 |
||
|
||
| ||
|
||
|
||
| ||
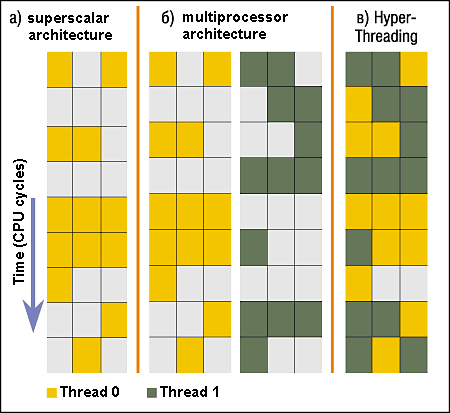
In our previous review of the Intel Xeon 2.2 GHz we wrote that usage of uni-processor Xeon systems makes no sense as at a higher price they offer the same performance as a Pentium 4 clocked at the same frequency. Now, when we have examined the issue more thoroughly, we must correct that statement. The Hyper-Threading technology realized in the Intel Xeon on the Prestonia core works and yields fruit. Though there are also some questions... How to get a performance gainThe performance race never stops, and it's difficult to say what components accelerate faster. All the time it drags in newer ways, and a lot of skilled labor and quality brains are involved in this avalanche process. A steady performance growth is, of course, needed. At least, it is a profitable business. Simultaneous speech recognition and translation into another language - isn't it that everybody dreams of? Or realistic games of almost video quality - isn't it what all gamers are striving for? But let's leave marketing aspects aside and focus on technical ones. Undoubtedly there are some tasks (server applications, scientific calculations, modeling etc.) where the performance growth, especially of CPUs, is always welcome. So, what are the ways of increasing the performance? Clock speed increase. We can "narrow" the fab process further and increase a clock speed. But, as you know, it's not simple and fraught with side effects like heat generation problems. Raising of processor resources - for example, a cache size, introduction of new execution units. All this makes for a greater number of transistors, complicates a processor, enlarges a die surface, and, therefore, makes the price higher. Besides, a performance doesn't rise linearly in these two methods. Just take a Pentium 4: errors in branch predictions and interrupts causes cleaning of a pipeline, and this affects the overall efficiency very much. Multiprocessing. Installation of several CPUs and distribution of a load among them is often effective. But such approach is not cheap - each additional processor raises the cost of the system; besides, a dual-processor mainboard is more expensive than a usual one. And there are not many applications that can gain such performance which justifies the expenses. Apart from a pure multiprocessor configuration there are some intermediate versions: Chip Multiprocessing (CMP) -- two processor cores are located on one die and use a common or separate cache. Such die turns out to be quite large, and it tells upon the price. Note that several such CPUs can also work in a multiprocessor system. Time-Slice Multithreading. A processor switches between threads in fixed time intervals. The expenses can be very high, especially if one of the processes is in the wait state. Switch-on-Event Multithreading. Task switching in case of long pauses, (for example, cache misses) a great number of which is typical of server applications. In this case waiting for data coming from a relatively slow memory into a cache stops and CPU resources are given to other processes. However, Switch-on-Event Multithreading, as well as Time-Slice Multithreading, doesn't always provide for the optimal CPU resource utilization - in particular, because of errors in branch prediction, dependence of instructions etc. Simultaneous Multithreading. In this case threads are executed on one processor simultaneously, without switching between them. The CPU resources are distributed dynamically, i.e. "if you don't use - give it to the other". This approach is the basis of the Intel Hyper-Threading technology. How Hyper-Threading worksThe current computing paradigm implies multithreading calculations. It concerns not only servers, but also workstations and desktop systems. Threads can relate to one or different applications, but there are almost always more than 1 active threads (to make sure open in the Windows 2000/XP the Task Manager and display the number of threads). At the same time a usual processor can execute only one thread at a time and must switch between them constantly. The Hyper-Threading technology was first realized in the Intel Xeon MP processor (Foster MP). Note that the Xeon MP, announced at IDF Spring 2002, uses a core similar to the Pentium 4 Willamette, has a 256 KBytes L2 cache and 512 KBytes/1 MBytes L3 cache and supports 4-processor configurations. The Hyper-Threading support is also available in the processor for workstations -- Intel Xeon (Prestonia core, 512 KBytes L2 cache) which appeared on the market earlier than the Xeon MP. We already examined dual-processor configurations on the Intel Xeon, that is why we are going to take a look at Hyper-Threading capabilities by the example of these CPUs - both theoretically and practically. However that may be, the "usual" Xeon is more convenient than the Xeon MP in 4-processor systems... The Hyper-Threading is based in the principle that at each point of time only a part of processor resources is used for execution of the program code. Unused resources can also be loaded, for example, with parallel execution of another application (or just another thread of the same application). One physical processor Intel Xeon forms two logical processors (LP) which share CPU computational resources. An operating system and applications see two CPUs and can distribute a work load between them, like in case of a normal dual-processor system.
