 |
||
|
||
| ||
|
||
|
||
| ||
First of all, let me explain who this article is meant for. I started this article after ENTEREX'2002 held in Kiev where I saw that cluster systems began attracting much more attention than it was before. In this article I'm not going to analyze variants of solving certain applied problems on cluster systems. My aim is to focus on the terminology and means of assembling cluster systems and to show for which problems the clustering is useful. I will also give some examples of realization of cluster systems, as well as my contact information so that you can ask questions connected with cluster technologies and make comments. Conception of cluster systems
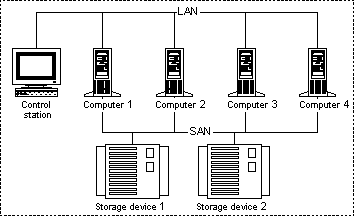 Figure 1. Cluster system
The concept of cluster was first defined by Digital Equipment Corporation (DEC). According to DEC, cluster is a group of computers which are interconnected and function as one information processing unit. A cluster works as a single system, i.e. for a user or an applied problem all pieces of computer facilities are seen as one computer. This is the most important thing in arrangement of a cluster system. The first clusters of Digital were built on VAX machines. Today such computers are not produced anymore, though they still work on the platforms where they were installed many years ago. Their general principles remain a base for today's cluster systems. Here are the main requirements for cluster systems:
In certain cases, some of the requirements are put on the head of the list, and the others become of less importance. For example, in case of a cluster when efficiency is the most important factor, high availability is paid less attention to to save on resources. In general, a cluster works as a multiprocessor system, that is why it's important to understand the classification of such systems within the frames of soft hardware resources.
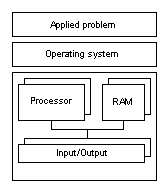 Figure 2. Tightly linked multiprocessor system
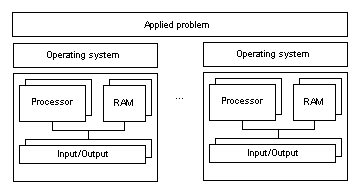 Figure 3. Moderately linked multiprocessor system
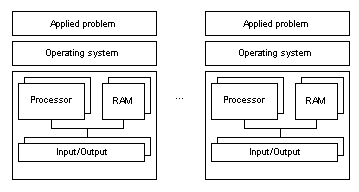 Figure 4. Weakly linked multiprocessor system Usually PC platforms I works with have tightly linked and moderately linked multiprocessor architectures. High Availability and High Performance systemsAccording to the functional classification, clusters can be divided into High Performance (HP), High Availability (HA) and Combined Systems. High-performance clusters are used for problems which require considerable processing power. Here are typical fields where such systems are used:
and many others... HA clusters are used when cost of possible downtime exceeds cost of inputs necessary to build a cluster system, for example:
Combined systems have peculiarities of both classes. Note that a cluster which possesses parameters of both High Performance and High Availability systems definitely yields to HP system in performance and HA systems in possible downtime. Problems of High Performance clusters
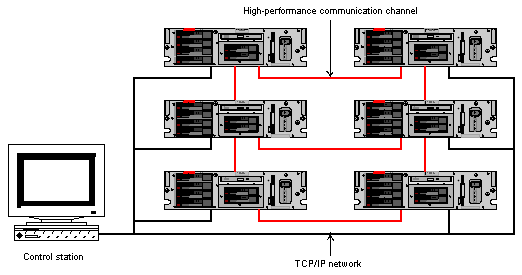 Figure 5. High-performance cluster Almost in any problem which uses parallel computation it's impossible to avoid necessity to transfer data from one subtask to another. Efficiency of a High-Performance cluster system depends on efficiency of nodes and connections between them. Influence of speed parameters of the connections on the overall performance depends on a character of a task. If a certain task requires frequent data exchange with other subtasks the efficiency of the communication interface must be paid much attention to. The less the parts of a parallel task interact, the less time is needed to accomplish it. It also puts certain requirements for programming of parallel tasks. The main problem when subtasks exchange data is connected with the fact that a data rate between a central processor and RAM of a node is much higher than speeds of systems of intercomputer interaction. Besides, the difference in efficiency of cache memory of the processors and internodal communications affects system functioning, as compared with usual SMP systems. Efficiency of interfaces depends on a throughput of a continuous data flow and the maximum number of the smallest packets which can be transferred at a unit time. Variants of realization of communication interfaces will be given in section "Means of realization of High Performance clusters". Problems of High Availability cluster systemsToday there are several popular HA systems. A cluster system integrates technologies which provide a high level of fault tolerance at the lowest cost. Backup of all important components is what makes such cluster fault-tolerant. The best fault-tolerant system mustn't have a single point, i.e. an active element, failure of which can cause failure of the whole system. Such characteristic is called NSPF (No Single Point of Failure).
