 |
||
|
||
| ||
|
||
|
||
| ||
Good
or nothing about the dead. In this article we shall kindly recollect unreleased products of the 3dfx company that has suddenly left the 3D-market. First of all, let's talk about the long-suffering Rampage, as this name has appeared in the Internet a long time ago. The sad fate of dying unreleased overtook all 3dfx's uncompleted developments. Nevertheless we have a chance (though very small, first of all due to reasons of prestige) to see the remains of 3dfx's ideas in the future products of NVIDIA, since all 3dfx's legacy has been purchased by NVIDIA Corp. However, the latest developments of 3dfx are undoubtedly worthy of our notice. On the moment of trademarks and the intellectual property purchase by NVIDIA, 3dfx has been developing (in order of planned appearance) the following products:
Forever preliminaryLet's talk about Rampage+Sage combination. We have the maximum information content about these chips, furthermore on the moment of 3dfx sale they have already been realized in silicon. Actually, Spectre has been ready for final testing and then and for mass production. We are many, he's the only...With persistence, worthy of filing in the annals, 3dfx holds on to the multichip architecture. First, the filing speed of accelerators is scaled by increasing the number of rasterizer chips. This time the geometrical processor is also realized as the separate chip. This is quite logical:
The application of rasterizer chips with their own memory buses will increase its effective bandwidth. But any pro has its contra. First of all it's the high price of the multichip accelerator. Another thing is that we are forced to duplicate textures in the local chip memory. These are well-known aspects. And here's a new one - it is not clear where to store geometry. It's too prodigal to make another local geometrical buffer for Sage. Then we should:
The last point is more difficult to realize and it spoils rasterizer's work, forcing them down, taking away a part of the volume and reducing the efficiency of local memory bandwidth. It's not authentically known how the caching was organized, but we precisely know that the major part of geometry is stored in the system memory and is accessed via AGP. The frame buffer is distributed between local rasterizer buffers, with each of them responsible for the set of horizontal segments (as well as for VSA-100) that allows to cache memory calls more productively rather than in case of sharing the single baselines (the original SLI technology in Voodoo1/2). Here's the interaction scheme: 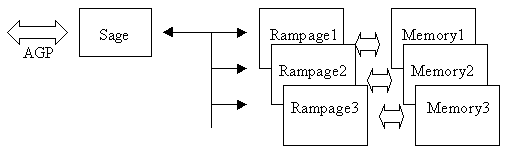 Up to 4 chips can combine and work together without any additional bridges and even without Sage. The physical organization of Rampage chips memory operations: 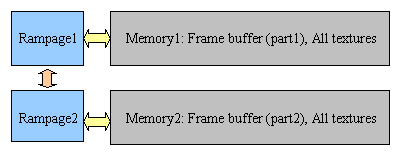 Chips communicate via special AGP-like bus, therefore the logical organization of memory operation looks like this: 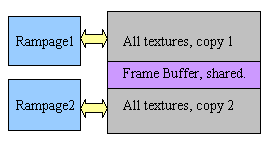 But the bandwidth is doubled, thus so do textures. The texture computerNow let's take a look at base specifications:
Again four pixel pipelines provide filling up to four triangle points per tick as well as for GeForce3,. However, Rampage has only one texture block for each pipeline available. But we shall not hurry with conclusions as TMUs may differ, and if one TMU provides complete trilinear filtering per tick, the memory bandwidth required for it will equal the one of two bilinear. And Rampage units are capable of filtering a trilinear texture per tick. They are also capable pf applying more complex types of filtering (up to 128-tap adaptive anisotropic) certainly paying for it with productivity:
The approach to texture combination is rather original (however GeForce3 has some rudiments of the similar approach as well, but nevertheless it has two parallel TMUs to get advantage in case of bilinear filtering). The textures in Rampage can be calculated sequentially up to 8 times, each with usage of an own filtering type (from primitive dot filtering up to adaptive anisotropic with 128-tap upper threshold). Certainly there is a flexible mechanism of calculated values combination. Actually up to 8 RGBASTW values (color, transparency, 3 texture coordinates) are calculated and saved. Thus the resulting dot color can be calculated, using all these parameters with the help of some flexible scheme. But that's not all. Previous texture values can be used up to 4 times for definition of relative or absolute texture coordinates calculated further at the following stages. As a result it is possible to realize various offset-based effects (EMBM, for example) as well as many other, and even to use so-called procedure texturing when texture is defined by a certain formula according to which the values in different dots can be calculated. The offset can be scaled by the value in the degree of 2: TextureCoord=CalculatedCoord+Displacement<<shift