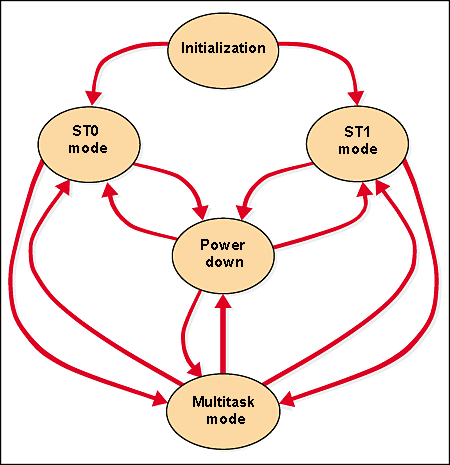
 One of the aims of the Hyper-Threading is with only one active thread to let it be executed at the same rate as on a usual CPU. That is why the processor has two main modes: Single-Task (ST) and Multi-Task (MT). In the ST mode only one logical processor is active which uses available resources completely (ST0 and ST1 modes); the other LP is stopped by the HALT instruction. When the second thread appears the second processor gets enabled (by interrupt), and the physical CPU switches to the MT mode. Halting of an unused LP is on the shoulders of an OS which is responsible for the execution of one thread be as fast as without the Hyper-Threading.
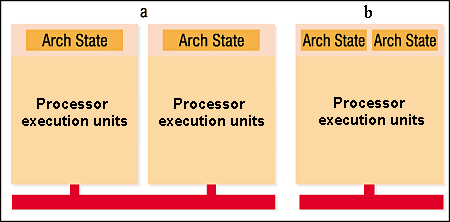
 Each of two LP has an Architecture State (AS) which includes a state of registers of different types -- of general purpose, controlling, APIC and service ones. Each LP has its own APIC (interrupt controller) and a set of registers; for their correct operation there is a Register Alias Table (RAT) which traces correspondence between 8 general-purpose registers IA-32 and 128 registers of the physical CPU (one RAT for each LP).
 When two threads are executed two Next Instruction Pointers are supported. The most part of instructions is taken from the Trace Cache (TC) where they are kept in the decode form, and two active LPs access the TC in turn, in a cycle. At the same time, when only one LP is active it doesn't share the TC access. The Microcode ROM is accessed the same way. The ITLB (Instruction Translation Look-aside Buffer) units which get enabled when required instructions are lacking in the instruction cache, are duplicated and deliver instructions for their threads. The IA-32 Instruction Decode Unit is shared, and when decoding of instructions is required for both threads, it serves them in turn (in a cycle). The Uop Queue and Allocator units are divided in two and provide half of elements for each LP. 5 schedulers process queues of decoded instructions (Uops) although they belong to LP0/LP1 and deliver instructions for execution to respective Execution Units -- depending on readiness for execution of the former ones and accessibility of the latter. Caches of all levels (L1/L2 for Xeon, and L3 for Xeon MP) are entirely shareable between the LPs, though to provide data integrity entries in the DTLB (Data Translation Look-aside Buffer) have descriptors in the form of IDs of logical processors. Thus, instructions of both logical CPUs can be executed simultaneously using resources of one physical processor which are divided into 4 classes:
The most of applications which work faster in multiprocessor systems can also speed up on the CPU with the Hyper-Threading without any modifications. But there can be problems: for example, if one of the processes is in the waiting cycle it can take all resources of the physical CPU hampering operation of the second LP. Thus, the performance with the Hyper-Threading enabled can even fall down (up to 20%). To prevent this Intel recommends to use the PAUSE instruction instead of empty waiting cycles (appeared in the IA-32 starting from the Pentium 4). Besides, automatic and semi-automatic code optimization is being worked on now - for example, the Intel OpenMP C++/Fortran Compilers series achieved a great success here (in detail). Another aim of Intel in development of the Hyper-Threading technology was to make the number of transistors, a die surface and power consumption grow much slower with a considerable efficiency increase. Well, incorporation of the Hyper-Threading into the Xeon/Xeon MP increased the die's surface and power consumption by just 5%. We are just to estimate what performance gain is obtained with it. Practical partWe didn't carry out tests of 4-processor server systems on the Xeon MP with the Hyper-Threading enabled. First of all, it's very labor-intensive. Secondly, at present, less than a month later after the official announcement, it's