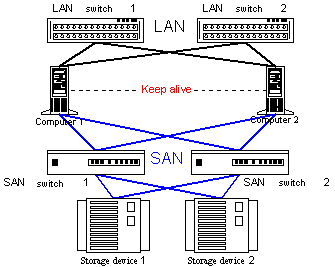 Figure 6. Cluster system with no points of failure HA systems are aimed at minimal downtime. To make a high-availability system it's necessary that:
Disregard of either parameter can cause failure of the whole system. Let's take a closer look at all three items. The maximum reliability is provided by using electronic components of high and superhigh integration, and maintaining normal operating modes, including thermal conditions. Fault-tolerance can be achieved at the expense of special components (ECC, Chip Kill memory modules, fault-tolerant power units etc.), and clustering technologies. Due to clustering if one of computers fails its problems are redistributed among other cluster nodes which function properly. One of the most important aims of cluster software developers is to make recovery time minimal because fault-tolerance is needed to minimize off-schedual downtime. Remember that serviceability which reduces planned downtimes (for example, replacement of out-of-order equipment) is one of the most important parameters of HA systems. And if a system doesn't allow replacing components without being turned off its availability coefficient reduces. Combined architectures
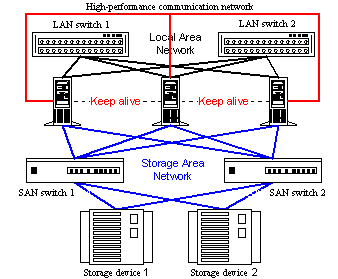 Figure 7. High-performance fault-tolerant cluster Today one can come across such cluster architectures which combine high-availability systems and high-performance cluster architectures where applied problems are distributed among nodes of the system. A fault-tolerant complex the efficiency of which can be lifted by adding a new node is considered the most optimal solution when building a computation system. But such scheme of developing of combined architectures makes it necessary to combine a great number of expensive components to provide both high efficiency and backup. As in a high-performance cluster system the most expensive component is a system of high-speed communications its backing requires great expenses. Note that HA systems are often used for OLTP tasks which function optimally in symmetrical multiprocessor systems. Such cluster systems usually consist of two nodes which, first of all, provide high availability. Today usage of more than two inexpensive systems as components for combined HA/HP cluster systems becomes a quite popular solution. Thus, not so long ago Oracle Corp. announced it was to replace three Unix servers that ran the bulk of its business applications with a cluster of Intel Corp. servers running Linux. It could eventually save millions of dollars and improve fault-tolerance. Means of realization of High Performance clustersThe most popular communication technologies for assembling supercomputers based on cluster architectures are: Myrinet, Virtual Interface Architecture (cLAN of Giganet is one of the first commercial hardware realizations), SCI (Scalable Coherent Interface), QsNet (Quadrics Supercomputers World), Memory Channel (from Compaq Computer and Encore Computer Corp) and well-known Fast Ethertnet and Gigabit Ethernet.