The complexity of expression, calculated for 8 combinative stages, is rather great - up to 8 different operations are allowed between 8 textures and interpolated values of attributes from vertexes of a triangle being painted. For example, it is possible to program this formula: Pixel = (((A+B) * (C+D)) *E+F) * (G*H) /2 Watching the latest developments in the field of 3D-graphics you might have noticed that there's a tendency of transition from parallel calculations (using several TMUs) with the subsequent fixed combination producing a result per tick, to sequential calculations of arbitrary number of textures in one block with a flexible combination based on the shader. Rampage supports not only pixel shaders of version 1.0, but also various additional features not present in it. And the flexibility of its texture states is much higher than that of GeForce3. As we have already said, saving values of both texture coordinates and depth, and the possibility of engaging them into final dot calculations allows to realize procedure and combined textures calculated on the basis of certain, though restricted, mathematical expression. For example: Alpha = (CS+CT) *Const Pixel=A(RGB)*Alpha + B(RGB) * (1-Alpha) S and T are the coordinates on the texture surface. It is possible to use values and their modifications (X, -X, 1-X, X-0.5) everywhere. Moreover, there is a possibility of conventional choice like this: Pixel = (A(A)+B(A))? C(RGB):D(RGB) The "intercolor" (R+G+B) combinations necessary for scalar or vector*matrix (DotProduct) calculations are also supported. They are used in different models of pixel lighting that are so well demonstrated by various technological demos for GeForce3. But that's not the end again. All intermediate color and transparency values are not only calculated, but also saved with 13-bit accuracy (signed 12 bits). That allows to avoid very dark scenes due to wider dynamic range and to receive qualitative resulting image even in case of 8-texture combination. Due to such accuracy of storage and processing of intermediate color values (56 bits/color), the luminance of vertex lighting being the sum of all light sources, can vary in 0-16.0 range, instead of 0-1.0 (0..4095 instead of 0..255 in the integer representation). That allows to realize the so-called OverBright Lighting. The open-air scenes with different bright light sources, especially with the sun, look much more realistic. It is possible to multiply values by any degree of 2 (to shift for the arbitrary number of bits) on each step without perfomance losses: Pixel = (A(RGB) < < 2) * (B(RGB) < < 3) The texture chroma keying, allowing to decide what texture values to take into account and what to consider nonexistent (completely transparent) is supported. And it's possible to define both the exact key value (e.g. 0, 13 or 255) and the range. This feature can always be realized via textures with transparency, but the similar approach saves the memory and allows to program some effects more naturally. I.e. essentially saves shader commands that are limited in number. It's possible to do three things with values that meet key condition. To exchange them with black (0 value), to exchange them with any given constant or to take a certain fixed percent from them (to scale). The main question appearing at the first sight on rasterizer parameters is "why so many textures?". The answer is simple - similar numbers will allow to realize more precise physical analogs of surface lighting, calculating precise values for each dot instead of approximating them on a triangle surface. For example, we can easily calculate (physically fair enough) hardware model (in this or that sort frequently used in software renders of realistic 3D-graphics) with pixel accuracy: Pixel=AmbientK*AmbientLightColor*AmbientTextureColor + DiffuseK* DiffuseTextureColor*Sum(DiffuseLightmapTextureColor[n], n) + SpecularK*SpecularTextureColor*Sum(SpecularLightmapTextureColor[n] < < SpecularPower, n) In case of 3 light sources we can esteem this after one pass! That will give us surface quality on a picture comparable to realtime software rendering of average complexity. If we take into account only 2 light sources, we'll be able to use another couple of freed textures, for reflection maps, for example. To add relief/refraction to this surface (probably different for diffuse and speck components) or to apply a refraction map (this area is not advanced yet, but I have suspicions that such concepts will shortly appear in hardware 3D-graphics). Yes, the nearest years will undoubtedly pass in the atmosphere of rising image realism. Doom3 creators as well as new chips specifications say the same. The situation with T-Buffer remains the same, its support completely meets VSA-100. But there are news a few words about multisampling. Rampage supports the so-called M-Buffer and the MultiSampling AA mode that saves texture time. As well as in