impossible to get the expensive equipment. That is why we had a system with two Intel Xeon 2.2 GHz processors for the first test. The system includes Supermicro P4DC6+ mainboard (Intel i860), 512 MBytes RDRAM, a GeForce3 video card (64 MBytes DDR, Detonator 21.85 drivers), Western Digital WD300BB HDD and a 6X DVD-ROM drive; and it worked under the Windows 2000 Professional SP2. When we installed one Xeon on the Prestonia core the BIOS informed about two CPUs; in case of two processors it informs of 4. The operating system identifies "both processors" without problems, but only if two conditions below are met. First of all, the CMOS Setup of the latest BIOS versions of the Supermicro P4DCxx board has item Enable Hyper-Threading; if it is disabled the OS identifies only physical processors. Secondly, the ACPI is used to inform the OS about additional logical processors. That is why to enable the Hyper-Threading the ACPI must be activated in the CMOS Setup, and the HAL (Hardware Abstraction Layer) with ACPI support must also be enabled for the OS. Fortunately, in the Windows 2000 it's easy to change the HAL from the Standard PC (or MPS Uni-/Multiprocessor PC) to ACPI Uni-/Multiprocessor PC by changing the "computer driver" in the device manager. At the same time, the only way in the Windows XP to switch to the ACPI HAL is to install the system over the current one. So, now our Windows 2000 Pro believes it works in the dual-processor system. And now let me clarify our aims:
To estimate performance we have taken a suit of applications used earlier for workstation systems. First off, lets compare "equality" of logical processors. First we carry out the test on one processor with the Hyper-Threading off, then repeat the test with the Hyper-Threading on using only one of two logical CPUs (with the help of the Task Manager). Because we are interested in the relative data the results are based on the principle "the more, the better" and normalized (the results of the uni-processor system with the Hyper-Threading off are taken as a unit). Well, with only one active thread the performance of each of two LPs is equal to the performance of the physical CPU without the Hyper-Threading support. The idle LP (both LP0 and LP1) is really disabled, and shared resources are given entirely to the active LP.
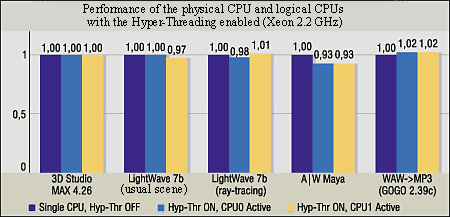 As we can see, two logical processors are equal indeed, and activation of the Hyper-Threading doesn't hamper operation of one thread. Now let's see whether this activation helps. Rendering. The results of 4 tests in the 3D modeling packets of 3D Studio MAX 4.26, Lightwave 7b and A|W Maya 4.0.1 are combined in one diagram because of their similarity.
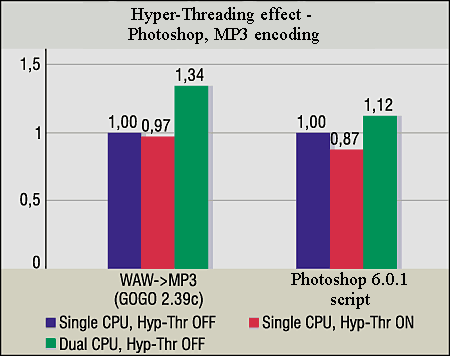
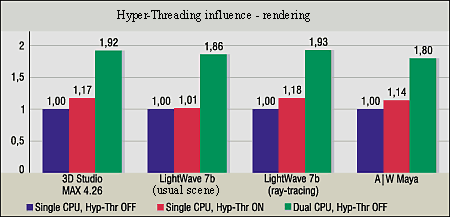 In all 4 cases (there are two different scenes for Lightwave) the CPU utilization with one thread and Hyper-Threading off is maintained at 100%. Nevertheless, when the Hyper-Threading is activated the scenes are calculated faster. In three tests the performance grows by 14-18% with the Hyper-Threading on; on the one hand, it's not much as compared with the second CPU, but on the other hand, it's quite good taking into account that the effect is free. In one of the Lightwave test the performance gain is alsmost zero. But there is no negative result anywhere. Besides, the parallel rendering processes implement similar work and, surely, they enable resources of the physical CPU not the best way. Photoshop and MP3 encoding. The GOGO-no-coda 2.39c is one of few codecs which support SMP, and it demonstrates 34% gain in case of SMP. At the same time there is no gain with the Hyper-Threading (just 3%). And in the Photoshop 6.0.1 (the script consists of a large number of instructions and filters) the performance decreased with the Hyper-Threading on, though the second physical CPU adds 12% in this case. This is the first case when the performance falls down with the Hyper-Threading...
