z test)
- Support for textures up to 4096x4096 @ 32 bit
Even a fleeting glance allows to conclude that
in the NV20 there is a completely new architecture that provides
a full hardware support of the DirectX 8.0. I can even state that
the DX8 support comes in time, this fact seems to be used as a basis
when promoting the NV20 and cards based on it.
NVIDIA didn't take a way of direct power increase
(e.g. extension of the number of rendering pipelines). On the contrary,
the engineers tried to do their best to realize a new architecture
allowing full hardware support for DX8, but at the same time without
a considerable increase in the number of transistors in the chip.
Plus 0.15 micron technological process that makes possible to accommodate
around 60 million transistors on the chip without making its size
gigantic. A quick shift to the NV20 guarantees that NVIDIA has very
good relations with vendors and reliable channels of memory supply
together with the GPU. The reference design of cards for the NV20
doesn't differ much from the PCB design for the GeForce2 - memory
chips are several mm shifted to the graphics core, and the position
of power stabilizers has changed a bit. The DDR memory is available
in industrial range that's why there is nothing to worry about.
The NV20 graphics core frequency and number of
pixel pipelines and texture blocks
correspond to the GeForce2 series chips. It means that the potential
pixel fillrate of the NV20 based card will be equal to that of the
GeForce2 based cards, but it's not a tragedy. In fact the problem
of all GPU, starting from the GeForce 256, concludes not in the
potential fillrate, but in the effective (real) fillrate, which
is directly connected with the local memory bandwidth. It is exactly
a local memory that turns to be a bottleneck of all modern graphics
accelerators. So I think that it's right of NVIDIA that took a way
of increasing the architecture effectiveness instead of just a direct
power extension.
Another interesting feature of the NV20 concludes
in 4 textures per pixel, what will allow to reveal a potential of
programmable shaders lifting 3D realism on a completely new level.
But being limited by the memory bandwidth,
the chip developers didn't spend transistors realizing 4 texture
blocks per each pixel pipeline. They took another way: they allowed
keeping the results of working of two texture blocks for combining
with results received at the following clock. It means that with
usage of 3 or 4 textures the maximum reached performance falls twice.
But in real applications, where everything is limited by a memory
bandwidth, the punishment won't be so severe.
As to a video memory - nothing new. Probably
full value drivers for the NV20 will weaken undesirable effects
connected with limitation of the memory bus bandwidth at the expense
of activation of special schemes, e.g. deferred texturing, hierarchical
z-buffer etc. There is only left to get the final samples of the
NV20 based cards, the release version of drivers and to check it
in practice.
Let's digress a bit to
recall the XBox. The official specs of the X-Box sound amazing:
the pixel fillrate corresponds to 4000 million pix/sec! Frequency
of the graphics core used in the XBox of the NV2A will be around
250 MHz. Even considering 8 pixel pipelines we won't get this figure
(250*8=2000 million pixels). But 8 pipelines are unlikely - the
XBox memory bandwidth won't be sufficient, in the current specification
it's around 6.4 GBytes/sec, therefore they are again 4. Moreover,
it's known that NV2A has 2 texture modules per pixel pipeline. Where
is this figure from? In fact, we are talking about 4x Multi-Sample
mode. There, 4 positions correspond to one received color value,
it means that fillrate increases 4 times as compared with cards
that don't support Multi-Sample mode hardwarely. This is what Microsoft
and NVIDIA are doing while advertising their new products.
You know that you can increase
the value of effective fillrate - without usage of new or/and expensive
memory technologies - only with usage of modified algorithms of
primitive rendering which reduce requirements to its bandwidth.
It's obvious that future games will greater rely on T&L and
hardware removal of hidden surfaces than on their own effective
algorithms. Besides, the increased complexity of models will extend
the OverDraw. In the NV20 they realized a simple hardware support
for HSR (early revision of Z). It's effeciency greatly depends on
the scene transferred to the accelerator. If the primitives are
sorted in the order of moving off from the observer, this will allow
decrease the necessity considerably in calculation of hidden pixels
of the primitives, the effective fillrate will rise several times.