GeForce3 one texture color value is used for effective edge antialiasing for two or four times in different positions. Public load geometryNow let's take a look at the Sage geometrical processor and AGP bridge. The functionality of the bridge will allow to use 2- and 4-chip cards on its base in the AGP mode (even under Windows 2000). The external geometrical processor is a rather contradictory thing. We have already spoken about the unclear way of Sage to cache geometry. But there is one more question: does it really provide complete AGP functionality or rasterizers are not capable of realizing AGP texturing again? Though, it is actually used infrequently nowadays... One more problem arises when speaking about numbers. Bandwidth of Rampage's installation block is 20 millions triangles. The maximum is 25 millions with tweaked up to 250 MHz clock rate. And Sage according the specifications is capable of processing the maximum of 50 millions triangles. Yes, some of them will be discarded (back-face oriented triangles) during processing and not transmitted to Rampage. But their number is obviously less than 50% on the average game scene. Therefore the geometrical power of accelerators based on this couple is limited first of all due to rasterizer chips. However, these 20-30 millions of Sage's theoretical triangles coincide very well with actual GeForce3 perfomance. And separate 3dfx's implementation and its good old "truly" attitude to declared numbers would allow to hope about comparable geometrical perfomance in the actual tests and applications. Sage supports version 1.0 vertex shaders (but its efficiency is unknown), provides all features of lighting calculations and texture coordinates generation. Sage (as well as GeForce3) is capable of hardware tesselating the rectangular and triangular patches (smooth surfaces). 50 millions (20 without discarded) triangles is quite a sufficient value, the question is if Sage is able to prove it in actual tests. By the way, in case of smooth surfaces usage the number of discarded triangles is increased. Also the 50:25 ratio is quite justified. Cards and stock and smoking barrelsThree cards have been planned on the basis of Rampage and Sage couple. 1 RampageInexpensive card with software-calculated geometry. This card is comparable with "complete" GeForce2, but is slower than GeForce3, especially in up-to-date games. But one should remember that the absence of HW T&L could have spoiled the situation in some future games. Anyway it's a budget card. 1 Rampage + 1 SageA variant for masses. Faster than GeForce2 and probably a bit slower than GeForce3. But in case of number of texture combinations exceeding four it can essentially outrun GeForce3 while it'll have to realize another pass. 2 Rampage + 1 SageAn expensive variant outrunning GeForce3 in terms of perfomance and, almost for sure, in price. The only weak place are tests of triangle bandwidth limits, but that's no very serious. Games with 50 millions polygons per second will hardly appear and spread during the lifetime of this card. These numbers are still related to synthetic tests. All cards would have been released under the "Spectre" title (and the model number). The price is unknown, it could have strongly depended on the memory price and the percent of valid chips released. What's nextTwo other products have been planned to appear next. Fear line - the continuation of Spectre. Almost the same Sage with increased perfomance and Fusion the advanced (in quantitative terms) variant of Rampage. Nothing technologically new, just evolutionary development - higher frequencies, more pipelines. But that's not all. Mojo, the essentially new tiled solution, must have been appeared some time later. 3dfx had its reasons to purchase Gigapixel technologies. Mojo was to feature some essential innovations the implementation of some type of hardware filtering when each tile of the screen buffer stores not only dot colors, but also the information about primitives that touch it (binning architecture). I.e. triangles sent to the accelerator would be hardware-sorted directly on fly at the expense of their owner tiles definition. Besides, Mojo was to feature the 16-bit floating format for color components calculation and storage. It could produce very precise 64-bit floating colors as well as the broadest dynamic range. And maybe even something else, who knows The future is probably for tiled architectures, and the following NVIDIA products (30-40 series) will undoubtedly incorporate some key concepts from Mojo. The requiemNow that's all. Let's play Quake1 for some time to honour the memory of 3dfx, that have showed us the way to the mass 3D hardware. Write a comment below. No registration needed!
|
Platform · Video · Multimedia · Mobile · Other || About us & Privacy policy · Twitter · Facebook Copyright © Byrds Research & Publishing, Ltd., 1997–2011. All rights reserved. |