 Professional OpenGL. It's known for a long time already that SPEC ViewPerf and many other OpenGL applications often slow down in SMP systems. OpenGL and dual-processing: why they don't get onWe saw a lot of times that dual-processor platforms in professional OpenGL tests had a noticeable advantage as compared with uni-processor ones very seldom. Besides, sometimes the second processor worsens the system performance in rendering of dynamic 3D scenes. Some testers prefer to avoid it, for example by publishing results of the SPEC ViewPerf benchmark only for dual-rocessor systems and ignoring uni-processor ones. Others make some fantastical assumptions on cache coherence, necessity to support it etc. But why should the processor control coherence exactly in case of OpenGL rendering (which doesn't differ much from other computational tasks as far as calculational issue is concerned). The explanation is, in fact, simpler. As you know, an application can be executed on two processors faster than on one if:
Now let's examine the OpenGL rendering implemented with two threads. If an application sees two processors and creates two threads of OpenGL rendering, each of them gets its own gl context, according to the OpenGL rules. And each thread implements rendering in its gl context. But the problem is that for the window where an image is drawn only one gl context can be current at each point of time. And the threads draw a generated image in the window in turn making their contexts current alternately. Well, such alternation of contexts can cost much. Below are some diagrams of some applications with OpenGL scenes working under two CPUs. All measurements were made on the following platform:
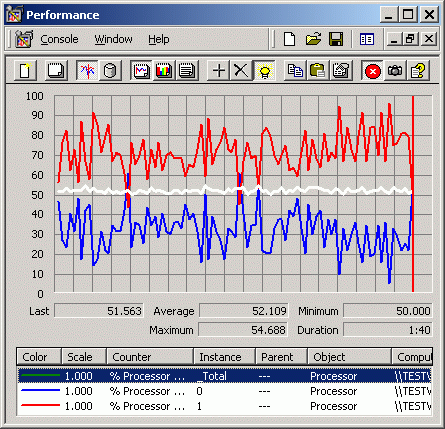
The Graph of CPU 0 usage is blue, and the graph of CPU 1 usage is red. The middle line is the final CPU Usage. Three graphs correspond to two scenes from 3D Studio MAX 4.26 and a part of the SPEC ViewPerf test (AWadvs-04).
 CPU Usage: 3D Studio MAX 4.26 animation - Anibal (with manipulators).max
 CPU Usage: 3D Studio MAX 4.26 animation - Rabbit.max
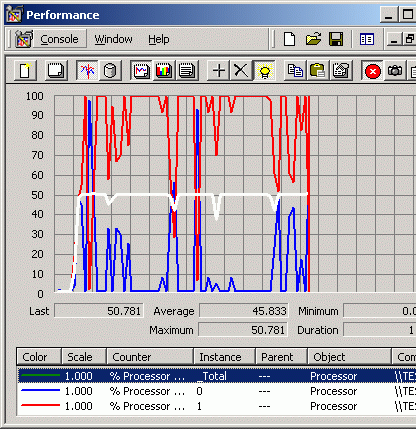 CPU Usage: SPEC ViewPerf 6.1.2 - AWadvs-04 The same situation occurs in many other applications where the overall CPU Usage is 50-60%. At the same time, for the uni-processor system the CPU Usage is stable 100%. That is why it's not surprising that there are a lot of OpenGL applications which do not speed up much in SMP systems. I can state that with two LPs the CPU performance decrease is greater because two logical processors impede each other like two physical ones. But their overall performance is lower, that is why with the Hyper-Threading the drop is more than in case two physical processors. The conclusion is that Hyper-Threading, like the real SMP, doesn't suit sometimes for OpenGL.
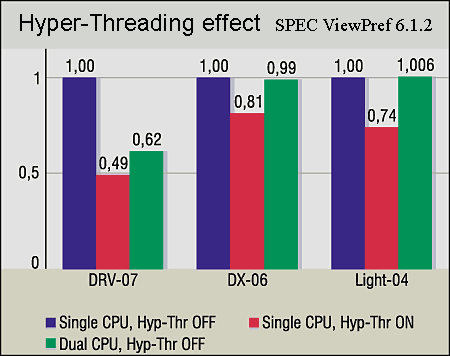 CAD applications. The previous conclusion is proved with results of two CAD tests -- SPECapc for SolidEdge V10 and SPECapc for SolidWorks. The graphics components of these tests for Hyper-Threading are similar (though the result is a little better for the SMP system for SolidEdge V10). The results of the CPU_Score benchmark is not simple to explain: 5--10% gain with SMP and 14--19% drop with Hyper-Threading.