Besides, the NV20 is equipped with Z-buffer compression. And according
to the data received, it's a bit different algorithm than an hierarchical
Z, but the compressed buffer is divided into tiles which are read,
recorded, processes and cached in a chip wholly. We are only to
wait until the final samples of the cards on the NV20, release version
of drivers and to check the effectiveness of these possibilities
with real games.
Besides, it's doubtful that MS would decide on
usage of such exotic and therefore expensive memory types. Where
is this figure from? In fact it concerns an effective fillrate -
the NV2A (and probably the NV20) will be supplied with an algorithm(s)
allowing to optimize the process of rendering - not to show invisible
pixels. It's likely to be some combination of the hierarchical Z
buffer and one more method of hidden surface removal. There is a
sound ground for counting on special modified algorithms which reduce
the requirements to the video memory bandwidth. Without new and/or
expensive technologies you can lift an effective fillrate only with
usage of modified algorithms of primitives' shading that reduces
requirements to its bandwidth.
So, now we will show where the claimed 4000 million
pix/sec for XBox come from. The OverDraw factor of many modern games
exceeds 2-4. For example, in case of movements it reaches 3 in Quake3,
and 6 (!) in Unreal. But remember that everything depend on effective
realization of hidden primitive removal. It's unlikely that the
technique used in the NV2A will throw out 100% hidden pixels. So,
for 4 pipelines and 60% effectiveness we have the OverDraw around
6. This figure is the most possible, and it served a basis for calculation
of the XBox specs. It's clear that the number of necessary pipelines
(with the OverDraw fixed) will directly depend on the effectiveness
of algorithms of hidden pixel removal! A good algorithm will require
only 4 pixel pipelines. Games of the future, to be created taking
into account the XBox and DX8, will in greater degree rely on T&L
and hardware hidden surface removal than on its own effective algorithms.
Besides, an increased complexity of models will additionally lift
the OverDraw. But nevertheless, remember that 4000 million pix/sec
is a relative figure and it can be reached only in theory. Meanwhile,
a question whether those tricks are realized in the NV20 and how
much they are effective remains open.
Now comes the HW T&L unit - its performance
in comparison to the GeForce2 considerably increased, and undoubtedly
in the NV20 there used an effective scheme of vertex cache and a
mechanism of conversion and implementation of the lists of vertices
and primitives stored in the local memory, without an access the
main memory of the system at all. These measures allowed to minimize
(and in the second case to avoid completely) limitations connected
with AGP bus bandwidth. The more powerful T&L will let us get
almost twice gain in games. Especially it will be well noticeable
in games intended for the API DX 8.0 - there we will get high detailing
and effects based on shaders. It concerns also the games which are
prepared for the XBox release, and they will work successfully on
the NV20 and following accelerators of the "generation X" 8.0. Old
games will have practically the same speed as on the GeForce2-family.
Some increase in the form of fps growth will have a place in all
games which will be able to use HW T&L, e.g. Quake3, but only
at low resolutions.
NVIDIA counts on the fact that new effects and
possibilities will make people buy new NV20-based cards. And the
XBox will help in doing that. It will provoke games of new visual
level to appear, and PC users will reach for it buying practically
all accelerators identical to the XBox (considering games). It's
a real chance not only to sell a huge number of NV2A but also new
expensive NV20-based cards.