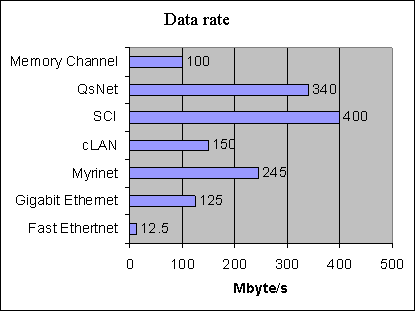 Figure 8. Continuous data flow rate
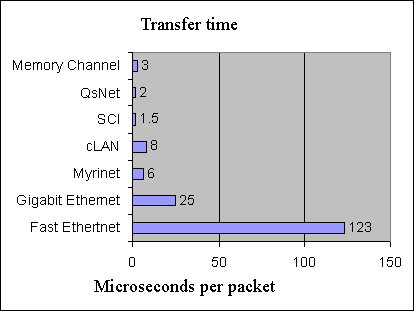 Figure 9. Zero-length packet transfer rate These diagrams (Fig. 8 and 9) show efficiency of hardware realizations of different technologies, but remember that in real tasks and in various hardware platforms the delays and data rates are 20-40% or sometimes 100% worse than the maximum possible. For example, for MPI libraries for cLAN communication cards and Intel based servers with a PCI bus an actual throughput of a channel is 80-100 MByte/sec, the delay is 20 microseconds. One of the problems which occur when a high-speed interfaces are used, for example, SCI, is unsuitability of a PCI architecture for high-speed devices of such type. But if you redesign the PCI Bridge so that it is oriented to one data transfer device, the problem can be solved. Such realizations take place in solutions of some manufacturers, for example, SUN Microsystems. So, when designing high-performance cluster systems and calculating their efficiency you should take into account performance losses related with data processing and transfer in cluster nodes. Table 1. Comparison of high-speed communication interfaces
* SCI hardware (and support software) allows building MASH topologies without using switches ** n/a
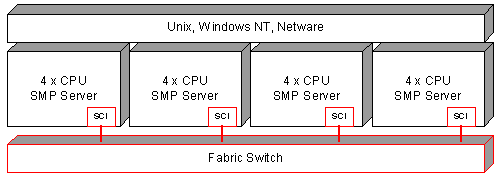 Figure 10. Tightly linked multiprocessor system with asymmetric memory access One of peculiarities of communication interfaces which provide low delays is the fact that it's possible to assemble on them systems with the NUMA architecture and systems which can model SMP systems on a software level. The advantage of such system is that you can use standard operating systems and software meant for SMP solutions, but because of a high delay (much higher than in SMP) of interprocessor interaction it won't be easy to predict efficiency of such system. Means of parallelingThere are several approaches to programming of parallel computation systems:
There are also various tools which simplify designing of parallel programs. For example:
The experience of users of high-performance cluster systems shows that programs which take into account necessity of interprocessor interaction are the most effective. And although it's more convenient to program on packets which use a shared memory interface or means of automatic paralleling, MPI and PVM libraries are the most popular today. Let's look closer at the MPI (The Message Passing Interface). MPI is a standard which is used to develop parallel programs and which uses a model of message exchange. There are MPI realizations for C/C++ and Fortran, they can be free or commercial variants for most of popular supercomputer platforms, including High Performance cluster systems build on nodes with Unix, Linux and Windows. MPI Forum is responsible for MPI standardization (http://www.mpi-forum.org). The 2.0 version of the standard describes a great deal of new interesting mechanisms and procedures for organization of functioning of parallel programs: dynamic control of processes, one-way communications (Put/Get), parallel ones I/O. Unfortunately, there are no finished full versions of this standard, though some innovations are used actively. To estimate functionality of the MPI let's look at the diagram below which shows how time of solving a linear equations set depends on the number of enabled processors in a cluster. The cluster is built on the Intel processors and a system of internodal connections - SCI (Scalable Coherent Interface). This is a particular problem, and you shouldn't take the obtained results as a general model of forecasting of performance of a desired system.