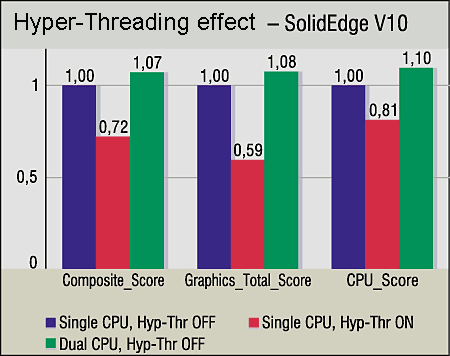
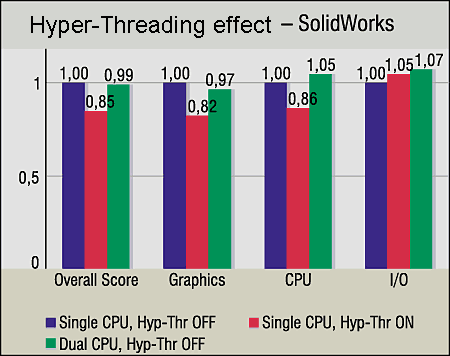 In the end, Intel admits that in some cases the performance can fall with the Hyper-Threading enabled, for example, in case of empty wait cycles. We just can assume that this is the very reason (the detailed examination of the SolidEdge and SolidWorks code is not the aim of this article). You all know how conservative the developers of CAD applications are; they prefer realiability and do not hurry to rewrite codes with innovations in programming. Summing upThe Hyper-Threading does work. Of course, the technology is not universal as there are applications which feel bad with the Hyper-Threading, and if this technology is going to be popular such applications should be modified. But hasn't the same thing happened to MMX and SSE and is happening now to SSE2?.. However, a variant of a uni-processor system on the Xeon with the Hyper-Threading should be discarded (or it can take place just until the second processor is bought): even 30% gain doesn't justify the price - it's better take a usual Pentium 4. What remains is two CPUs and more. Now let's imagine we get a dual-processor on the Xeon (for example, with Windows 2000/XP Professional). Two CPUs are installed, Hyper-Threading is on, the BIOS finds 4 logical processors... And how many processors does the OS see? Just two, because it's not meant for more. It will be two physical processors and the system will work the same way as if the Hyper-Threading is off, -- not slower (two LPs will just stop) and not faster (we checked it in the tests). What's then? Should we install Advanced Server or .NET Server on our workstation? The system will find 4 LPs. But the server OS looks quite strange on a workstation. The only rational way is when our dual-processor Xeon systems works as a server. But it's doubtful whether it's worth using Hyper-Threading for dual workstations with certain OSs. Intel advocates the OS licensing not according to the number of logical processors but physical ones. The discussions are still going on, and much depends on whether we will see operating systems for workstations with 4-processor support. As for servers, there are no problems. For example, Windows 2000 Advanced Server installed on a dual-processor Xeon system with Hyper-Threading enabled will see 4 LPs and will work flawlessly on them. To estimate the effect of the Hyper-Threading in server systems we show the results of Intel Microprocessor Software Labs for dual-processor systems on the Xeon MP and several server applications of Microsoft.
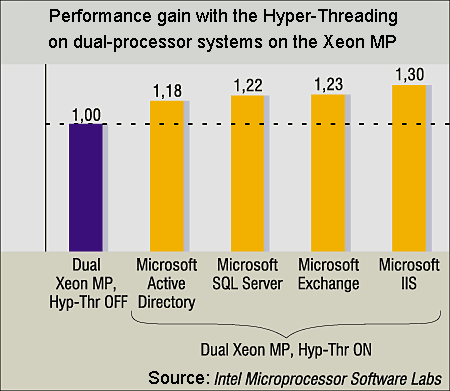 20-30% gain obtained free for a dual-processor server looks very attractive (especially compared with a real 4-processor system). As it turned out, at present the Hyper-Threading is useful only in servers.
Usage in workstations depends on a decision of the OS licensing. However,
there is one more aspect of utilization of the Hyper-Threading, if only
desktop processors get its support. For example, take a Pentium 4 based
system with Hyper-Threading and working under the Windows 2000/XP Professional
with SMP support... There is nothing unbelievable: the Intel developers
promise all-round application of the Hyper-Threading -- from servers to
desktop and mobile systems.
Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. |