For enthusiasts
Now comes the internal potential of the NV20 (and
consequently the NV2A). New possibilities of the NV20 are tightly
connected with the DX8. Here is a comparable table:
| Parameter |
NVIDIA NV20
driver of the 7 series |
Radeon DDR
driver of the 5 series |
NVIDIA GeForce2 Ultra
driver of the 7 series |
| Max Texture Size |
4,096*4,096
|
2,048*2,048
|
2,048*2,048
|
| Max Textures Count |
4
|
3
|
2
|
| Point Sprites |
hardware,
scalable (64x)
|
hardware(?),
non-scalable
|
emulation, non-scalable
|
| Max Texture Stages |
8
|
| Max Simultaneous Lights |
| Max Clip Planes |
8
|
6
|
0
|
| Max Vertex Blend Matrices |
4
|
2
|
| Max Primitive Count / Max Vertex Index |
16,777,215
|
65,535
|
| Vertex Shader Version |
1.1
|
0.0
|
| Max Vertex Shader Const |
96
|
0
|
| Pixel Shader Version |
1.0
|
0.0
|
| Quintic/RT Patches |
Y/Y
|
N/N
|
| W Depth Values |
Yes
|
| Stencil Buffer |
| Anisotropy Filtering |
| Cubic Texturing |
| Volume Texturing |
Yes
|
No
|
| Z test |
No
|
Yes
|
| Shade modes |
Color and Specular Gouraud, Alpha Gouraud blend, Fog goraud
|
| MultiSample (MS) Types |
2x, 4x MS
with OGMS AA
|
No
|
No
|
| SuperSample (SS) Types |
No
|
OGSS AA
|
OGSS AA
|
| Z/MIPMAP Bias |
Y/Y
|
| Vertex/Table/Range Fog |
Y/Y(Emulation?)/Y
|
Y/Y/Y
|
Y/Emulation/Y
|
| W/Z Fog |
Y/Y
|
| Bandwidth Saving |
Early Z test / Compressed
Z
|
Hierarhical optimized
Z
|
No
|
If you haven't stopped reading
So, the comments:
- Max Texture Size - no comments.
- Max Textures Count - max number of textures
used in forming of the one pixel. In the DX8 it is a max number
of textures that can be used simultaneously in different texture
stages of the pipeline.
- Point Sprites - support for point sprites
intended for quick rendering of particles. For more detailed info
see our DirectX
8.0 FAQ. Scalable sprites can change their size, non-scalable
are always shown 1:1. Without a special hardware support the sprites
are emulated with two small triangles what brings to nought their
potential gain (high speed of rendering).
- Max Texture Stages - pipeline length,
i.e. the number of operations that can be used for color forming
of the net pixel from the source parameters (color of the selected
texture points, values of transparency and light of vertices interpolated
along the triangle surface, relief parameters etc.). In case of
shader support the number of texture stages can define the length
of a shader's program. At least, a length of a program implemented
effectively, without a delay. Each standstill of a pipeline (in
case an architecture would let it) leads to performance fall.
One standstill - and shading goes twice slower, two - three times,
etc. That's why all shader accelerators of the first wave will
limit themselves with shaders which length is no more than the
number of texture stages. A bit later we will discuss shaders,
and now comes a table of operations possible at each stage:
NVIDIA NV20
driver of the 7 series |
Radeon DDR
driver of the 5 series |
NVIDIA GeForce2 Ultra
driver of the 7 series |
DISABLE
SELECTARG 1
SELECTARG 2
MODULATE
MODULATE 2X
MODULATE 4X
ADD
ADDSIGNED
ADDSIGNED 2X
SUBTRACT
ADDSMOOTH
BLENDDIFFUSEALPHA
BLENDTEXTUREALPHA
BLENDFACTORALPHA
BLENDTEXTUREALPHAPM
BLENDCURRENTALPHA
PREMODULATE
MODULATE ALPHA_ADDCOLOR
MODULATE COLOR_ADDALPHA
MODULATEINVALPHA_ADDCOLOR
MODULATEINVCOLOR_ADDALPHA
BUMPENVMAP
BUMPENVMAPLUMINANCE
DOTPRODUCT3
MULTIPLYADD
LERP
|
DISABLE
SELECTARG 1
SELECTARG 2
MODULATE
MODULATE 2X
MODULATE 4X
ADD
ADDSIGNED
ADDSIGNED 2X
SUBTRACT
BLENDDIFFUSEALPHA
BLENDTEXTUREALPHA
BLENDFACTORALPHA
BLENDTEXTUREALPHAPM
BLENDCURRENTALPHA
MODULATEALPHA_ADDCOLOR
MODULATECOLOR_ADDALPHA
MODULATEINVALPHA_ADDCOLOR
MODULATEINVCOLOR_ADDALPHA
BUMPENVMAP
DOTPRODUCT3
MULTIPLYADD
LERP
|
DISABLE
SELECTARG 1
SELECTARG 2
MODULATE
MODULATE 2X
MODULATE 4X
ADD
ADDSIGNED
ADDSIGNED 2X
SUBTRACT
ADDSMOOTH
BLENDDIFFUSEALPHA
BLENDTEXTUREALPHA
BLENDFACTORALPHA
BLENDTEXTUREALPHAPM
BLENDCURRENTALPHA
PREMODULATE
MODULATEALPHA_ADDCOLOR
MODULATECOLOR_ADDALPHA
MODULATEINVALPHA_ADDCOLOR
MODULATEINVCOLOR_ADDALPHA
DOTPRODUCT3
|
| All these operations are possible
when a stage is intended for processing of color or alpha
value (besides, the stage can be used for interpolation or
loading of the corresponding parameter from texture/vertices
etc.) |
So, what these operations do:
- DISABLE - prohibits working (giving out
of the results) beginning from the current pipeline stage and
further.