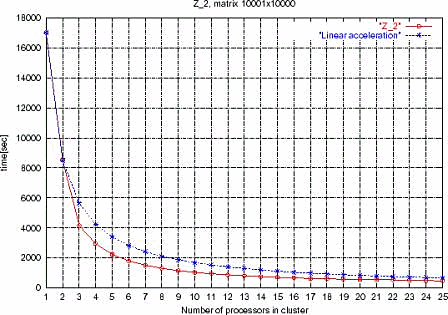 Figure 11. Dependence of time of solving a linear equations set on the number of enabled processors in a cluster The blue lines shows a linear acceleration and the red one - the experimental one. I.e. every new node gives an acceleration higher than the linear one. The author of the experiment states that such results are obtained due to a more effective usage of the cache memory. If you have any other ideas you can share them with me (svv@ustar.kiev.ua). Means of realization of High Availability clustersHigh Availability clusters can be divided into:
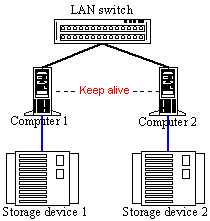 Figure 12. Shared Nothing Architecture The Shared Nothing Architecture doesn't use a shared data storage system. Each node has its own disc storage units which are not shared by nodes of a cluster system. In fact, only communication channels are shared on the hardware level.
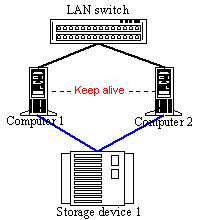 Figure 13. Shared Disk Architecture The Shared Disk Architecture is usually used for High-Availability cluster systems which are meant for processing of large volumes of data. Such system consists of the shared data storage system and cluster nodes which distribute access to shared data. In case of high power of a data storage system and tasks aimed at their processing, the Shared Disc Architecture is more effective. It's not necessary to store several copies of data, and at the same time if a node fails the tasks can immediately become available for other nodes. If a task allows dividing data logically so that a request from a certain subset of requests can be processed using a part of data, the Shared Nothing System can be a more effective solution. I think it must be interesting to build heterogeneous cluster systems. For example, the Tivoli Sanergy software makes possible to assemble systems which separate data access between heterogeneous nodes. Such solution can be very important in the systems of shared processing of video information or other data in an organization which doesn't have a required range of solutions on a single platform or which has an already formed complex of soft hardware resources needed to be used more effectively.
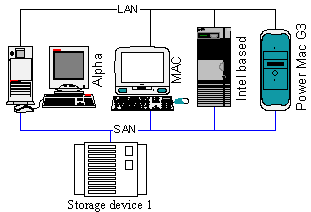 Figure 14. Heterogeneous cluster system Two-node fault-tolerant clusters are the most popular commercial systems. There are Active-Active and Active-Passive models of realization of fault-tolerant cluster systems as far as program resources distribution is concerned.
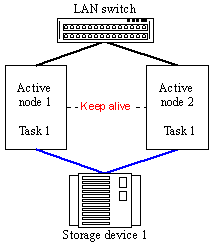 Figure 15. Active-Active Model Beside a fault-tolerant solution the Active-Active model provides for a high-performance one as one task is processed by several servers simultaneously. Such variant is realized in the Oracle Prallel Server, MS SQL 2000, IBM DB2. I.e. such model is possible if the software is meant for functioning in a cluster mode (except cluster systems which share RAM). In this model it's possible to scale a task speed by adding a new node if the software supports the required number of nodes. For example, Oracle Parallel Server 8.0.5 supports operation on a cluster of 2 to 6 nodes.