- SELECTARG1 (or 2) - the result of this
stage is one of its input parameters (nowise modified)
- MODULATE - the result is multiplication
of the input parameters. Out=In1*In2
- MODULATE2X (or 4X) - the same, plus scaling,
Out=(In1*In2)*2 or *4, correspondingly
- ADD - adding Out=In1+In2
- ADDSIGNED - adding with a sign Out=In1+In2-0.5
- ADDSIGNED2X - adding with a sign and scaling
Out=(In1+In2-0.5)*2
- SUBTRACT - Out=In1-In2
- ADDSMOOTH - trick adding with combination
Out=In1+In2*(1-In1)
- BLENDDIFFUSEALPHA,
BLENDTEXTUREALPHA,
BLENDFACTORALPHA,
BLENDCURRENTALPHA - alpha blending of parameters
with usage of one of 4 possible Alpha values (taken from the previous
stage CURRENT, a value FACTOR
taken from vertices and interpolated along the triangle surface,
value from TEXTURE or constant value DIFFUSE.
Correspondingly, Out=In1*Alpha+In2*(1-Alpha)
- BLENDTEXTUREALPHAPM - special type of
alpha blending, Alpha value is taken from the texture. Out=In1+In2*(1-Alpha)
- PREMODULATE - modulates the result of
the current stage with the result of the following one (e.g. used
for creating of flashes).
- MODULATEALPHA_ADDCOLOR - modulates the
color of the second parameter with alpha of the first. Out=In1RGB+In2RGB*In1Alpha
- MODULATECOLOR_ADDALPHA - multiplies colors
and adds alpha Out=In1RGB*In2RGB+In1Alpha
- MODULATEINVALPHA_ADDCOLOR,
MODULATEINVCOLOR_ADDALPHA - the same as the
two previous, correspondingly, but instead of Alpha there used 1-Alpha
- BUMPENVMAP - per-pixel EMBM, the result
of the following stage serves an environment map. See further
for description of texture formats, there are special formats
for keeping maps of altitude/bias for setting relief.
- BUMPENVMAPLUMINANCE - the same but allowing
for lighting factor also kept in relief's texture.
- DOTPRODUCT3 - the most honest per-pixel
relief type. In fact, a scalar product of two vectors allowing
for signs the components of which are located in RGB of input
parameters. In1R*In2R+In1G*In2G+In1B*In2B
- MULTIPLYADD - popular operation Out=In1+In2*In3
- LERP - linear interpolation Out=(In1)*In2+(1-In1)*In3
On a based of this mechanism one can program
many effects with usage of different number of textures. But the
fact that different accelerators support different number of operations
discredits much this mechanism of effects' control (NV20 is capable
of everything, Radeon is a good boy, and the GeForce2 lags too far
behind them). Anyway, pixel shaders are more flexible and convenient
tool.
We continue with comments on the table:
- Max Simultaneous Lights - max number of
light sources processed hardwarely. 8 is already a standard. But
realizations, according to the test results which reveal dependence
of performance decrease on light sources, are different. Let's
see what possibilities in hardware calculation of lighting and
geometry are provided by our cards:
NVIDIA NV20
driver of the 7 series |
Radeon DDR
driver of the 5 series |
NVIDIA GeForce2 Ultra
driver of the 7 series |
DIRECTIONALLIGHTS
LOCALVIEWER
MATERIALSOURCE7
POSITIONALLIGHTS
TEXGEN
|
DIRECTIONALLIGHTS
LOCALVIEWER
MATERIALSOURCE7
POSITIONALLIGHTS
TEXGEN
|
DIRECTIONALLIGHTS
LOCALVIEWER
POSITIONALLIGHTS
TEXGEN
|
Cooments:
- DIRECTIONALLIGHTS - support for infinitely
far light sources, which are set only by direction
- POSITIONALLIGHTS - support for pixel and
conic sources
- LOCALVIEWER - support of calculation in
local coordinates
- MATERIALSOURCE7 - you may choose a light
source of vertices of a primitive
- TEXGEN - hardware generation of texture
coordinates
OK, let's return to the main table:
- Max Clip Planes - a number of planes set
by a user for clipping primitives. The plane is determined with
4 factors (ABCD) and if for the primitive's coordinates the term
(Ax + By + Cz + Dw >= 0 (w - quaternary coordinate) is implemented
, the primitive is clipped and doesn't proceed to rendering. There
is an obvious fall of the GeForce2. And an interesting redundancy
in case of the NV20 - even an arbitrary cubic sector can be set
with 6 planes.
- Max Vertex Blend Matrices - max number
of matrices simultaneously applied to a vertex at the time of
multimatrix coordinate blending. In DX7 matrix blending (single-skin)
with 4 matrices was possible. Unfortunately, the GeForce/GeForce2
support only two. In the DX8 you can use a set up to 256 matrices,
with 4 matrix limitation for one vertex, they are chosen with
an index. But drivers of the NV20, Radeon and GeForce2 today do
not support such indexing.
- Max Primitive Count / Max Vertex Index
- all these accelerators can interpret, transform, light and render
lists of primitive tremendously unloading a CPU. This parameter
defines a max size of a list of primitives or vertices.
- Vertex Shader Version - for a start comes
an illustration from the DX8 SDK documentation:
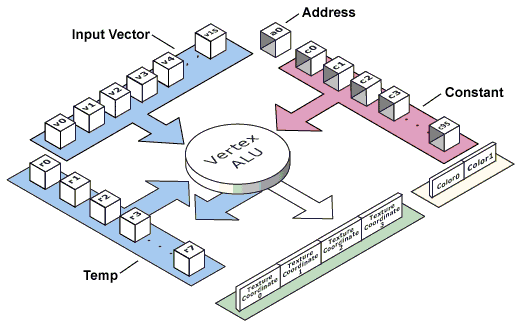
Here you can see a black box - version 1.1 of the
NV20, which is lacking in the Radeon and GeForce2. In fact, the
Radeon and GeForce2 have the Vertex ALU which can interpret shaders,
though they are not completely compatible with the final standard.
You can say that these shaders are of 0.5 version. By the way, for
the Radeon they can be switched on with a special key in the register,
but in this case the most of the samples from the DX8 SDK will buzz,
and only some shaders will be implemented as they should do. It's
because the compatibility is partial. However that may be, Microsoft
didn't introduce a conception of shaders of "0.5 version", and we
will hold it only for the NV20. So, shaders deals with constants
(next line of the table defines their number - Max
Vertex Shader Const), for the NV20 they are 96. With 16 input
and 8 variable (temporary) registers. When the shader's operation
is working (the size of which for the NV20 is limited with 128 ops,
but it differs with other chips) data are operated and on this base
there created 4 sets of coordinates for textures and two color values
for a vertex and the resulting vertex coordinates. A pixel shader
or a chosen (by a user) configuration of texture stages further
work with these data (while rendering a primitive):
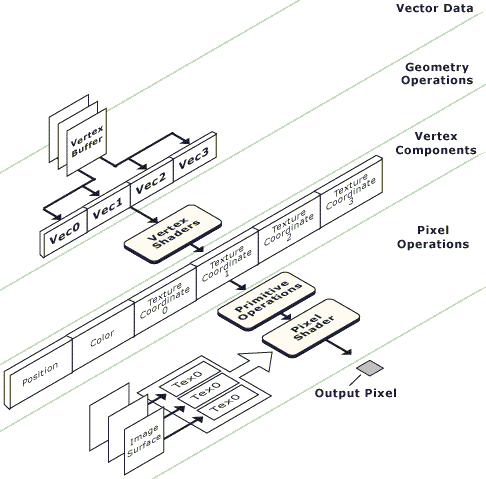
I'm not going to touch the performance of this
unit. I just want to notice that it's very easy to make a parallel
unit processing several vertices simultaneously, implementing in
fact one shader's program. I think that it works this way here.