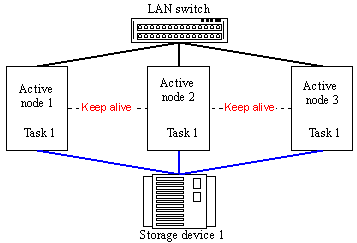 Figure 16. Active-Active cluster on 3 nodes Users often face a problem when it's necessary to provide fault-tolerant functioning of finished software solutions. Unfortunately, the Active-Active model doesn't work in this case. There must be used a model where tasks migrate from a node which fails to other nodes. This is an Active-Passive model.
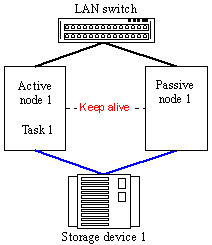 Figure 17. Active-Passive model Taking into account that in lots of cases we can't divide one task into several ones by distributing responsibility zones and there are a lot of various tasks which a firm must accomplish, there appeared a pseudo Active-Active model.
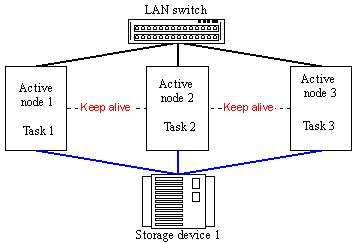 Figure 18. Pseudo Active-Active cluster on 3 nodes If you want to make several program resources fault-tolerant you must add a new node into the system and run the required tasks on the cluster which will migrate to another node if this one fails. Such model is realized in the ReliantHA software for Caldera OpenUnix and Unixware OSs which supports clustering from 2 to 4 nodes, in MSCS (Microsoft Cluster Service) and Linux Failover Cluster models. The communication system in fault-tolerant cluster systems can be based on the same equipment as used in high-performance clusters. But if the Shared Disc Architecture is used it's necessary to provide a high-speed access to the shared data storage system. This task has a lot of solutions today. In case of a simple 2-node model the discs can be accessed through their direct connection to the shared SCSI bus,
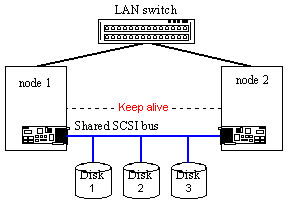 Figure 19. Architecture with the shared SCSI bus Disc or using an independent disc subsystem with an integrated SCSI to SCSI controller. In this case discs are connected to internal independent channels of the disc subsystem.
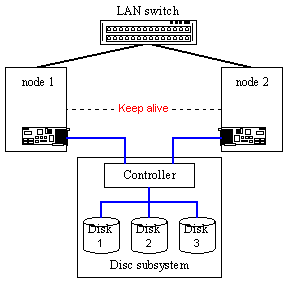 Figure 20. A model with the SCSI to SCSI disc subsystem The model with the SCSI to SCSI disc subsystem is more scalable, functional and fault-tolerant. Although there is one more stage between the node and the discs such system is usually speedier as we get a routed access to a storage device (the situation is similar to usage of a hub and a switch in a LAN). Unlike a model with shared disc access on a shared SCSI bus, a separate independent disc subsystem makes possible to build systems without points of failure and multinode configurations. Fibre Channel (FC) is a new popular serial interface for the SCSI protocol. SANs (Storage Area Network) are based on the FC interface.
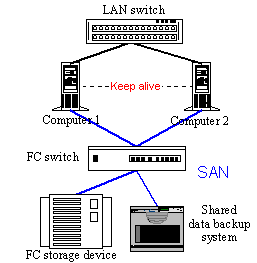 Figure 21. Cluster system with a SAN based on the Fibre Channel Almost all features of the Fibre Channel are its advantages.
The Fibre Channel was developed by experts in channel and network interface fields who managed to combine in one FC interface advantages of both. To better understand the FC let's take a look at the comparison table of the FC and a parallel SCSI interface. Table 2. Comparison characteristics of the FC and a parallel SCSI interface
Today FC devices are more expensive than devices with the parallel SCSI, but the price difference keeps on reducing. The discs and data storage devices are almost equal in price with parallel SCSI realizations, only FC adapters are still too dear. There is one more interesting model of a cluster architecture Shared Memory Cluster (including RAM). This cluster can function in a model of both a moderately linked multiprocessor system and in a tightly linked one. Such system is called NUMA.