By the way, when using a shader many constants
are available (96 for the NV20). Nothing prevent us from writing
a shader that would realize a blending with arbitrary degree of
flexibility, e.g. with usage of 96/4 matrices. But remember about
a restriction on the number of shader's operations. Taking this
into account we will get ~20 matrices per vertex. Though, in case
of one skip it's useless.
Again comes the main table:
- Pixel Shader Version - this is the second
type of shaders. Enabling pixel shaders with the Radeon, you may
see that a situation is more optimistic this time. It seems that
what it has in the hardware is very close to the 1.0 version,
and many samples from the DX8 works well. For those who want to
experiment, here are the keys for the Radeon:
HKEY_LOCAL_MACHINE\SOFTWARE\ATI_Technologies\Driver\0000\atidxhal
(instead of 0000 it can be 0001 etc.)
string VertexShaderVersion = "10"
(nearly all parameters using it buzz)
string PixelShaderVersion = "10"
(it works better, you can see nearly all examples in hardware
implementation)
string PureDevice = "1" - enables
"PURE device" mode
In this mode (the fastest) an accelerator stores, converts and
implements lists of primitives and vertices in local memory.
A place of pixel shaders in the general shade picture:
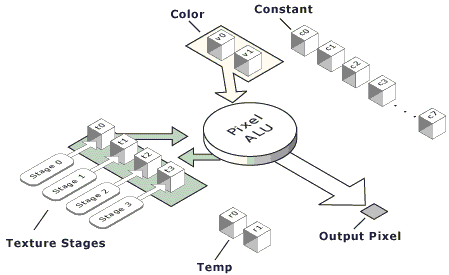
Simple but tasteful. A shader is calculated in
every shaded point of a triangle, it should be implemented max quickly.
There are 8 constants, two colors (interpolated along a surface
of a primitive), texture stages which we can interact with. There
are two temporary registers. The problem is to calculate the resulting
color of the pixel. There are a huge number of operations available
which are similar to the described above for calculations at the
texture stage, but more flexible. The operations can work in several
directions simultaneously. Their max number is equal to the number
of texture stages (for the NV20 they are only 8). A pixel shader
is rather a setting of pipeline stages. And it is implemented more
effectively giving out one result per clock. And again nothing hampers
parallel living of several pipelines in the hardware which are set
equally.
Well, again the main table:
- Quintic/RT Patches - hardware support
for tesselation of smooth surfaces! There are added two new primitives
of high order - rectangular and triangular patches. For their
rendering there are two corresponding calls in the DX8, and you
can control the degree of detailing when dividing smooth surfaces
of patches into triangles. It seems that the NV20 implements tesselation
hardwarely. Maybe the result of tesselation is kept in the local
memory of an accelerator in the form of a resulting list of the
triangular primitives, or parameters of a triangle are generated
dynamically and immediately go to rendering without being anywhere
saved. In the second case, the work of a programmer becomes simpler
and memory load is decreased.
- W Depth Values - support of an alternative
format of depth values (W format).
- Stencil Buffer - support for Stencil buffer.
Accelerators can implement the following operations with Stencil
buffer values:
NVIDIA NV20
driver of the 7 series |
Radeon DDR
driver of the 5 series |
NVIDIA GeForce2 Ultra
driver of the 7 series |
KEEP
ZERO
REPLACE
INCRSAT
DECRSAT
INVERT
INCR
DECR
|
KEEP
ZERO
REPLACE
INCRSAT
INVERT
DECR
|
KEEP
ZERO
REPLACE
INCRSAT
DECRSAT
INVERT
INCR
DECR
|
Detailed info on operations:
- KEEP - not to change a value in the buffer
- ZERO - set 0 in all rendered pixels of
the primitive
- REPLACE - record some definite value
- INCRSAT - increase by one. If case the
maximum reached, the value are not to be changed.
- DECRSAT - decrease by one. On reaching
0 do not change it.
- INCR, DECR - the same but with return.
For example, when the maximum is reached the value is set to 0
Now comes the main table again:
- Anisotropy Filtering - It seems that in
the NV20 it's realized the same way as in the GeForce2, and looks
worse than that of the Radeon. A bit later we will give a table
with all accessible filtering modes for different texture types.
- Cubic Texturing - hardware support of
cubic texturing (cube environment mapping).
- Volume Texturing - hardware support for
volume texturing.
Here comes a table with possible filtering modes
for three possible texture types, with usage of MIP levels and without:
| Filtering |
NVIDIA NV20
driver of the 7 series |
Radeon DDR
driver of the 5 series |
NVIDIA GeForce2 Ultra
driver of the 7 series |
| Standard Texture Filters |
| Min/Mag |
Point, Linear, Anisotropic
|
| MIPMAP |
Point, Linear
|
| Cube Texture Filters |
| Min/Mag |
Point, Linear, Anisotropic
|
Point, Linear
|
Point, Linear, Anisotropic
|
| MIPMAP |
Point, Linear
|
No
|
Point, Linear
|
| Volume Texture Filters |
| Min/Mag |
Point, Linear, Anisotropic
|
Point, Linear
|
No
|
| MIPMAP |
Point, Linear
|
No
|
No
|
Here the NV20 takes the lead...
Let's return to the parameters:
- Z test - a possibility to inform after
rendering of a primitive whether at least one its pixel can be
seen
- Shade modes - There all three cards are
equal.
- MultiSample Types
- possible modes of multisampling. Only of the NV20.
- SSAA (Super
Sample Anti-Aliasing) Types - possible modes of full screen AA.
- Z/MIPMAP Bias - possibility of biasing
of MIP level or a depth.
- Vertex/Table/Range Fog - supported types
of fog.
- W/Z Fog - possible depth formats for the
fog.
- Bandwidth Saving - methods of saving
of memory bandwidth.
Look at a table with texturing parameters:
NVIDIA NV20
driver of the 7 series |
Radeon DDR
driver of the 5 series |
NVIDIA GeForce2 Ultra
driver of the 7 series |
PERSPECTIVE
POW2
ALPHA
ALPHAPALETTE
PROJECTED
CUBEMAP
VOLUMEMAP
MIPMAP
MIPVOLUMEMAP
MIPCUBEMAP
CUBEMAP_POW2
VOLUMEMAP_POW2
|
PERSPECTIVE
POW2
ALPHA
PROJECTED
CUBEMAP
VOLUMEMAP
MIPMAP
CUBEMAP_POW2
VOLUMEMAP_POW2
|
PERSPECTIVE
POW2
ALPHA
PROJECTED
CUBEMAP
MIPMAP
MIPCUBEMAP
CUBEMAP_POW2
|
Comments:
- PERSPECTIVE - hardware correction of perspective.
- POW2, CUBEMAP_POW2,
VOLUMEMAP_POW2 - textures of the corresponding
type should have the size equal to the power of 2.
- MIPMAP - support of mipmap texturing for
standard textures
- CUBEMAP, VOLUMEMAP - support for cube
environment maps and volume textures correspondingly
- MIPVOLUMEMAP, MIPCUBEMAP - the same, plus
mipmap levels. The NV20 excelled here again.
- ALPHA - support for alpha channels in
a texture and
- ALPHAPALETTE - in a palette correspondingly.