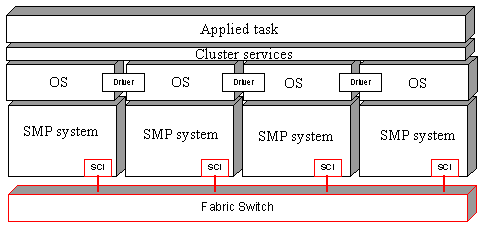 Figure 22. Shared Memory Cluster The shared memory cluster uses software (cluster services) which provides a single system image even if the cluster is built as a shared nothing architecture, as it is seen by an operating system. In conclusion of the HA cluster systems part let's look at the statistics on downtime of different systems.
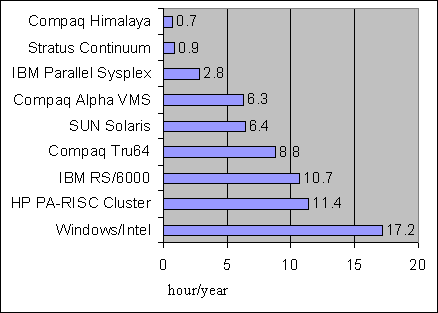 Figure 23. Comparison of average downtime of different systems Above you can see averaged data as well as data from advertising materials of one of the developers, that is why they shouldn't be trusted completely. However, they do give a general idea. As you can see, high-availability cluster systems are not a cure-all for downtime minimization. If downtime is a very important parameter, you should use Fault Tolerant or Continuous Availability systems as they have an availability factor much higher than High Availability systems. Examples of working solutionsViability of any technology can be proven with examples of its practical usage, that is why I want to show you some variants of the most important cluster solutions. First of all, let's speak about high-performance clusters. One of the most useful examples is the fact that first places, and the most of places, of the 18th edition of the list of the most powerful supercomputers belong to IBM SP2 and Compaq AlphaServer SC systems. Both are massively parallel processing systems (MPP) which are identical to High Performance cluster solutions in structure. The IBM SP2 uses RS/6000 as nodes which are connected with a SP Switch2. The throughput of the switch is 500 MBytes/s one-way, the latency is 2.5 microseconds. Compaq AlphaServer SC. Nodes are 4-processor systems of the Compaq AlphaServer ES45 type interconnected with the QsNet interface the parameters of which are mentioned earlier. The same supercomputer list contains also machines based on usual Intel platforms and SCI and Myrinet switches and on a usual Fast and Gigabit Ethernet. Both the first two variants and high-performance cluster systems based on usual equipment use MPI packets for programming. Finally, let me show you a nice example of a scalable high-availability cluster system. This is a hardware model of a cluster solution for fault-tolerant high-speed processing of IBM DB/2 data base.
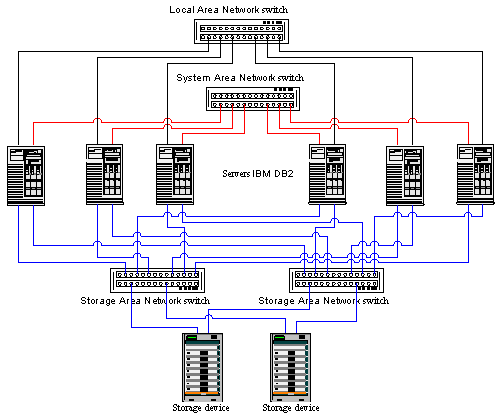 Figure 24. IBM DB2 cluster That's all. If you have any questions or comments, please, feel free to share them with me. Sources
Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. |