And at last, possible formats for frame buffers,
depth buffers and different types of textures:
NVIDIA NV20
driver of the 7 series |
Radeon DDR
driver of the 5 series |
NVIDIA GeForce2 Ultra
driver of the 7 series |
| Depth/Stencil Formats |
D24S8
D16
D24X8
|
D32
D24S8
D16
D24X8
|
D24X8
D24S8
D16 (standart/lockable)
|
| Render Target Formats |
A8R8G8B8
X8R8G8B8
R5G6B5
X1R5G5B5
|
A8R8G8B8
X8R8G8B8
R5G6B5
A1R5G5B5
A4R4G4B4
R3G3B2
|
A8R8G8B8
X8R8G8B8
R5G6B5
X1R5G5B5
|
| Texture Formats |
A8R8G8B8
X8R8G8B8
R5G6B5
X1R5G5B5
A1R5G5B5
A4R4G4B4
P8
V8U8
L6V5U5
X8L8V8U8
Q8W8V8U8
DXT1
DXT2
DXT3
DXT4
DXT5
|
A8R8G8B8
X8R8G8B8
R5G6B5
X1R5G5B5
A1R5G5B5
A4R4G4B4
R3G3B2
V8U8
DXT1
DXT2
DXT3
DXT4
DXT5
|
A8R8G8B8
X8R8G8B8
R5G6B5
X1R5G5B5
A1R5G5B5
A4R4G4B4
P8
DXT1
DXT2
DXT3
DXT4
DXT5
|
| Cube Texture Formats |
A8R8G8B8
X8R8G8B8
R5G6B5
X1R5G5B5
A1R5G5B5
A4R4G4B4
P8
V8U8
L6V5U5
X8L8V8U8
Q8W8V8U8
DXT1
DXT2
DXT3
DXT4
DXT5
|
A8R8G8B8
X8R8G8B8
R5G6B5
X1R5G5B5
A1R5G5B5
A4R4G4B4
R3G3B2
DXT1
DXT2
DXT3
DXT4
DXT5
|
A8R8G8B8
X8R8G8B8
R5G6B5
X1R5G5B5
A1R5G5B5
A4R4G4B4
P8
DXT1
DXT2
DXT3
DXT4
DXT5
|
| Volume Texture Formats |
A8R8G8B8
X8R8G8B8
R5G6B5
X1R5G5B5
A1R5G5B5
A4R4G4B4
P8
R5G6B5
|
A8R8G8B8
X8R8G8B8
R5G6B5
X1R5G5B5
A1R5G5B5
A4R4G4B4
R3G3B2
DXT1
DXT2
DXT3
DXT4
DXT5
|
-
|
Comments on texture and buffer
formats:
- The letters mean the type of data stored (e.g.
R/G/B - color components). A digit after a letter - number of
bits (R8G8B8 True color)
- RGB - color components.
- D - depth in the Z or W format
- A - alpha channel, i.e. transparency
- X - unused value
- DXT1..5 - compressed textures (by the corresponding
method)
- QWUV - relief parameters (BumpMap)
- L - light
- P - index in a palette
Well, the NV20 turned out well in possibilities
(unlike the GeForce2). NVIDIA company proves its rank of a technological
leader.
It's not clear up what will be with a speed,
many things will depend on memory and programmers. I want to note
a tighter integration of the API (DX8) and hardware and wide range
of technological innovations. It's obvious that together with the
XBox the NV2x series is capable to provoke a real revolution of
trick effects in games. The main thing is that game developers manage
to create new games or remake the current ones; it's cool that the
upcoming XBox guaranties availability of games intended for the
API DX8 possibilities.
Expected that the first NV20-based cards will
be released by ASUS, Leadtek, Elsa, Hercules in March, and in April-May
there will come GigaByte, MSI and many others.
In the very beginning of sales the NV20 based cards
with 64 MBytes will cost around $450-500, but a month later the
price will little by little come down. Interestingly
is the fact that in the roadmaps of many respected companies there
are only the cards with 128 MBytes memory.
Write a comment below. No registration needed!















